windows 下运行spark on yarn (非submit方式)
本地环境
本地操作系统: windows 10. 1709 教育版
本地hadoop版本:hadoop-2.6.5
本地winutils版本:hadoop2.6.4-2.6.7
本地spark版本: spark-2.2.0-bin-hadoop2.6
本地scala版本:scala-2.11.11
本地java版本:jdk-1.8.0_151
本地IDEA版本:idea 2017.01
远端环境
集群操作系统: ubuntu-14.04-server版
集群hadoop版本: cloudera-cdh-5.13.0
集群spark 版本: SPARK2-2.2.0.cloudera1-1.cdh5.12.0.p0.142354
集群scala版本: cloudera cdh 5.13 自带spark1.6 (scala运行环境scala-2.9.2) spark2.2默认是用scala-2.11.8编译
集群java版本:jdk-1.8.0_151
资源下载地址
hadoop-2.6.5
http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
spark-2.2.0
http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.0/spark-2.2.0-bin-hadoop2.6.tgz
scala-2.11.11
https://downloads.lightbend.com/scala/2.11.11/scala-2.11.11.msi
winutils
https://github.com/steveloughran/winutils
java
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
spark2-csd
http://archive.cloudera.com/spark2/csd/SPARK2_ON_YARN-2.2.0.cloudera1.jar
安装步骤cdh5.13安装
该安装步骤不是本文重点,详细方法见文档ubuntu 14.04 搭建cloudera CDH.docx
idea 安装
该安装步骤自行百度即可
cdh中安装spark 2.2.0
由于cdh集成的spark依然是spark1.6,需要在集群中添加csd,然后安装spark 2
1.将csd文件下载并放到cloudera manager 节点的 /opt/cloudera/csd/目录下
此处需要将SPARK2_ON_YARN-2.2.0.cloudera1.jar 的用户的组修改为cloudera-scm:cloudera-scm

2.重启 cloudera-scm-server 服务
service cloudera-scm-server restart
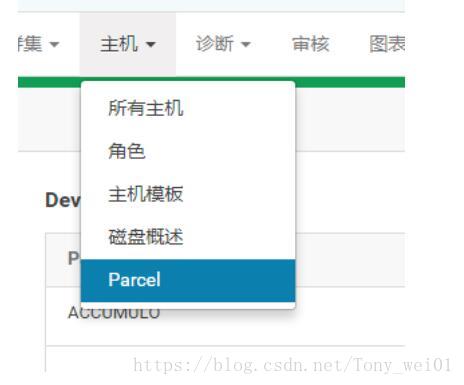
在cloudera manager 的 主机->parcel下

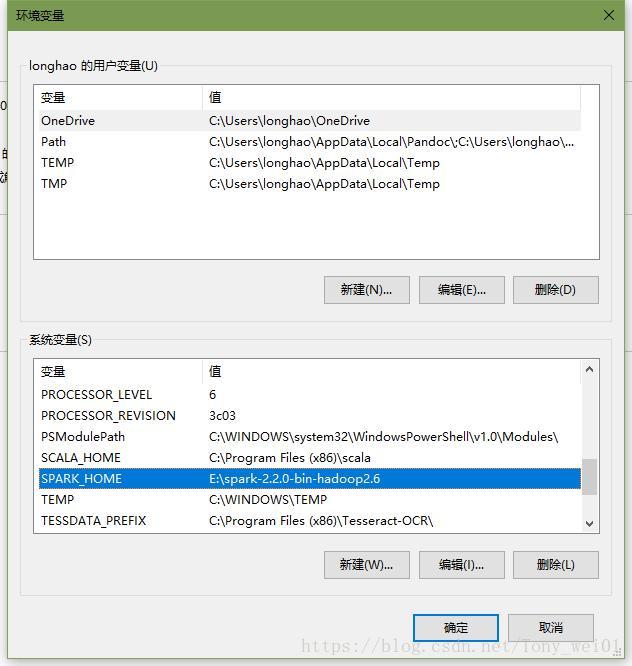
配置系统环境变量
安装好scala和java后,分别配置JAVA_HOME和SCALA_HOME
同样,下载好hadoop和spark后配置SPARK_HOME和HADOOP_HOME.
并在path变量中添加%JAVA_HOME%\bin %SCALA_HOME%\bin %HADOOP_HOME%\bin
%SPARK_HOME%\bin
此外需要将winutils工具bin目录下的文件全部拷贝到%HADOOP_HOME%\bin中去(重复的
配置IDEA和MAVEN
配置maven的源,将maven的源修改为aliyun
IDEA内建的meven是3.3.9 它默认使用的配置文件是在windows的当前用户的.m2目录下,我们修改setting.xml
在mirrors节添加mirror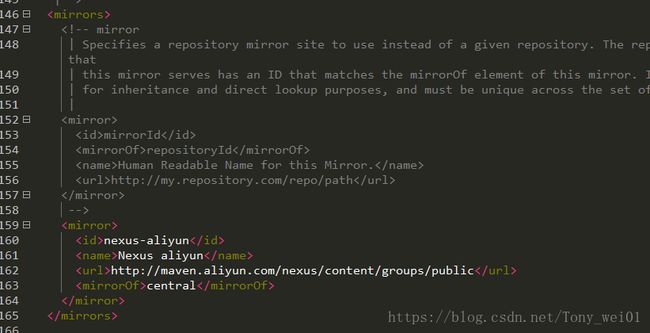
IDEA配置支持scala
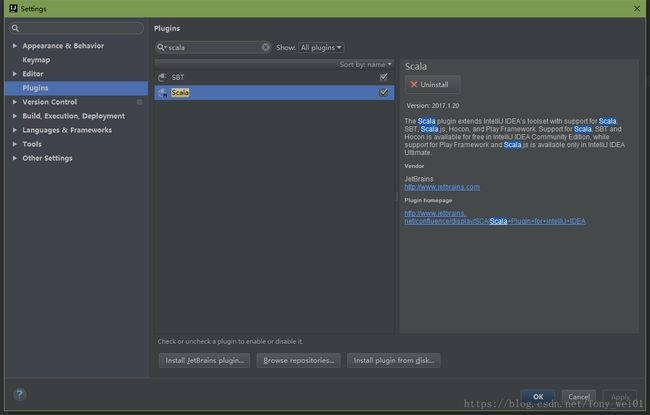
File->Settings->Plugins->搜索scala 安装即可,重启idea生效
新建scala工程


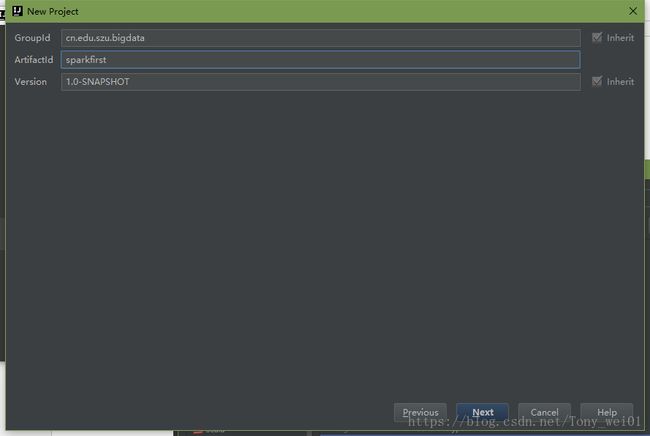
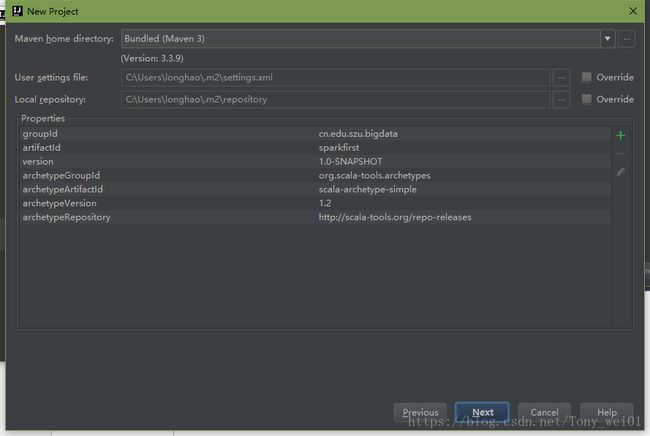
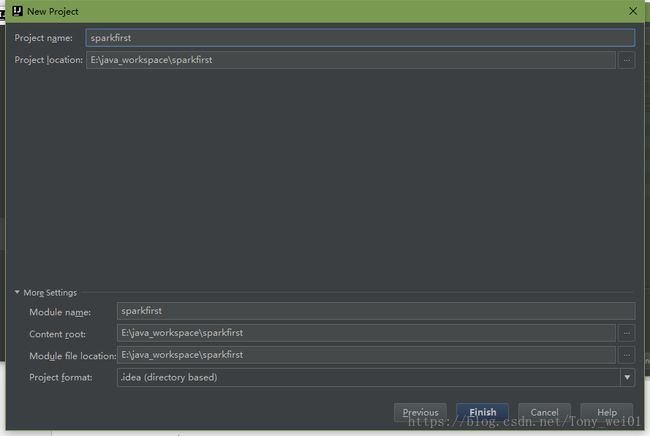
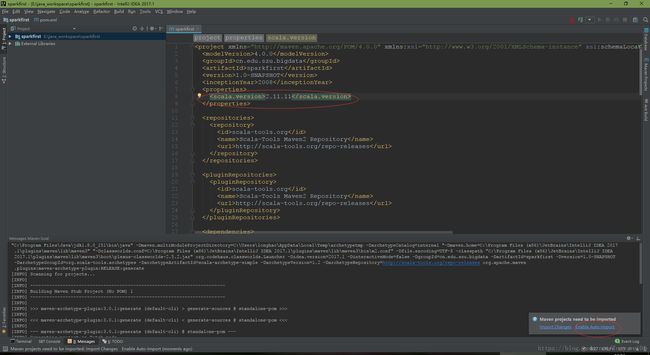
在pom.xml中
修改scala的版本,并enable auto import
删除
junit
junit
4.4
test
org.specs
specs
1.2.5
test
设置target:jvm-1.8
${scala.version}
-target:jvm-1.8
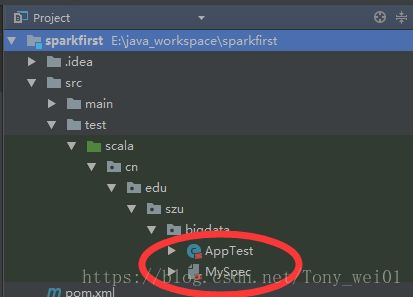
删除测试类
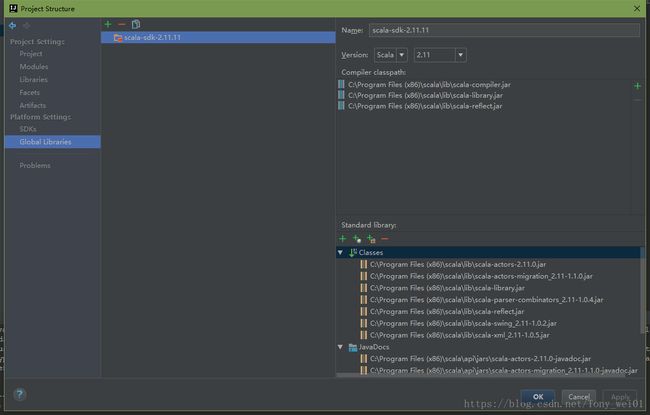
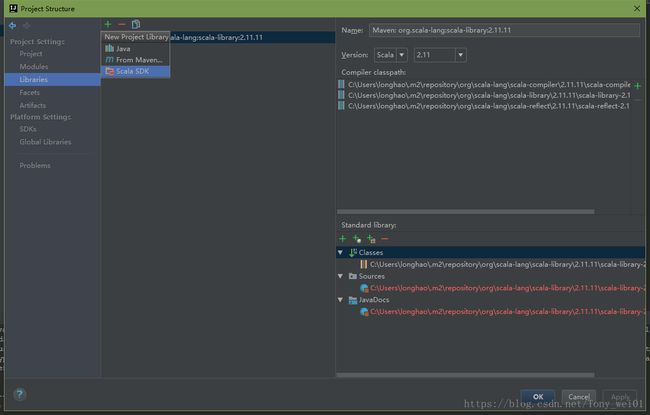
File->Project-Structure
1.添加scala类库
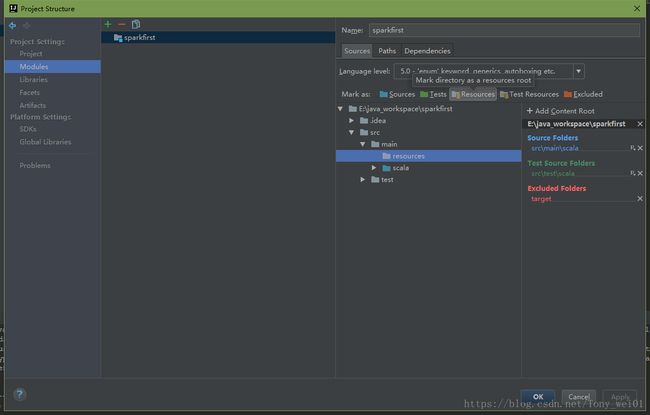
设置resources目录为资源目录
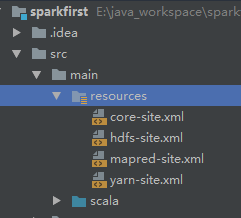
将cdh5.13 的5个配置文件拷贝放进resources目录

拷贝 core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml到resources目录

拷贝 hive-site.xml 到resources目录
(若使用hbase,同理)
添加cloudera cdh maven支持
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/
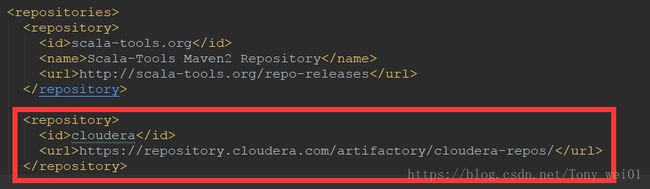
在节中 添加如下