Haar 特征训练步骤详
一、准备样本阶段
事先准备好正样本和负样本。这里只是先用于做Haar特征训练步骤的熟悉用,所以用opencv写了个程序,主要是做图片的变形处理。如旋转和亮度调节等。当然最后检测的效果指定很不好,这里先作为步骤熟悉来用的。
我们首先取出一幅图片(以交通标志为例),可在网上下载,然后通过程序,在对这幅图片进行亮度调节和旋转后,得到700多张图片(图片格式设置为bmp或jpg)。我们取出其中的245幅图片作为本次的训练正样本。然后通过这个程序,有设置批量生成负样本的功能,总共从一张大图片中随机抠出700张负样本图片。这里,由于是事先用程序写好的,所以,正样本和负样本的大小均为50*50。
程序如下图所示:
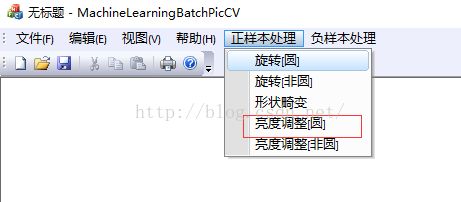
这是正负样本的程序截图,最后得到如下的结果:
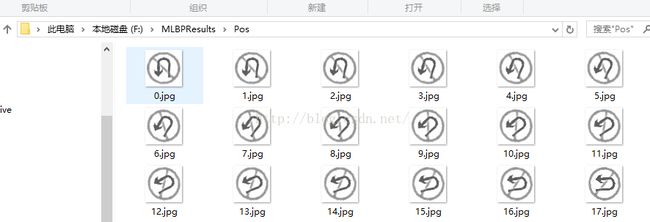
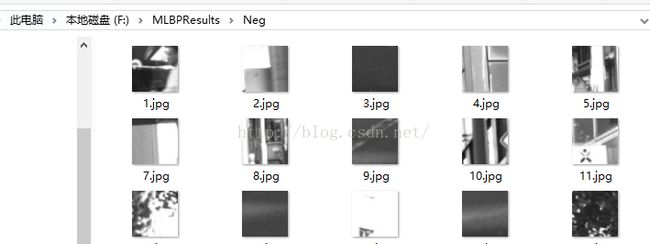
说明一下,根据网上查到的资料,这里最好用灰度图进行操作,所以最后生成的都是8位深度的灰度图。大小统一为50*50。
二、正负样本样本描述文件的制定
因为这里我们正样本是用程序自写的,所以不用直接在文档里改大小,而没有进行标定,实际上,我们需要用objectmaker进行标定,具体使用可自行上网查。
这里用到的是opencv自带的一个程序,叫做opencv_createsamples.exe,具体在opencv下的bin里。
把上面的pos和neg文件夹里的正负样本,还有opencv里opencv_createsamples.exe放到一个文件夹里,为了不出现cmd控制台里的文件名过长而读不出来的情况,尽可能精简文件路径,如:
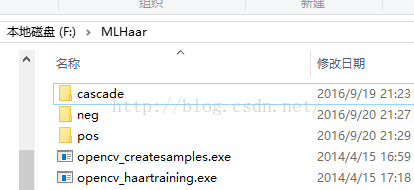
这样,直接在F盘下工作就好。
其中,pos文件夹里放置的是刚才生成的正样本图片,neg文件夹里放置的是刚才生成的负样本文件。
之后,就是进行样本描述文件的生成了。
PS:如果不能运行这两个exe,就把opencv里bin的dll全拷到这里,和exe位于同一级即可。
样本描述文件的生成,需要用到cmd命令提示符,首先,打开命令提示符。
按照如下图所示进入到该文件夹里(具体可百度,很简单,是cd命令)。
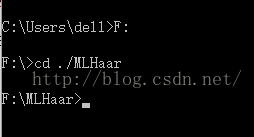
这里的样本描述文件,正样本需要的是一个.vec的文件,负样本需要的是一个.dat的文件。.vec文件可以通过.dat文件通过后面的操作来进行,这里先放一下。
我们先对这正负样本生成.dat文件的操作。
首先,对正样本进行。
先通过命令提示符,进入到pos文件夹。然后输入dir /b > sample_pos.dat,就可以生成一个.dat的文件。这个dir /b > sample_pos.dat命令的作用是把当前文件夹下所有图片名称写入到.dat里(当然txt也是可以的,这里直接生成.dat)。这个.dat的名称我们先设为sample_pos,当然,设为其他的名称也可以,不过,一旦设定,就不要改了,后面都会需要到这个名称的。

然后,同样的,对负样本进行同样的处理。最后在neg文件件里生成sample_neg.dat。
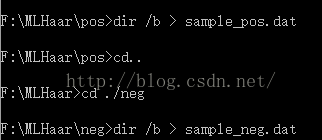
这时得到的.dat文件还不能用,因为是没有处理过的,我们还要对其进行处理。这里用到一个叫做editplus的工具。主要是对txt文件里的样本进行替换工作。
我们首先把刚才生成的正样本的.dat文件进行修改,点击.dat,右键用editplus打开,下把下方的用红框框住的地方删掉。
然后,把jpg改为jpg 1 0 0 50 50,全部更改,就进行了一个标定。
这里一定要注意!负样本也是把最下面两行删掉,但是,不要把jpg改为jpg 1 00 50 50,
一旦修改,就会出现Invalid background description file!错误。这里一定注意。
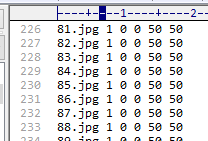
这样就好了,对正负样本的.dat就处理完成。
然后,是对正样本的.dat转化为.vec进行处理。
打开刚才的命令提示符。
输入opencv_createsamples.exe -info ./pos/sample_pos.dat -vec ./pos/sample_pos.vec -num 245 -w 20 -h 20
如下图所示:
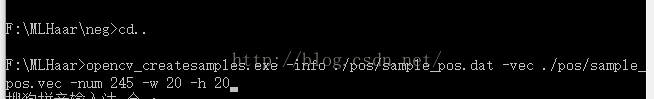
其中,各个变量的含义为:
参数说明:-info,指样本说明文件
-vec,样本描述文件的名字及路径
-num,总共几个样本,要注意,这里的样本数是指标定后的20x20的样本数,而不是大图的数目,其实就是样本说明文件第2列的所有数字累加 和。
-w -h 指明想让样本缩放到什么尺寸。这里的奥妙在于你不必另外去处理第1步中被矩形框出的图片的尺寸,因为这个参数帮你统一缩放!
-show 是否显示每个样本。样本少可以设为YES,要是样本多的话不要显式地设置,因为关窗口会关到你哭。原本这里说的是设成NO,不过,建议不要设置,这样就不会弹出了。
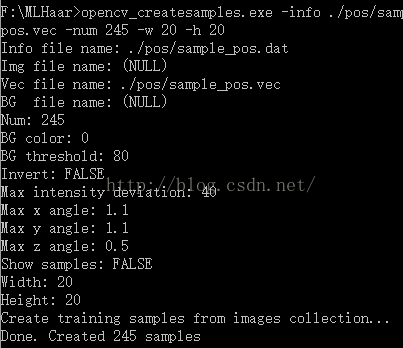
看到Done,就是已经对其处理好了,最后是得到.vec的文件。
负样本不用这样处理,直接用.dat文件就好。
以上,就是样本描述文件的生成过程。
三、进行训练分类器
用到的是opencv_haartraining.exe,该程序封装了haar特征提取以及adaboost分类器训练过程。也在opencv 的bin下面,就是上面的第一个截图,把这个exe放到和pos 的同一级目录就好。然后,新建一个文件夹,名字叫cascade,也是和pos位于目录的同一级。
Cmd,cd到当前目录,然后输入
opencv_haartraining.exe -data ./cascade -vec ./pos/sample_pos.vec -bg ./neg/sample_neg.dat -npos 245 -nneg 700 -mem 200 -mode ALL -w 20 -h 20
如图:
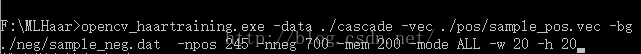
其中各个参数含义:
-data 指定生成的文件目录, -vec vec文件名, -bg 负样本描述文件名称,也就是负样本的说明文件(.dat) -nstage 20 指定训练层数,推荐15~20,层数越高,耗时越长。-nsplits 分裂子节点数目,选取默认值 2
-minhitrate 最小命中率,即训练目标准确度。-maxfalsealarm最大虚警(误检率),每一层训练到这个值小于0.5时训练结束,进入下一层训练,-npos 在每个阶段用来训练的正样本数目,-nneg在每个阶段用来训练的负样本数目 这个值可以设置大于真正的负样本图像数目,程序可以自动从负样本图像中切割出和正样本大小一致的,这个参数一半设置为正样本数目的1~3倍 -w -h样本尺寸,与前面对应 -mem 程序可使用的内存,这个设置为256即可,实际运行时根本就不怎么耗内存,以MB为单位 -mode ALL指定haar特征的种类,BASIC仅仅使用垂直特征,ALL表示使用垂直以及45度旋转特征
-sym或者-nonsym,后面不用跟其他参数,用于指定目标对象是否垂直对称,若你的对象是垂直对称的,比如脸,则垂直对称有利于提高训练速度
四、合并分类器生成.xml文件
蛮简单的,直接在cmd里,输入convert_cascade.exe --size="20x20"..\cascade haar_adaboost.xml 就可以了。
最后,出现cascade performance 就是成功了!
以上,就是haar训练特征的描述,希望对大家有帮助。
PS:不用.dat,直接用.txt也可以的
参考资料:http://www.cnblogs.com/wengzilin/p/3849118.html(注意,这两个有错误地方,我已经在文中进行了说明)
http://www.cnblogs.com/wengzilin/p/3845271.html
http://m.blog.csdn.net/article/details?id=5838389