HBase读写详细流程
HBase定义
HBase 是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建大规模结构化存储集群。
HBase 是Google Bigtable 的开源实现,与Google Bigtable 利用GFS作为其文件存储系统类似, HBase 利用Hadoop HDFS 作为其文件存储系统;Google 运行MapReduce 来处理Bigtable中的海量数据, HBase 同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable 利用Chubby作为协同服务, HBase 利用Zookeeper作为对应。
HBase架构图
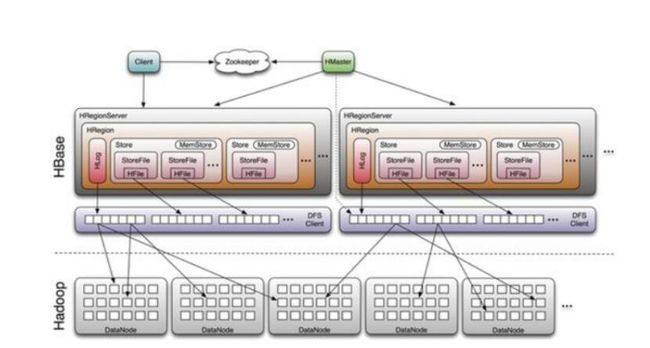
· HMaster链接Zookeeper目的:HMaster需要知道哪些HRegionServere是活的及HRegionServer所在的位置,然后管理HRegionServer。
· HBase内部是通过DFS client把数据写到HDFS上的
· 每一个HRegionServer有多个HRegion,每一个HRegion有多个Store,每一个Store对应一个列簇。
· HFile是HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,StoreFile就是对HFile进行了封装,然后进行数据的存储。
· HStore由MemStore和StoreFile组成。
· HLog记录数据的所有变更,可以用来做数据恢复。
· hdfs对应的目录结构为:namespace->table->列簇->列->单元格
HBase架构中各模块功能
Client
整个HBase集群的访问入口;
使用HBase RPC机制与HMaster和HRegionServer进行通信;
与HMaster进行通信进行管理表的操作;
与HRegionServer进行数据读写类操作;
包含访问HBase的接口,并维护cache来加快对HBase的访问
Zookeeper
保证任何时候,集群中只有一个HMaster;
存贮所有HRegion的寻址入口;
实时监控HRegion Server的上线和下线信息,并实时通知给HMaster;
存储HBase的schema和table元数据;
Zookeeper Quorum存储表地址、HMaster地址。
HMaster
HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master在运行,主负责Table和Region的管理工作。
管理用户对表的创建、删除等操作;
管理HRegionServer的负载均衡,调整Region分布;
Region Split后,负责新Region的分布;
在HRegionServer停机后,负责失效HRegionServer上Region迁移工作。
HRegion Server
监控维护HRegion,处理对这些HRegion的IO请求,向HDFS文件系统中读写数据;
负责切分在运行过程中变得过大的HRegion。
Client访问hbase上数据的过程并不需要master参与(寻址访问Zookeeper和HRegion Server,数据读写访问HRegione Server),HMaster仅仅维护这table和Region的元数据信息,负载很低。
HBase写数据流程
1、Client先访问zookeeper,从meta表获取相应region信息,然后找到meta表的数据
2、根据namespace、表名和rowkey根据meta表的数据找到写入数据对应的region信息
3、找到对应的regionserver
4、把数据分别写到HLog和MemStore上一份
5、MemStore达到一个阈值后则把数据刷成一个StoreFile文件。(若MemStore中的数据有丢失,则可以总HLog上恢复)
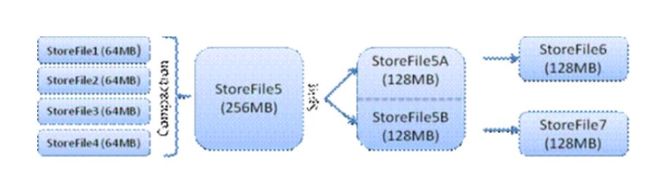
6、 当多个StoreFile文件达到一定的大小后,会触发Compact合并操作,合并为一个StoreFile,(这里同时进行版本的合并和数据删除。)
7、 当Storefile大小超过一定阈值后,会把当前的Region分割为两个(Split),这里相当于把一个大的region分割成两个region,并由Hmaster分配到相应的HRegionServer,实现负载均衡。
HBase读取数据流程
1、Client先访问zookeeper,从zookeeper中找到meta表region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息。
2、根据namespace、表名和rowkey在meta表中找到对应的region信息
3、找到这个region对应的regionserver
4、查找对应的region
5、先从MemStore找数据,如果没有,再到StoreFile上读(为了读取的效率)。