学习笔记9:受限玻尔兹曼机(RBM)
1.RBM模型
玻尔兹曼机是一大类的神经网络模型,但是在实际应用中使用最多的则是RBM。RBM本身模型很简单,只是一个两层的神经网络,因此严格意义上不能算深度学习的范畴。不过深度玻尔兹曼机(Deep Boltzmann Machine,以下简称DBM)可以看做是RBM的推广。理解了RBM再去研究DBM就不难了,因此本文主要关注于RBM。
回到RBM的结构,它是一个个两层的神经网络,如下图所示:
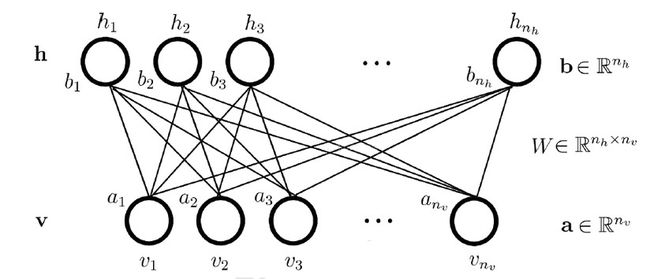

2.RBM概率分布
对于给定的状态向量h和v,则RBM当前的能量函数可以表示为:
E(v,h)=−aTv−bTh−hTWv E ( v , h ) = − a T v − b T h − h T W v
有了能量函数,则我们可以定义RBM的状态为给定v,h的概率分布为:
P(v,h)=1Ze−E(v,h) P ( v , h ) = 1 Z e − E ( v , h )
其中Z为归一化因子,类似于softmax中的归一化因子,表达式为:
Z=∑v,he−E(v,h) Z = ∑ v , h e − E ( v , h )
有了概率分布,我们现在来看条件分布P(h|v):
P(h|v)=P(h,v)P(v)=1P(v)1Zexp{aTv+bTh+hTWv}=1Z′exp{bTh+hTWv}=1Z′exp{∑j=1nh(bTjhj+hTjWj,:v)}=1Z′∏j=1nhexp{bTjhj+hTjWj,:v}(19)(20)(21)(22)(23) (19) P ( h | v ) = P ( h , v ) P ( v ) (20) = 1 P ( v ) 1 Z e x p { a T v + b T h + h T W v } (21) = 1 Z ′ e x p { b T h + h T W v } (22) = 1 Z ′ e x p { ∑ j = 1 n h ( b j T h j + h j T W j , : v ) } (23) = 1 Z ′ ∏ j = 1 n h e x p { b j T h j + h j T W j , : v }
其中Z′为新的归一化系数,表达式为:
1Z′=1P(v)1Zexp{aTv} 1 Z ′ = 1 P ( v ) 1 Z e x p { a T v }
同样的方式,我们也可以求出P(v|h)。
有了条件概率分布,现在我们来看看RBM的激活函数,提到神经网络,我们都绕不开激活函数,但是上面我们并没有提到。由于使用的是能量概率模型,RBM的基于条件分布的激活函数是很容易推导出来的。我们以P(hj=1|v)为例推导如下。
P(hj=1|v)=P(hj=1|v)P(hj=1|v)+P(hj=0|v)=exp{bj+Wj,:v}exp{0}+exp{bj+Wj,:v}=11+exp{−(bj+Wj,:v)}=sigmoid(bj+Wj,:v)(24)(25)(26)(27) (24) P ( h j = 1 | v ) = P ( h j = 1 | v ) P ( h j = 1 | v ) + P ( h j = 0 | v ) (25) = e x p { b j + W j , : v } e x p { 0 } + e x p { b j + W j , : v } (26) = 1 1 + e x p { − ( b j + W j , : v ) } (27) = s i g m o i d ( b j + W j , : v )
从上面可以看出, RBM里从可见层到隐藏层用的其实就是sigmoid激活函数。同样的方法,我们也可以得到隐藏层到可见层用的也是sigmoid激活函数。即:
P(vj=1|h)=sigmoid(aj+WT:,jh) P ( v j = 1 | h ) = s i g m o i d ( a j + W : , j T h )
有了激活函数,我们就可以从可见层和参数推导出隐藏层的神经元的取值概率了。对于0,1取值的情况,则大于0.5即取值为1。从隐藏层和参数推导出可见的神经元的取值方法也是一样的。
3.RBM模型的损失函数与优化
对于训练集的m个样本,RBM一般采用对数损失函数,即期望最小化下式:
L(W,a,b)=−∑i=1mln(P(V(i))) L ( W , a , b ) = − ∑ i = 1 m l n ( P ( V ( i ) ) )
4.RBM的实际应用
RBM可以看做是一个编码解码的过程,从可见层到隐藏层就是编码,而反过来从隐藏层到可见层就是解码。在推荐系统中,我们可以把每个用户对各个物品的评分做为可见层神经元的输入,然后有多少个用户就有了多少个训练样本。由于用户不是对所有的物品都有评分,所以任意样本有些可见层神经元没有值。但是这不影响我们的模型训练。在训练模型时,对于每个样本,我们仅仅用有用户数值的可见层神经元来训练模型。
对于可见层输入的训练样本和随机初始化的W,a我们可以用上面的sigmoid激活函数得到隐藏层的神经元的0,1值,这就是编码。然后反过来从隐藏层的神经元值和W,bW,b可以得到可见层输出,这就是解码。对于每个训练样本, 我们期望编码解码后的可见层输出和我们的之前可见层输入的差距尽量的小,即上面的对数似然损失函数尽可能小。按照这个损失函数,我们通过迭代优化得到W,a,b然后对于某个用于那些没有评分的物品,我们用解码的过程可以得到一个预测评分,取最高的若干评分对应物品即可做用户物品推荐了。
参考:http://www.cnblogs.com/pinard/p/6530523.html
https://blog.csdn.net/xbinworld/article/details/45013825