Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation
Fan S, Zhu J, Han X, et al. Metapath-guided Heterogeneous Graph Neural Network for Intent Recommendation[J]. 2019.
https://github.com/googlebaba/KDD2019-MEIRec
Abstract
与传统的查询推荐和项目推荐不同,意图推荐是在用户打开应用程序时,根据用户的历史行为自动推荐用户意图,而无需任何输入。

我们提出了Metapath-guided Embedding method for Intent Recommendation (called MEIRec),一种 metapath-guided heterogeneous Graph Neural Network 来学习 the embeddings of objects in intent recommendation。为了减少参数,我们提出了一种归一化的嵌入机制。
离线实验表明有性能一定的提升,在淘宝平台的在线数据上 CTR 有 1.54% 的提升,也吸引了 2.66% 的新用户进行 queries 搜索。
在意图推荐系统中,历史信息可以大致分为两类。 第一种是属性数据,例如用户的 profiles 和 objcet 的属性。 另一种类型是交互数据(triple interaction among users, items, and queries),例如用户单击(item)日志,用户搜索(query)日志和query guide(item)日志。
本文中,我们定义 the intent recommendation 为根据用户历史行为自动推荐个性化的 intent。intent recommendation 和传统的 query recommendation/suggestion 不同之处在于:
- 根据历史行为推荐而不是历史查询
- 不需要用户输入 partial query
现阶段应用在 industry 的 intent recommendation 一般是人工提取特征然后用分类器进行分类,严重依赖于领域知识和人工提取特征。
Heterogeneous Information Network (HIN)包含三种类型的objects and links(user click item, user search query and query guide item)
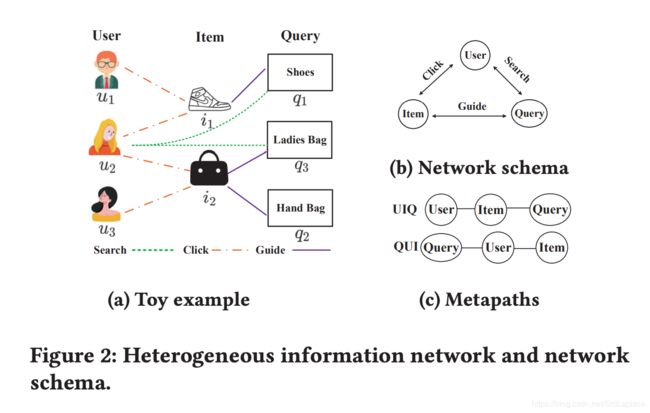
PRELIMINARIES
DEFINITION 1. Intent Recommendation.
Given a set < U , I , Q , A , B >
本文我们关心的是起点为 users,终点为 queries 的 metapaths。例如,“User−Item−Query (UIQ)” metapath 表明 user 点击 items, 这些 items 被一些 queries 引导;“Query−User−Item (QUI)” 表明 a query 被 some users 搜索, 这些 user 最近点击了 some items.
DEFINITION 2. Metapath-guided Neighbors.
给定一个对象 o o o和一个 metapath ρ ρ ρ, the metapath-guided neighbors 被定义为沿着 metapath 访问的邻居,i-th step neighbors of object o o o 写作 N ρ i ( o ) N^i_ρ (o) Nρi(o)。 N ρ 0 ( o ) N^0_ρ (o) Nρ0(o) 是 o o o本身。
以 Figure 2(a) 为例,给定 the metapath “User−Item−Query (UIQ)” 和 u 2 u_2 u2,我们可以得到 metapath-guided neighbors: N U I Q 0 ( u 2 ) = u 2 , N U I Q 1 ( u 2 ) = { i 1 , i 2 } , N U I Q 3 ( u 2 ) = { q 1 , q 2 , q 3 } N^0_{UIQ}(u_2)={u_2}, N^1_{UIQ}(u_2)=\{i_1,i_2\},N^3_{UIQ}(u_2)=\{q_1, q_2, q_3\} NUIQ0(u2)=u2,NUIQ1(u2)={i1,i2},NUIQ3(u2)={q1,q2,q3}。 u 2 u_2 u2所有的metapath-guided neighbors 为 N U I Q ( u 2 ) = { N U I Q 0 ( u 2 ) , N U I Q 1 ( u 2 ) , N U I Q 3 ( u 2 ) } = { u 2 , i 1 , i 2 , q 1 , q 2 , q 3 } N^{UIQ}(u_2) =\{N^0_{UIQ}(u_2), N^1_{UIQ}(u_2), N^3_{UIQ}(u_2)\}=\{u_2,i_1,i_2,q_1, q_2, q_3\} NUIQ(u2)={NUIQ0(u2),NUIQ1(u2),NUIQ3(u2)}={u2,i1,i2,q1,q2,q3}。
THE MEIREC MODEL
Overview
MEIRec 的目的是设计一个 heterogeneous GNN for enriching the representations of users and queries。除此之外,用 Term 的embedding来减少需要学习的参数。
Uniform Term Embedding
将 queries 和 items 拆分成 term,然后用 operation function 来将 Term 进行 aggregate,本文中我们采用 the average function 对 Term 进行 aggregate。
Metapath-guided Heterogeneous Graph Neural Network
我们首先说明如何沿 metapath UIQ 汇总邻居信息。我们使用统一的 term 嵌入来获取查询的初始嵌入。根据 Figure2(a)中的网络结构,得到 u 2 u_2 u2的第一步邻居集,即 N U I Q 1 ( u 2 ) = { i 1 , i 2 } N^1_{UIQ}(u2)=\{i_1, i_2\} NUIQ1(u2)={i1,i2}。对于其中的每个节点 i k i_k ik,我们提取第二步邻居集合 N U I Q 2 ( u 2 ) = { q 1 , q 2 , q 3 } N^2_{UIQ}(u2)=\{q_1, q_2, q_3\} NUIQ2(u2)={q1,q2,q3}。在获得 u 2 u_2 u2的第1步和第2步邻居集后,汇总第2步邻居的嵌入,以获得第1步邻居的嵌入。在此例中,汇总 q 1 q_1 q1的嵌入以获得项 i 1 i_1 i1的嵌入,并汇总 q 2 q_2 q2和 q 3 q_3 q3的嵌入以获得 i 2 i_2 i2的嵌入。最后,汇总第一步邻居 { i 1 , i 2 } \{i_1, i_2\} {i1,i2}的嵌入,以获得用户 u 2 u_2 u2的嵌入 U 2 U I Q U^{UIQ}_2 U2UIQ。同理,我们可以得到 u 2 u_2 u2以不同的元路径的嵌入,例如 U 2 U Q I U^{UQI}_2 U2UQI。然后汇总所有元路径嵌入,以获得 u 2 u_2 u2的最终嵌入(即 U 2 U_2 U2)。

User Modeling/Query Modeling
I j U I Q = g ( E q 1 , E q 2 , . . . ) I^{UIQ}_j= g(E_{q_1},E_{q_2},...) IjUIQ=g(Eq1,Eq2,...)
U i U I Q = g ( I q 1 U I Q , I q 2 U I Q , . . . ) U^{UIQ}_i=g(I^{UIQ}_{q_1}, I^{UIQ}_{q_2},...) UiUIQ=g(Iq1UIQ,Iq2UIQ,...)
U i = g ( U ρ 1 , U i ρ 2 , . . . ) U_i=g(U^{\rho_1}, U^{\rho_2}_i,...) Ui=g(Uρ1,Uiρ2,...)
同理: Q i = g ( Q i ρ 1 , Q i ρ 2 ⋅ ⋅ ⋅ ) Q_i= g(Q^{\rho_1}_i , Q^{\rho_2}_i ···) Qi=g(Qiρ1,Qiρ2⋅⋅⋅)
Optimization Objective
在模型中,我们预测用户 u i u_i ui搜索查询 q j q_j qj的概率 y ^ i j \hat{y}_{ij} y^ij。通过聚合用户和查询的邻居,为用户 u i u_i ui获得融合嵌入 U i U_i Ui,为查询 q j q_j qj获得融合的查询嵌入 Q j Q_j Qj。我们将传统方法中使用的 static features 送到 Multi-Layer Perceptron 中获取静态特征 S i j S_{ij} Sij。然后,我们将用户,查询和静态 features 的嵌入进行合并。最后,我们将融合的嵌入送到MLP层中以获得预测得分 y ˆ i j yˆ{ij} yˆij。我们有:
y ^ i j = s i g m o i d ( f ( U i ⊕ Q j ⊕ S i j ) ) \hat{y}_{ij}= sigmoid(f(U_i \oplus Q_j \oplus S_{ij})) y^ij=sigmoid(f(Ui⊕Qj⊕Sij))
f ( ⋅ ) f(\cdot) f(⋅) 表示一个只有一个输出的MLP, ⊕ \oplus ⊕表示 embedding concatenate operation。The loss function 是 a point-wise loss function:
J = ∑ Y ∪ Y − ( y i j l o g ( y ^ i j ) ) + ( 1 − y i j ) l o g ( 1 − y ^ i j ) ) J=\sum_{Y\cup Y^{-}}(y_{ij}log(\hat{y}_{ij}))+(1-y_{ij})log(1-\hat{y}_{ij})) J=Y∪Y−∑(yijlog(y^ij))+(1−yij)log(1−y^ij))
Y Y Y和 Y − Y^{-} Y−分别表示正负样本。

Model Analysis
对 MEIREC 的参数空间进行分析。由于采用 Uniform Term Embedding,参数空间远远小于传统方法。
4 OFFLINE EXPERIMENTS
Dataset
数据为 Taobao mobile application from Android and IOS online。对于 user 提取了 42 个static features,包括性别、年龄、购买力等;对于 query 提取了 39 个 static features,包括长度、term size、CTR等。我们收集10天的交互数据来构建 HIN,其中包括 100 million queries、400 million users 和 400 million items。此外 HIN 还包括 4 billion search relations between users and queries, 20 billion click relations between users and items, and 4 billion guide relations between items and queries。
接下来介绍如何构建训练和验证样本。收集的数据集中的每个原始交互记录都包含
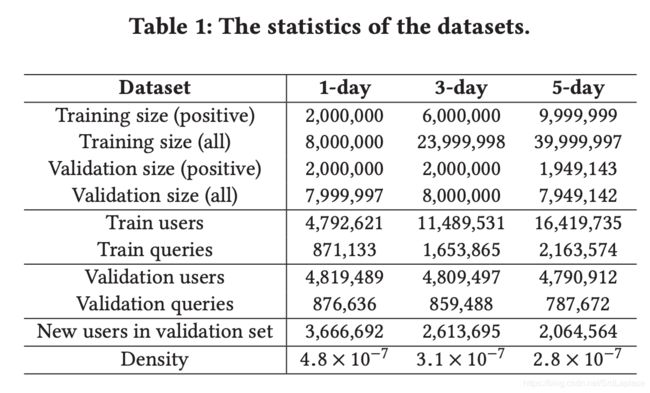
我们的数据集具有以下独特的特点:
- 数据集足够大,并且在训练和验证集中都包含数百万个用户和查询;
- 数据集在验证集中包含大约一半到四分之三的新用户;
- Table 1 中所示的密度((#interactions of users and queries)/(#users∗#queries))非常稀疏。
数据的这些特性,使得我们的模型设计的巨大挑战。
Baselines and Evaluation Metrics
对比模型
- LR : It is a linear model with static features.
- DNN: With the same input setting as LR, we implement the deep neural network with 3 layers MLP.
- GBDT: It is a scalable tree-based model for feature learning and classification task. We feed static features into GBDT.
- LR/DNN/GBDT+DW: We feed the static features of users and queries, as well as the pre-training embeddings learned by DeepWalk (DW) from structural information, into LR/DNN/GBDT model.
- LR/DNN/GBDT+MP: We feed the static features of users and queries, as well as the pre-training embeddings learned by MetaPath2vec (MP) from structural information, into LR/DNN/GBDT model.
- NeuMF: It is the state-of-art neural network method for top-N recommendation. Here we feed it with the structural information (interactions between users and queries), since it cannot be fed the static features.
- MEIRec: It’s our model with the input of the static features and structural information.
使用 AUC 来评估不同模型的性。
Detailed Implementation
基于Tensorflow实现了所提出的方法。 对于MEIRec,将 term 嵌入的维数设置为64。使用具有64个隐藏神经元的单层 LSTM 来对 user-query-sequence 和 user-item-sequence 进行建模,使用单层CNN汇总邻居信息。 对于GBDT,the tree number 设置为 200。对于Deepwalk / MetaPath2vec,嵌入的维数设置为32。对于所有方法,在训练阶段都将模型参数随机初始化为高斯分布,使用 mini-batch Adam 对模型进行优化。 将batch大小设置为512,将学习率设置为0.001。 所有实验均在Nvidia Tesla P100 Cluster中进行。
Performance Evaluation
从 Table 2 中我们可以看出,MEIRec 的表现明显好于其他模型。
在 method 级别,GBDT> DNN> LR> NeuMF。NeuMF无法学习新用户的嵌入,由于新查询出现在验证集中,因此新对象的嵌入将是随机变量,这会使NeuMF的性能最差。GBDT不会出现这一问题,因此在实际系统中得到广泛使用。在特征级别,基于 static features + heterogeneous embeddings > static features + homogeneous embeddings > static features。这表明融合更多信息通常可以获得更好的性能。使用异质网络嵌入(即MetaPath2vec)可以获得比同质网络嵌入(即Deepwalk)更好的性能。这表明我们应该考虑HIN中对象的异构性以获得更好的性能。
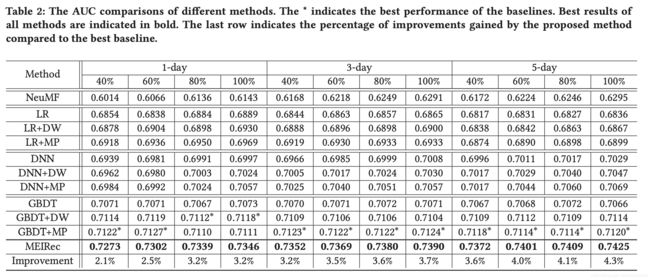
随着数据规模的增加,MEIRec 比 baseline 的优势更加明显(从2.1%增加到4.3%)。结果进一步证实了 MEIRec 对于大规模数据集更具可扩展性。
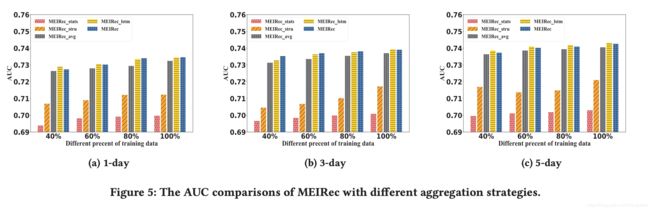
Effect of Aggregation Methods
采用 Aggregation 的 MEIRec 的表现:
- M E I R e c s t a t s MEIRec_{stats} MEIRecstats: It only uses the static features
- M E I R e c a v e MEIRec_{ave} MEIRecave: Both structural information and static features are used. We use the AVE function (i.e., average operation on aggregated embeddings) to aggregate the neighbors of both users and queries in this model.
- M E I R e c l s t m MEIRec_{lstm} MEIReclstm: It uses the structural information and static features. We use LSTM to aggregate the neighbors of users and use AVE to aggregate the neighbors of queries in this model.
- MEIRec: It is the proposed model MEIRec
For user side, the LSTM function capture time-sequence information for user behaviors, such as user click item sequence and user search query sequence.
And for query side, the unordered functions (i.e., CNN or AVG) are good enough to aggregate the neighbor information of query.
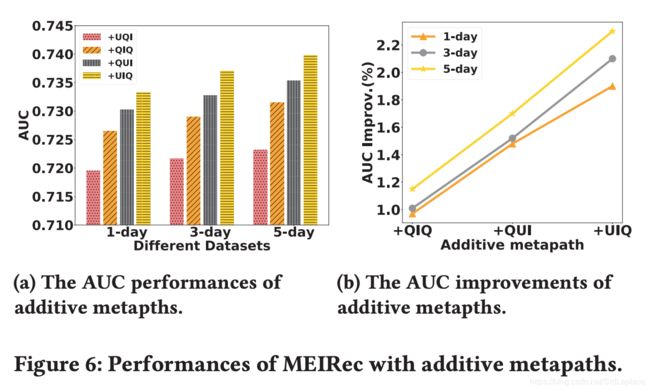
Effect of Different Metapaths
The four metapaths are UQI, QIQ, QUI, and UIQ, and they are added into the model by their order.
Effect of the Number of Neighbors
For query side, we set the number of neighbors as a fixed value 5, and for user side, we vary the number of neighbors from 3 to 10.

ONLINE EXPERIMENTS
UCTR=Unique Click/Unique Visitor

CONCLUSION
本文研究了意图推荐问题,该问题在增加移动电子商务中的用户活动和粘性方面起着重要作用。 为了解决意图推荐中的挑战,我们使用HIN对意图推荐系统中的对象和交互进行建模,并提出了一种新的等距引导GNN方法进行意图推荐,称为MEIRec。 MEIRec利用元路径引导的邻居来利用HIN中的丰富结构信息。 而且,在MEIRec中设计了统一的 term 嵌入,不仅显着减少了参数空间,而且使其适合于新生成的用户和查询。 离线和在线实验的大量结果证明了我们提出的模型的有效性。
代码
输入
0:81:wide_feat_list,42 static features of user + 39 static features query
81:276:user_item_seq_feat,用户单击日志,195= 15*13,13=10(item_terms)+1(item_topcate X)+1(item_leafcate X)+1(time_delta X) — rnn —> user_item_term_lstm_output (user_word_embedding)
276:292:query_feat, 16=10(query length)+3(query topcate length X)+3(query leafcate length X),— mean —>query_w2v_sum (query_embedding)
292:462:user_query_seq_feat,用户搜索日志,与user_item_seq_feat同理(user_query_seq_embedding)
462:562:query_item_query_feat,query 引导的 item 对应的 query 的 term avg – cnn/avg—> (query_item_query_embedding)
562:662:user_query_item_feat,n*10,10为 query 相应的 item 的term id,reduce mean 之后再根据 query 的顺序用rnn聚合(user_item_query_embedding)
662:812:user_item_query_feat,n*10,10为 item 相应的 query 的term id,reduce mean 之后再根据 item 的顺序用rnn聚合(user_query_item_embedding)
812::query_user_item_feat,点击 query 的 user 点击过的 item 的 term avg — cnn/avg—> (query_user_item_embedding)
中间层
wide_feat_list — wide_full_connect —>wide_hidden_layer1 (64 维)
embedding — tf.concat — tf.nn.dropout (64*7 维)—单层全链接—> qu_term_concat(64 维)
[wide_feat_list, qu_term_concat] — tf.concat(64*2维) — 两层全链接(128-64-1) — > global_res
loss 和优化
loss = 交叉熵+对全链接w的L2正则化
优化器 adam,带 clip_by_global_norm(global 的梯度阶段)、exponential_decay(梯度衰减)、ExponentialMovingAverage(平滑)