Python3.6+Beautiful Soup+csv 爬取豆瓣电影Top250
豆瓣电影 Top 250:https://movie.douban.com/top250?start=0&filter=
Beautiful Soup:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
注:本文获取内容全部使用Beautiful Soup的select方法,使用css选择器。有html+css编程经验的可以使用css选择器,方便快捷。
0. 分析页码
当鼠标放在第二页的时候,链接显示:https://movie.douban.com/top250?start=25&filter= 从网页数据上可以看到每一页默认显示25条数据。即翻页修改此参数即可 0,25,50…,225

程序构造循环:
url = 'https://movie.douban.com/top250?start=%s&filter='
for page in range(10):
current_page_url = url % (page * 25)
即 025=0,125=25…9*25=225
1. 分析每一个电影
通过查看元素可以看到,每一个电影卡片对应ol标签下的li标签,即遍历此li标签即可。
通过css选择器定位li标签lis = soup.select("#content .grid_view > li")
‘#‘代表id选择器,’.‘代表class选择器,’>’ 代表只获取下一级
一般情况下优选使用id(唯一),其次class,最后是标签。
PS:这里是html+css编程经验,如果使用某一个选择器不能精确定位时,可以混合使用多种,优先使用id缩小范围。

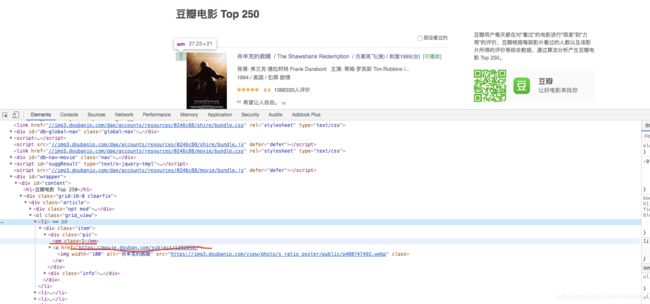
2. 获取序号及链接
在li标签里面,序号在class=‘pic’的div标签下的第一个em标签中,链接在第一个a标签的属性href中,因此代码为:
index = li.select(".pic em")[0].text
movie_url = li.select(".pic a")[0]['href']
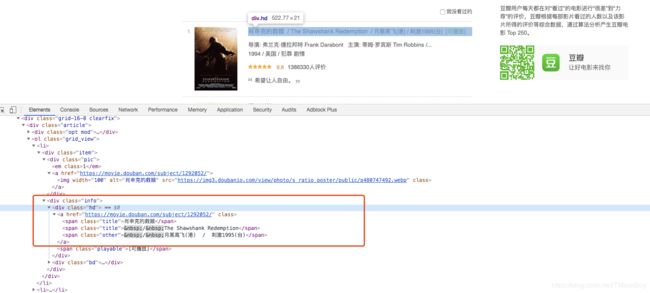
3. 获取标题
电影名称在div[class=‘info’]下的第一个a标签中。
title = li.select(".info .hd a")[0].get_text().replace('\n', '')
如果需要分开获取可以选中a标签下的span标签,使用for循环处理,或根据/截取处理。
spans = li.select(".info .hd a span")
for span in spans:
print(span.get_text())
一般数据很难直接获取理想的格式,可以在获取到后使用基本的正则表达式或字符串处理。
4. 获取导演,主要,上映时间,类型
info = li.select(".info .bd p")[0].get_text().strip()

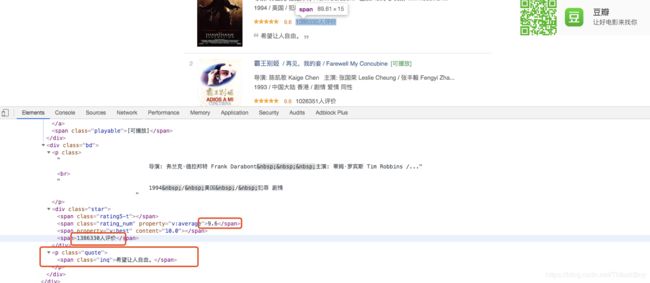
5. 评分及简介
因为个别电影没有一句话的简介,故加了判断,如果不存在,使用[0]获取第一个元素会报错。
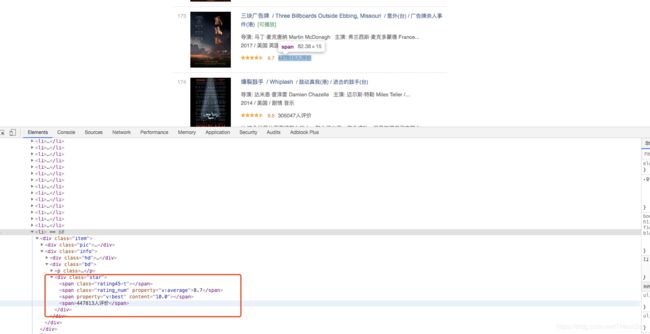
如:https://movie.douban.com/top250?start=150&filter= 序号173的电影,见下下图。
PS:一般实际项目中会发现个别条目会有变化,导致程序出现异常停止或获取到的数据不对,这就需要在实际运行中及时调整代码。
rating_start = li.select(".star .rating_num")[0].get_text()
rtating_total_count = li.select(".star span")[-1].get_text()
if li.select(".quote"):
quote = li.select(".quote")[0].get_text()
else:
quote = None
6. 写入csv文件
out = open('movie.csv', 'a', newline='')
movie_csv = csv.writer(out, dialect='excel')
movie_csv.writerow(['序号', '链接', '标题', '信息', '评分', '影评数', '描述'])
7. 完整代码
import requests
import csv
from bs4 import BeautifulSoup
url = 'https://movie.douban.com/top250?start=%s&filter='
def main():
out = open('movie.csv', 'a', newline='')
movie_csv = csv.writer(out, dialect='excel')
movie_csv.writerow(['序号', '链接', '标题', '信息', '评分', '影评数', '描述'])
for page in range(10):
content = requests.get(url % (25 * page)).content
soup = BeautifulSoup(content)
lis = soup.select("#content .grid_view > li")
for li in lis:
index = li.select(".pic em")[0].text
movie_url = li.select(".pic a")[0]['href']
title = li.select(".info .hd a")[0].get_text().replace('\n', '')
# spans = li.select(".info .hd a span")
# for span in spans:
# print(span.get_text())
info = li.select(".info .bd p")[0].get_text().strip()
rating_start = li.select(".star .rating_num")[0].get_text()
rtating_total_count = li.select(".star span")[-1].get_text()
if li.select(".quote"):
quote = li.select(".quote")[0].get_text()
else:
quote = None
movie_csv.writerow([index, movie_url, title, info, rating_start, rtating_total_count, quote])
print("now page:%s" % page)
# 主函数
if __name__ == '__main__':
main()