开发十年,就只剩下这套Java开发体系了 >>> ![]()
第一步:安装opencv
进入opencv官网下载:https://opencv.org/opencv-3-4-1.html后,点击安装即可,并设置环境变量,根据自己windows安装vc版本14或15,设置opencv\build\x64\vc15\bin的环境变量。
第二步:准备文件
新建一个训练目录:F:\TensorFlow\tongue_trainer
将bin目录下的文件都拷贝到tongue_trainer文件夹中;
新建negdata,posdata,xml文件夹,分别用于存放负样本图片,正样本图片,和生成的模型文件。
第三步:样本文件处理:
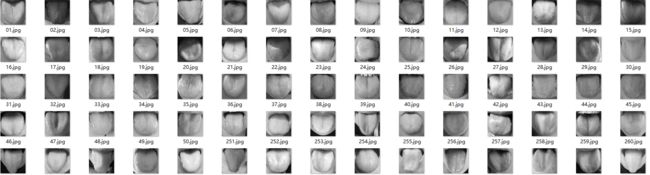
将正样本图片统一缩放到60*60 或者40*40,官方推荐是20*20,同时可以做灰度处理。
备注:正样本图片选择只包含舌头的图片!!!
def main(image_path,distinct_path):
count=0
if os.path.isdir(image_path):
for img_name in os.listdir(image_path):
img_path = image_path + img_name
count+=1
img = cv2.imread(img_path, 0) # img_name为字符串,要读取的图片的名字或者全路径;command可以为空,默认值为1;0 表示以灰度图方式读取图片;1 表示以彩色度方式读取图片
cv2.imshow('image', img) # 创建显示框并显示图片
# namedWindow(name, 1) # 只创建可调节显示框,需与imshow配合使用
#size = img.shape # 获取图片大小(长,宽,通道数)
tempimg = cv2.resize(img, (60,60), cv2.INTER_AREA)#缩放图片推荐选择INTER_AREA
#gray = cv2.cvtColor(tempimg, cv2.COLOR_BGR2GRAY)
# cv2.imshow('imag2', tempimg)
# 等待用户关闭显示框
#cv2.waitKey(0)
#cv2.destroyAllWindows()
cv2.imwrite(distinct_path+img_name, tempimg)负样本则只做灰度处理(可以同上面的代码处理,注掉缩小尺寸的代码即可),不缩小尺寸(负样本尺寸越大越好,同时负样本图片要丰富多样,可以包含些人脸但没有舌头的,室内的图片,形状等),比列正负比1:3左右。
第四步:正样本图片描述操作
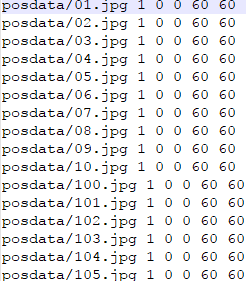
1.进入正样本posdata文件夹,新建pos.dat文件,写入dir /b/s/p/w *.jpg *.png > posdata.txt,然后执行pos.dat文件,生成posdata.txt.
2.使用文本编辑器的替换功能,做一些替换工作
替换1:将绝对路径替换成相对路径
替换2:1代表个数,后四个分别对应left top width height
1 0 0 60 60
补充:1代表特征个数,0 0 代表训练特征在图片中的坐标,60 60 表示特征的尺寸;
这里之所以正样本要用只包含舌头的图片,就跟这里的参数有关,如果你放一张脸中包含舌头的图片,那你就得手动标注舌头在该图片的坐标位置,这样工作量就很大。后面的特征参数就不能统一写成60*60了。所以推荐使用只有舌头的样本图片。
第五步:生成正样本向量描述文件
将posdata.txt复制到到训练根目录tongue_trainer,在该目录下执行如下cmd命令:
opencv_createsamples.exe -vec pos.vec -info posdata.txt -num 500 -w 60 -h 60得到正样本向量描述文件pos.vec。
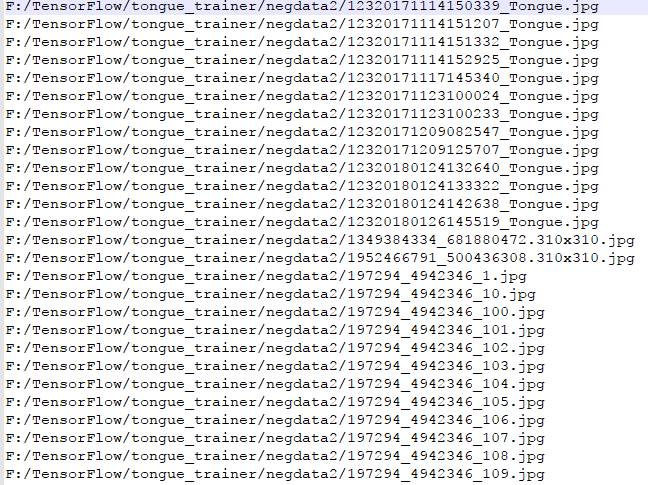
第五步:生成负样本图片路径文件
进入negdata目录,同样新疆neg.bat文件,输入dir /b/s/p/w *.jpg *.png > negdata.txt,然后执行neg.dat文件,生成negdata.txt.负样本不需要生成特征描述,直接将negdata.txt复制到训练目录tongue_trainer。
第六步:开始样本训练
新建文件traincascade.bat,写入:
opencv_traincascade.exe -data xml -vec pos.vec -bg negdata.txt -numPos 490 -numNeg 1360 -numStages 10 -featureType LBP-w 60 -h 60 -minHitRate 0.999 -maxFalseAlarmRate 0.2 -weightTrimRate 0.95
pause-numPos:使用正样本的80%-90%即可,不用全写上,因为有时候机器识别的时候可能造成有些图片识别不出就报错。
-numNeg 1360 负样本数量
-numStages 10 训练轮数
-featureType LBP 局部文理特征----默认为haar特征复制进去保存,然后执行traincascade.bat即可.
备注:之前的老版本都是使用opcnv_haartraining.exe训练,现在新版本都是使用opcnv_traincascade.exe来训练级联分类器。
假如程序执行报错的话,检查:
1.正样本图片尺寸是否统一,训练参数w,h是否为正样本尺寸大小。
2.负样本文件路径是否正确。
3.正样本数量是否过大 ,参数最好取正样本数量的80%-90%。
训练结束后会在xml文件夹中生成一个cascade.xml文件。
最后验证模型:单个图片验证
import numpy as np
import cv2
faceCascade = cv2.CascadeClassifier('Cascades/cascade_test8.xml')
img = cv2.imread("213.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.38,#该参数需要根据自己训练的模型进行调参
minNeighbors=4,#minNeighbors控制着误检测,默认值为3表明至少有3次重叠检测,我们才认为人脸确实存
minSize=(20,20),#寻找人脸的最小区域。设置这个参数过大,会以丢失小物体为代价减少计算量。
flags = cv2.IMREAD_GRAYSCALE
)
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
cv2.namedWindow('image', cv2.WINDOW_AUTOSIZE)
cv2.imshow('image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()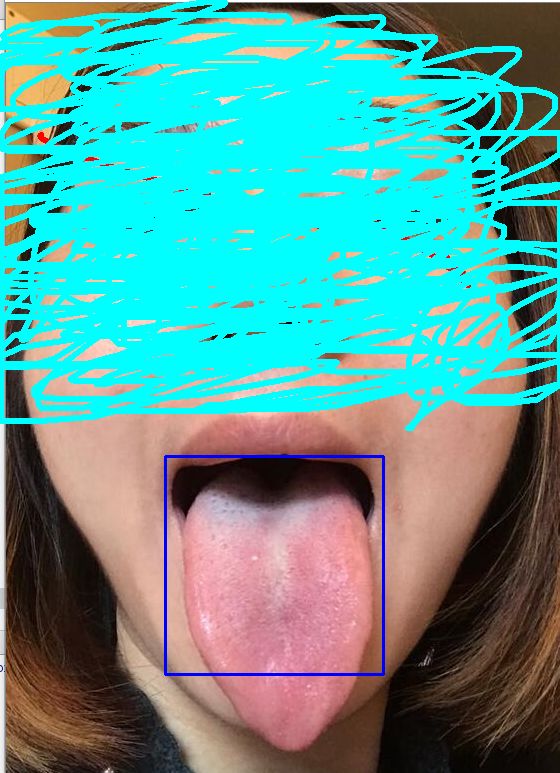

视屏实时监测代码:
import cv2
import time
#加载人脸分类器
faceCascade = cv2.CascadeClassifier('Cascades/cascade_test8.xml')
#调用摄像头
cap = cv2.VideoCapture(0)
#设置图片尺寸
cap.set(3, 640) # set Width
cap.set(4, 480) # set Height
#循环抓取图片
while True:
# 获取视频一帧图像
ret, img = cap.read()
# 将图像转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.38,
minNeighbors=4,
minSize=(20, 20)
)
count=0
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
count+=1
if(count==len(faces)):
cv2.imwrite('img/%s.png' % time.time(), img)
cv2.imshow('video', img)
k = cv2.waitKey(50) & 0xff#控制相机拍照间隔
if k == 27: # press 'ESC' to quit
break
模型训练后,有时候发现测试是没有圈出舌头,这个时候就需要对
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.38,
minNeighbors=4,
minSize=(20, 20)
)
里面的参数进行调整,scaleFactor和minNeighbors进行调节。
补充:各参数详解:
1. image为输入的灰度图像
2. objects为得到被检测物体的矩形框向量组
3. scaleFactor为每一个图像尺度中的尺度参数,默认值为1.1。scale_factor参数可以决定两个不同大小的窗口扫描之间有多大的跳跃,这个参数设置的大,则意味着计算会变快,但如果窗口错过了某个大小的人脸,则可能丢失物体。
4. minNeighbors参数为每一个级联矩形应该保留的邻近个数(没能理解这个参数,-_-|||),默认为3。minNeighbors控制着误检测,默认值为3表明至少有3次重叠检测,我们才认为人脸确实存。
5. flags对于新的分类器没有用(但目前的haar分类器都是旧版的,CV_HAAR_DO_CANNY_PRUNING,这个值告诉分类器跳过平滑(无边缘区域)。利用Canny边缘检测器来排除一些边缘很少或者很多的图像区域;CV_HAAR_SCALE_IMAGE,这个值告诉分类器不要缩放分类器。而是缩放图像(处理好内存和缓存的使用问题,这可以提高性能。)就是按比例正常检测;CV_HAAR_FIND_BIGGEST_OBJECTS,告诉分类器只返回最大的目标(这样返回的物体个数只可能是0或1)只检测最大的物,CV_HAAR_DO_ROUGH_SEARCH,他只可与CV_HAAR_FIND_BIGGEST_OBJECTS一起使用,这个标志告诉分类器在任何窗口,只要第一个候选者被发现则结束寻找(当然需要足够的相邻的区域来说明真正找到了。),只做初略检测.
6. minSize()指示寻找人脸的最小区域。设置这个参数过大,会以丢失小物体为代价减少计算量。
下面是一个文档中看到的描述,函数内部貌似和上边说的有点出入!
#Detects objects of different sizes in the input image.
# The detected objects are returned as a list of rectangles.
#cv2.CascadeClassifier.detectMultiScale(image, scaleFactor, minNeighbors, flags, minSize, maxSize)
#scaleFactor – Parameter specifying how much the image size is reduced at each image
#scale.
#minNeighbors – Parameter specifying how many neighbors each candidate rectangle should
#have to retain it.
#minSize – Minimum possible object size. Objects smaller than that are ignored.
#maxSize – Maximum possible object size. Objects larger than that are ignored.opencv_traincascade检测物体的分类器正负样本如何设置?
https://www.zhihu.com/question/26783512
opencv中文参考手册
http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html