Python数据爬虫学习笔记(21)Scrapy爬取当当图书数据并存储至SQLite数据库
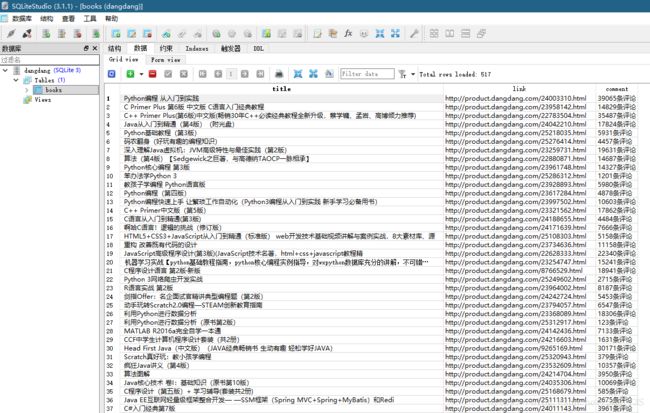
一、需求:在当当网的程序设计类图书商品界面中,爬取图书的名称、详情链接以及评论数,并将信息存储至SQLite数据库。

二、URL及网页源码分析:
1、URL分析,注意到商品搜索页的URL具有以下结构:
![]()
2、源码分析,观察网页的源代码,寻找商品名称、商品链接、评论数信息的所在位置。
1)商品名称:存在于class属性为pic的a标签中的title属性中。
![]()
2)商品链接:与商品名称类似,存在于存在于class属性为pic的a标签中的href属性中。
![]()
3)评论数信息:被name属性为itemlist-review的a标签所包围。
![]()
三、编写代码:
1、items.py:
import scrapy
class DangdangItem(scrapy.Item):
#爬取内容为图书名称、图书链接、图书评论数
title=scrapy.Field()
link=scrapy.Field()
comment=scrapy.Field()
2、settings.py:
# 必须解除遵守robots协议
ROBOTSTXT_OBEY = False
#启用pipelines.py来进行数据处理
ITEM_PIPELINES = {
'dangdang.pipelines.DangdangPipeline': 300,
}3、dd.py(笔者创建的爬虫文件):
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request
class DdSpider(scrapy.Spider):
name = 'dd'
allowed_domains = ['dangdang.com']
#设置起始URL为商品第一页
start_urls = ['http://category.dangdang.com/pg1-cp01.54.06.00.00.00.html']
def parse(self, response):
item=DangdangItem()
#设定爬取的XPath表达式
item["title"]=response.xpath("//a[@class='pic']/@title").extract()
item["link"] = response.xpath("//a[@class='pic']/@href").extract()
item["comment"] = response.xpath("//a[@name='itemlist-review']/text()").extract()
yield item
#设置爬取前10页
for i in range(2,11):
#构造商品URL
url="http://category.dangdang.com/pg"+str(i)+"-cp01.54.06.00.00.00.html"
yield Request(url,callback=self.parse)4、pipelines.py:
import sqlite3
class DangdangPipeline(object):
def process_item(self, item, spider):
#连接数据库并创建游标,本文中的dangdang.db为笔者自行创建的数据库文件,结构见本代码后的图片
conn = sqlite3.connect('E:/dangdang.db')
cursor=conn.cursor()
for i in range(0,len(item["title"])):
title=item["title"][i]
link=item["link"][i]
comment=item["comment"][i]
#构造SQL语句并通过游标执行
sql = "insert into books values('"+title+"','"+link+"','"+comment+"')"
cursor.execute(sql)
#注意必须要提交事件才能够使数据库修改操作生效
conn.commit()
#输出爬取的内容
print(title)
print(link)
print(comment)
#关闭游标以及数据库连接
cursor.close()
conn.close()
return item本文创建的SQLite数据库结构:
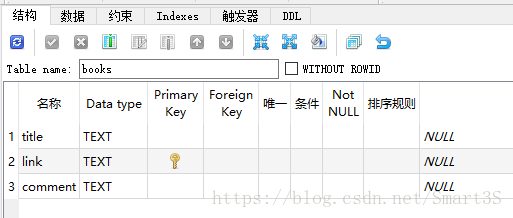
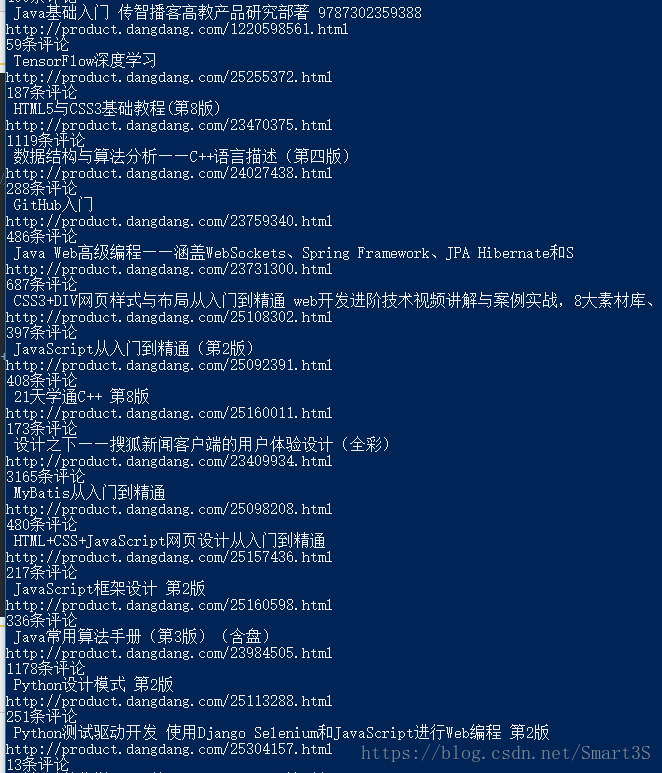
四、运行结果:
1、PowerShell(CMD)中:
2、SQLite数据库中(笔者使用SQLiteStudio进行数据库管理):