Online Learning算法理论与实践
Online Learning是工业界比较常用的机器学习算法,在很多场景下都能有很好的效果。本文主要介绍Online Learning的基本原理和两种常用的Online Learning算法:FTRL(Follow The Regularized Leader)[1]和BPR(Bayesian Probit Regression)[2],以及Online Learning在美团移动端推荐重排序的应用。
什么是Online Learning
准确地说,Online Learning并不是一种模型,而是一种模型的训练方法,Online Learning能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。Online Learning的流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环的系统。如下图所示:
Online Learning有点像自动控制系统,但又不尽相同,二者的区别是:Online Learning的优化目标是整体的损失函数最小化,而自动控制系统要求最终结果与期望值的偏差最小。
传统的训练方法,模型上线后,更新的周期会比较长(一般是一天,效率高的时候为一小时),这种模型上线后,一般是静态的(一段时间内不会改变),不会与线上的状况有任何互动,假设预测错了,只能在下一次更新的时候完成更正。Online Learning训练方法不同,会根据线上预测的结果动态调整模型。如果模型预测错误,会及时做出修正。因此,Online Learning能够更加及时地反映线上变化。
Online Learning的优化目标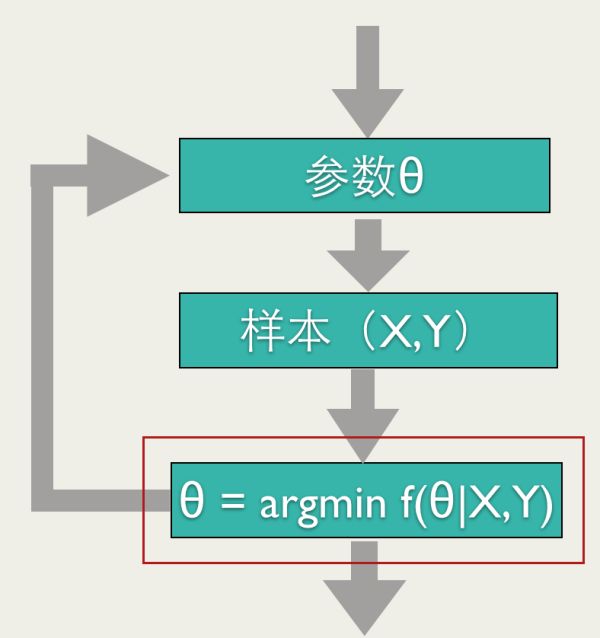
如上图所示,Online Learning训练过程也需要优化一个目标函数(红框标注的),但是和其他的训练方法不同,Online Learning要求快速求出目标函数的最优解,最好是能有解析解。
怎样实现Online Learning
前面说到Online Learning要求快速求出目标函数的最优解。要满足这个要求,一般的做法有两种:Bayesian Online Learning和Follow The Regularized Leader。下面就详细介绍这两种做法的思路。
Bayesian Online Learning贝叶斯方法能够比较自然地导出Online Learning的训练方法:给定参数先验,根据反馈计算后验,将其作为下一次预测的先验,然后再根据反馈计算后验,如此进行下去,就是一个Online Learning的过程,如下图所示。
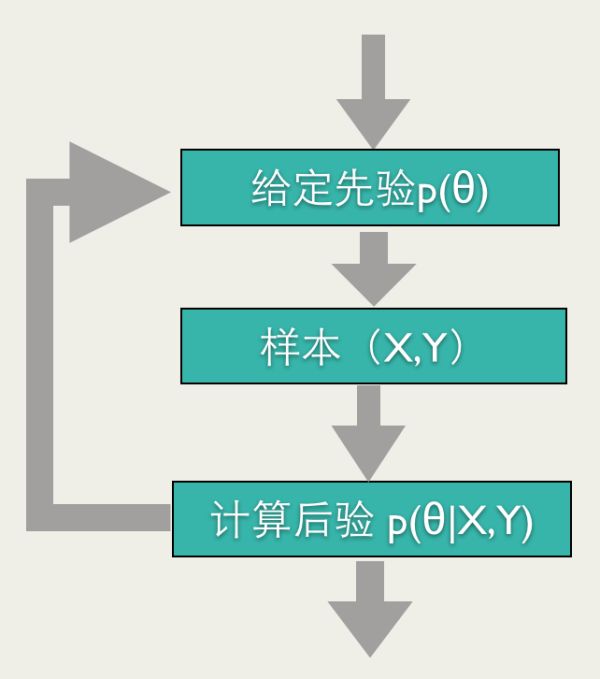
举个例子, 我们做一个抛硬币实验,估算硬币正面的概率μμ。我们假设μμ的先验满足
对于观测值Y=1Y=1,代表是正面,我们可以算的后验:
p(μ|Y=1)=Beta(α+1,β)p(μ|Y=1)=Beta(α+1,β)
对于观测值Y=0Y=0,代表是反面,我们可以算的后验:
p(μ∣∣Y=0)=Beta(α,β+1)p(μ|Y=0)=Beta(α,β+1)
按照上面的Bayesian Online Learning流程,我们可以得到估算μμ的Online Learning算法:
初始化 αα,ββ
for i = 0 ... n如果 YiYi是正面
α=α+1α=α+1
如果 YiYi是反面
β=β+1β=β+1
最终: μ∼Beta(α,β)μ∼Beta(α,β),可以取μμ的期望,μ=αα+βμ=αα+β
假设抛了NN次硬币,正面出现HH次,反面出现TT次,按照上面的算法,可以算得:
和最大化似然函数:
log[p(μ∣α,β)⋅p(Y=1∣μ)H⋅p(Y=0∣μ)T]log[p(μ∣α,β)⋅p(Y=1∣μ)H⋅p(Y=0∣μ)T]
得到的解是一样的。
上面的例子是针对离散分布的,我们可以再看一个连续分布的例子。
有一种测量仪器,测量的方差σ2σ2是已知的, 测量结果为:Y1,Y2,Y3,...,YnY1,Y2,Y3,...,Yn, 求真实值μμ的分布。
仪器的方差是σ2σ2, 所以观测值Y满足高斯分布:
观测到 Y1,Y2,Y3,...,YnY1,Y2,Y3,...,Yn, 估计参数 μμ 。
假设参数 μμ 满足高斯分布:
p(μ)=N(μ∣m,v2)p(μ)=N(μ∣m,v2)
观测到YiYi, 可以计算的后验:
p(μ∣Yi)=N(μ∣Yiv2+mσ2σ2+v2,σ2v2σ2+v2)p(μ∣Yi)=N(μ∣Yiv2+mσ2σ2+v2,σ2v2σ2+v2)
可以得到以下的Online Learning算法:
初始化 mm,v2v2
for i = 0 ... n观测值为YiYi
m=Yiv2+mσ2σ2+v2m=Yiv2+mσ2σ2+v2
更新
v2=σ2v2σ2+v2v2=σ2v2σ2+v2
上面的两个结果都是后验跟先验是同一分布的(一般取共轭先验,就会有这样的效果),这个后验很自然的作为后面参数估计的先验。假设后验分布和先验不一样,我们该怎么办呢?
举个例子:假设上面的测量仪器只能观测到YY,是大于0,还是小于0,即Yi∈{−1,1}Yi∈{−1,1},Yi=−1Yi=−1,代表观测值小于0,Yi=1Yi=1代表观测值大于0。
此时,我们仍然可以计算后验分布:
p(μ∣Yi=−1)=I(μ<0)p(μ)∫0−∞p(μ)dup(μ∣Yi=−1)=I(μ<0)p(μ)∫−∞0p(μ)du
但是后验分布显然不是高斯分布(是截断高斯分布),这种情况下,我们可以用和上面分布KL距离最近的高斯分布代替。
观测到Yi=1Yi=1
KL(p(μ∣Yi=1)||N(μ∣m̃ ,ṽ 2))KL(p(μ∣Yi=1)||N(μ∣m~,v~2))
可以求得:
m̃ =m+v⋅υ(mv)m~=m+v⋅υ(mv)
ṽ 2=v2(1−ω(mv))v~2=v2(1−ω(mv))
观测到Yi=−1Yi=−1
可以求得:
m̃ =m−v⋅υ(−mv)m~=m−v⋅υ(−mv)
ṽ 2=v2(1−ω(−mv))v~2=v2(1−ω(−mv))
两者综合起来,可以求得:
ṽ 2=v2(1−ω(Yimv))v~2=v2(1−ω(Yimv))
其中:
υ(t)=ϕ(t)Φ(t)υ(t)=ϕ(t)Φ(t)
ϕ(t)=12πexp(−12t2)ϕ(t)=12πexp(−12t2)
Φ(t)=∫t−∞ϕ(t)dtΦ(t)=∫−∞tϕ(t)dt
ω(t)=υ(t)∗(t−υ(t))ω(t)=υ(t)∗(t−υ(t))
有了后验我们可以得到Online Bayesian Learning流程:
初始化 mm,v2v2
for i = 0 ... n观测值为YiYi
m=m+Yi⋅v⋅υ(Yi⋅mv)m=m+Yi⋅v⋅υ(Yi⋅mv)
更新
v2=v2(1−ω(Yi⋅mv))v2=v2(1−ω(Yi⋅mv))
Bayesian Online Learning最常见的应用就是BPR(Bayesian Probit Regression)。
BPR在看Online BPR前,我们先了解以下Linear Gaussian System(具体可以参考[3]的4.4节)。
xx是满足多维高斯分布:
yy是xx通过线性变换加入随机扰动ΣyΣy得到的变量:
p(y∣x)=N(y∣Ax+b,Σy)p(y∣x)=N(y∣Ax+b,Σy)
已知xx,我们可以得到yy的分布:
p(y)=N(y∣AμX+b,Σy+AΣxAT)p(y)=N(y∣AμX+b,Σy+AΣxAT)上面这个结论的具体的推导过程可以参考[3]的4.4节,这里我们直接拿来用。
我们可以假设特征权重 ww 满足独立高斯分布,即
p(w)=N(w∣μ,Σ)p(w)=N(w∣μ,Σ):
μ=[μ1,μ2,...,μD]Tμ=[μ1,μ2,...,μD]T
Σ=⎡⎣⎢⎢⎢⎢⎢σ210⋮00σ22⋮0……⋱…00⋮σ2D⎤⎦⎥⎥⎥⎥⎥Σ=[σ120…00σ22…0⋮⋮⋱⋮00…σD2]
YY是一维变量,是ww与特征向量xx的内积,加入方差为β2β2的扰动:
p(y∣w)=N(y∣xTw,β2)p(y∣w)=N(y∣xTw,β2)根据上面的式子可以得出:
p(y∣w)=N(y∣xTμ,xTΣx+β2)p(y∣w)=N(y∣xTμ,xTΣx+β2)
由于我们只能观测到YY,是大于0,还是小于0,即Yi∈{−1,1}Yi∈{−1,1},Yi=−1Yi=−1,代表观测值小于0,Yi=1Yi=1代表观测值大于0。
对于观测值,我们可以先用KL距离近似yy的分布,我们可以算出后验:
m̃ =xTμ+Yiυ(Yi⋅xTμxTΣx+β2‾‾‾‾‾‾‾‾‾‾√)m~=xTμ+Yiυ(Yi⋅xTμxTΣx+β2)
ṽ 2=(xTΣx+β2)(1−ω(Yi⋅xTμxTΣx+β2‾‾‾‾‾‾‾‾‾‾√))v~2=(xTΣx+β2)(1−ω(Yi⋅xTμxTΣx+β2))
有了yy的近似分布,我们可以计算出后验:
p(w∣y)∝p(y∣w)p(w)p(w∣y)∝p(y∣w)p(w)
可以求得:
μ̃ d=μd+Yixi,d⋅σ2dxTΣx+β2‾‾‾‾‾‾‾‾‾‾√⋅υ(Yi⋅xTμxTΣx+β2‾‾‾‾‾‾‾‾‾‾√)μ~d=μd+Yixi,d⋅σd2xTΣx+β2⋅υ(Yi⋅xTμxTΣx+β2)
σ̃ d=σd⋅[1−xi,d⋅σ2dxTΣx+β2ω(Yi⋅xTμxTΣx+β2‾‾‾‾‾‾‾‾‾‾√)]σ~d=σd⋅[1−xi,d⋅σd2xTΣx+β2ω(Yi⋅xTμxTΣx+β2)]
Online Bayesian Probit Regression 训练流程如下:
FTRL初始化 μ1μ1,σ21σ12, μ2μ2,σ22σ22 , ... , μDμD,σ2DσD2
for i = 1 ... n观测值为YiYi
μd=μd+Yixi,d⋅σ2dxTiΣxi+β2‾‾‾‾‾‾‾‾‾‾√⋅υ⎛⎝⎜⎜⎜Yi⋅xTiμxTiΣxi+β2‾‾‾‾‾‾‾‾‾‾√⎞⎠⎟⎟⎟μd=μd+Yixi,d⋅σd2xiTΣxi+β2⋅υ(Yi⋅xiTμxiTΣxi+β2)
for d = 1 ... D
更新
σd=σd⋅⎡⎣⎢⎢⎢1−xi,d⋅σ2dxTiΣxi+β2ω⎛⎝⎜⎜⎜Yi⋅xTiμxTiΣx+β2‾‾‾‾‾‾‾‾‾‾√⎞⎠⎟⎟⎟⎤⎦⎥⎥⎥σd=σd⋅[1−xi,d⋅σd2xiTΣxi+β2ω(Yi⋅xiTμxiTΣx+β2)]
除了Online Bayesian Learning,还有一种做法就是FTRL(Follow The Regularized Leader)。
FTRL的网上资料很多,但是大部分介绍怎么样产生稀疏化解,而往往忽略了FTRL的基本原理。顾名思义,FTRL和稀疏化并没有关系,它只是一种做Online Learning的思想。
先说说FTL(Follow The Leader)算法,FTL思想就是每次找到让之前所有损失函数之和最小的参数。流程如下:
初始化 ww
for t = 1 ... n损失函数 ftft
w=argminw∑i=1tfi(w)w=argminw∑i=1tfi(w)
更新
FTRL算法就是在FTL的优化目标的基础上,加入了正规化,防止过拟合:
其中,R(w)R(w)是正规化项。
FTRL算法的损失函数,一般也不是能够很快求解的,这种情况下,一般需要找一个代理的损失函数。
代理损失函数需要满足几个要求:
- 代理损失函数比较容易求解,最好是有解析解
- 优化代理损失函数求的解,和优化原函数得到的解差距不能太大
为了衡量条件2中的两个解的差距,这里需要引入regret的概念。
假设每一步用的代理函数是ht(w)ht(w)
每次取
Regrett=∑t=1Tft(wt)−∑t=1Tft(w∗)Regrett=∑t=1Tft(wt)−∑t=1Tft(w∗)
其中w∗=argminw∑ti=1fi(w)w∗=argminw∑i=1tfi(w),是原函数的最优解。就是我们每次代理函数求出解,离真正损失函数求出解的损失差距。当然这个损失必须满足一定的条件,Online Learning才可以有效,就是:
limt→∞Regrettt=0limt→∞Regrettt=0随着训练样本的增多,这两个优化目标优化出的参数的实际损失值差距越来越小。
代理函数 ht(w)ht(w) 应该该怎么选呢?
如果ft(w)ft(w) 是凸函数,我们可以用下面的代理损失函数:
其中gigi 是fi(wi)fi(wi)次梯度(如果 fi(wi)fi(wi)是可导的,次梯度就是梯度)。ηtηt满足:
为了产生稀疏的效果,我们也可以加入l1正规化:
ht=∑i=1tgi⋅w+∑i=1t(12ηt−12ηt−1)||w−wt||2+λ1|w|ht=∑i=1tgi⋅w+∑i=1t(12ηt−12ηt−1)||w−wt||2+λ1|w|只要ft(w)ft(w) 是凸函数,上面的代理函数一定满足:
limt→∞Regrettt=0limt→∞Regrettt=0
上面的式子我们可以得出ww的解析解:
wt+1,i={0−ηt(zt,i−sgn(zt,i)λ1))|zt,i|<λ1otherwisewt+1,i={0|zt,i|<λ1−ηt(zt,i−sgn(zt,i)λ1))otherwise其中
可以得到FTRL的更新流程如下:
输入αα, λ1λ1
初始化 w1...Nw1...N, z1..N=0z1..N=0 , n1..N=0n1..N=0
for t = 1 ... T损失函数 ftft
for i = 1 ..N计算
gt,i=∂fi(wt−1)wt−1,igt,i=∂fi(wt−1)wt−1,i
zt+=gt,i+1α(ni+g2t,i‾‾‾‾‾‾‾√−ni‾‾√)wt,izt+=gt,i+1α(ni+gt,i2−ni)wt,i
ni+=g2t,ini+=gt,i2
更新
wt+1,i={0−ηt(zt,i−sgn(zt,i)λ1))|zt,i|<λ1otherwisewt+1,i={0|zt,i|<λ1−ηt(zt,i−sgn(zt,i)λ1))otherwise
Online Learning实践
前面讲了Online Learning的基本原理,这里以移动端推荐重排序为例,介绍一下Online Learning在实际中的应用。
推荐重排序介绍
目前的推荐系统,主要采用了两层架构,首先是触发层,会根据上下文条件和用户的历史行为,触发用户可能感兴趣的item,然后由排序模型对触发的item排序,如下图所示:
推荐重排序既能融合不同触发策略,又能较大幅度提高推荐效果(我们这里主要是下单率)。在移动端,屏幕更加小,用户每次看到的item数目更加少,排序的作用更加突出。
美团重排序Online Learning架构
美团Online Learning架构如下图所示:
线上的展示日志,点击日志和下单日志会写入不同的Kafka流。读取Kafka流,以HBase为中间缓存,完成label match(下单和点击对映到相应的展示日志),在做label match的过成中,会对把同一个session的日志放在一起,方便后面做skip above:
训练数据生成
移动端推荐的数据跟PC端不同,移动端一次会加载很多item,但是无法保证这些item会被用户看到。为了保证数据的准确性,我们采用了skip above的办法,如下图所示:
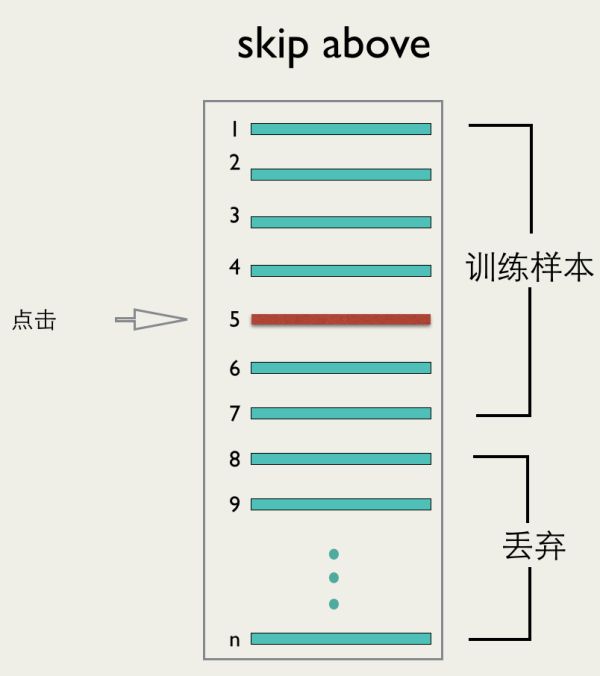
假设用户点击了第i个位置,我们保留从第1条到第i+2条数据作为训练数据,其他的丢弃。这样能够最大程度的保证训练样本中的数据是被用户看到的。
特征
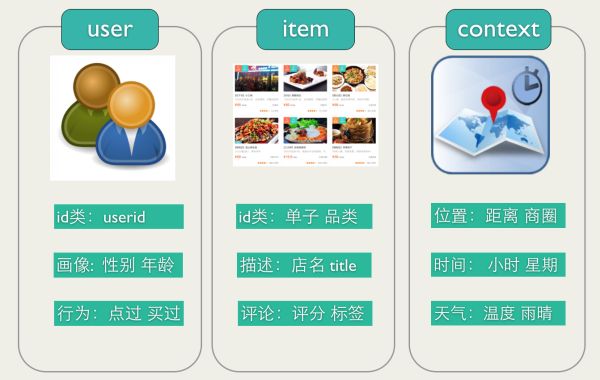
用的特征如下图所示:
算法选择
我们尝试了FTRL和BPR效果,线下实验效果如下表:
BPR的效果略好,但是我们线上选用了FTRL模型,主要原因是FTRL能够产生稀疏化的效果,训练出的模型会比较小。
模型训练
训练算法不断地从HBase中读取数据,完成模型地训练,训练模型放在Medis(美团内部地Redis)中,线上会用Medis中的模型预测下单率,根据预测的下单率,完成排序。
线上效果
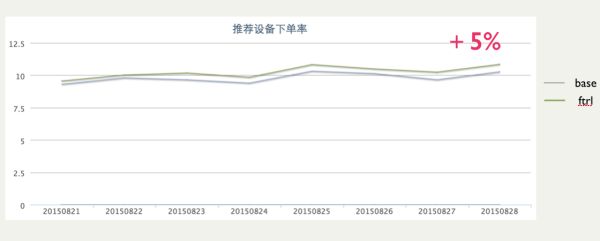
上线后,最终的效果如下图所示,和base算法相比,下单率提高了5%。
参考资料
- [1] McMahan H B, Holt G, Sculley D, et al. Ad Click Prediction: a View from the Trenches. Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). 2013.
- [2] Graepel T, Candela J Q, Borchert T,et al. Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft's Bing Search Engine. Proceedings of the 27th International Conference on Machine Learning ICML. 2010.
- [3] Murphy K P. Machine Learning: A Probabilistic Perspective. The MIT Press. 2012.