# HELP go_gc_duration_seconds A summary of the GC invocation durations.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0.000349093
go_gc_duration_seconds{quantile="0.25"} 0.000438804
go_gc_duration_seconds{quantile="0.5"} 0.000482303
go_gc_duration_seconds{quantile="0.75"} 0.000549487
go_gc_duration_seconds{quantile="1"} 0.005140537
go_gc_duration_seconds_sum 9.595970185
go_gc_duration_seconds_count 17804
# HELP go_goroutines Number of goroutines that currently exist.
# TYPE go_goroutines gauge
go_goroutines 510
# HELP go_info Information about the Go environment.
# TYPE go_info gauge
go_info{version="go1.11.2"} 1
# HELP go_memstats_alloc_bytes Number of bytes allocated and still in use.
# TYPE go_memstats_alloc_bytes gauge
go_memstats_alloc_bytes 1.7242784e+07
# HELP go_memstats_alloc_bytes_total Total number of bytes allocated, even if freed.
# TYPE go_memstats_alloc_bytes_total counter
go_memstats_alloc_bytes_total 1.09448288456e+11
# HELP go_memstats_buck_hash_sys_bytes Number of bytes used by the profiling bucket hash table.
# TYPE go_memstats_buck_hash_sys_bytes gauge
go_memstats_buck_hash_sys_bytes 1.558332e+06
# HELP go_memstats_frees_total Total number of frees.
# TYPE go_memstats_frees_total counter
go_memstats_frees_total 8.76379383e+08
# HELP go_memstats_gc_cpu_fraction The fraction of this program's available CPU time used by the GC since the program started.
# TYPE go_memstats_gc_cpu_fraction gauge
go_memstats_gc_cpu_fraction 0.00043950832257221354
# HELP go_memstats_gc_sys_bytes Number of bytes used for garbage collection system metadata.
# TYPE go_memstats_gc_sys_bytes gauge
go_memstats_gc_sys_bytes 2.404352e+06
# HELP go_memstats_heap_alloc_bytes Number of heap bytes allocated and still in use.
# TYPE go_memstats_heap_alloc_bytes gauge
go_memstats_heap_alloc_bytes 1.7242784e+07
# HELP go_memstats_heap_idle_bytes Number of heap bytes waiting to be used.
# TYPE go_memstats_heap_idle_bytes gauge
go_memstats_heap_idle_bytes 3.4349056e+07
# HELP go_memstats_heap_inuse_bytes Number of heap bytes that are in use.
# TYPE go_memstats_heap_inuse_bytes gauge
go_memstats_heap_inuse_bytes 2.3027712e+07
# HELP go_memstats_heap_objects Number of allocated objects.
# TYPE go_memstats_heap_objects gauge
go_memstats_heap_objects 76103
# HELP go_memstats_heap_released_bytes Number of heap bytes released to OS.
# TYPE go_memstats_heap_released_bytes gauge
go_memstats_heap_released_bytes 0
# HELP go_memstats_heap_sys_bytes Number of heap bytes obtained from system.
# TYPE go_memstats_heap_sys_bytes gauge
go_memstats_heap_sys_bytes 5.7376768e+07
# HELP go_memstats_last_gc_time_seconds Number of seconds since 1970 of last garbage collection.
# TYPE go_memstats_last_gc_time_seconds gauge
go_memstats_last_gc_time_seconds 1.5578887209621124e+09
# HELP go_memstats_lookups_total Total number of pointer lookups.
# TYPE go_memstats_lookups_total counter
go_memstats_lookups_total 0
# HELP go_memstats_mallocs_total Total number of mallocs.
# TYPE go_memstats_mallocs_total counter
go_memstats_mallocs_total 8.76455486e+08
# HELP go_memstats_mcache_inuse_bytes Number of bytes in use by mcache structures.
# TYPE go_memstats_mcache_inuse_bytes gauge
go_memstats_mcache_inuse_bytes 82944
# HELP go_memstats_mcache_sys_bytes Number of bytes used for mcache structures obtained from system.
# TYPE go_memstats_mcache_sys_bytes gauge
go_memstats_mcache_sys_bytes 98304
# HELP go_memstats_mspan_inuse_bytes Number of bytes in use by mspan structures.
# TYPE go_memstats_mspan_inuse_bytes gauge
go_memstats_mspan_inuse_bytes 387752
# HELP go_memstats_mspan_sys_bytes Number of bytes used for mspan structures obtained from system.
# TYPE go_memstats_mspan_sys_bytes gauge
go_memstats_mspan_sys_bytes 442368
# HELP go_memstats_next_gc_bytes Number of heap bytes when next garbage collection will take place.
# TYPE go_memstats_next_gc_bytes gauge
go_memstats_next_gc_bytes 2.1128848e+07
# HELP go_memstats_other_sys_bytes Number of bytes used for other system allocations.
# TYPE go_memstats_other_sys_bytes gauge
go_memstats_other_sys_bytes 1.0895804e+07
# HELP go_memstats_stack_inuse_bytes Number of bytes in use by the stack allocator.
# TYPE go_memstats_stack_inuse_bytes gauge
go_memstats_stack_inuse_bytes 9.732096e+06
# HELP go_memstats_stack_sys_bytes Number of bytes obtained from system for stack allocator.
# TYPE go_memstats_stack_sys_bytes gauge
go_memstats_stack_sys_bytes 9.732096e+06
# HELP go_memstats_sys_bytes Number of bytes obtained from system.
# TYPE go_memstats_sys_bytes gauge
go_memstats_sys_bytes 8.2508024e+07
# HELP go_threads Number of OS threads created.
# TYPE go_threads gauge
go_threads 110
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 5349.91
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 655360
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 411
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 4.16768e+07
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.55783237186e+09
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 4.801744896e+09
# HELP process_virtual_memory_max_bytes Maximum amount of virtual memory available in bytes.
# TYPE process_virtual_memory_max_bytes gauge
process_virtual_memory_max_bytes -1
# HELP promhttp_metric_handler_requests_in_flight Current number of scrapes being served.
# TYPE promhttp_metric_handler_requests_in_flight gauge
promhttp_metric_handler_requests_in_flight 1
# HELP promhttp_metric_handler_requests_total Total number of scrapes by HTTP status code.
# TYPE promhttp_metric_handler_requests_total counter
promhttp_metric_handler_requests_total{code="200"} 488
promhttp_metric_handler_requests_total{code="500"} 0
promhttp_metric_handler_requests_total{code="503"} 0
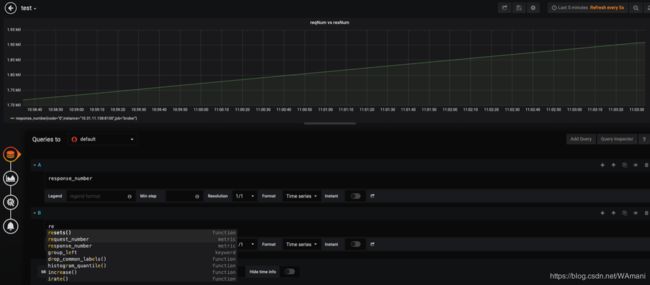
# HELP request_number
# TYPE request_number counter
request_number{handle="/xid/v2/search"} 1.475309e+06
# HELP response_number
# TYPE response_number counter
response_number{code="0"} 1.475209e+06
# HELP search_cost_time_detail milliseconds latency distributions.
# TYPE search_cost_time_detail histogram
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="0"} 0
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="50"} 0
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="100"} 20403
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="150"} 528289
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="200"} 1.436994e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="250"} 1.474139e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="300"} 1.475171e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="350"} 1.475203e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="400"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="450"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="500"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="550"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="600"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="650"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="700"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="750"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="800"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="850"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="900"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="950"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="rpc",le="+Inf"} 1.475209e+06
search_cost_time_detail_sum{set_name="wyx_50w_50_1",stage="rpc"} 2.3143792061221814e+08
search_cost_time_detail_count{set_name="wyx_50w_50_1",stage="rpc"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="0"} 0
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="50"} 0
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="100"} 20158
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="150"} 514676
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="200"} 1.436145e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="250"} 1.474113e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="300"} 1.475162e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="350"} 1.475202e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="400"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="450"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="500"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="550"} 1.475208e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="600"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="650"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="700"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="750"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="800"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="850"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="900"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="950"} 1.475209e+06
search_cost_time_detail_bucket{set_name="wyx_50w_50_1",stage="search",le="+Inf"} 1.475209e+06
search_cost_time_detail_sum{set_name="wyx_50w_50_1",stage="search"} 2.3194894158179152e+08
search_cost_time_detail_count{set_name="wyx_50w_50_1",stage="search"} 1.475209e+06
|