SQL查询最近连续登录的用户
SQL查询最近连续登录的用户
SQL> select t.* from user_logon_history t;
USER_ID USER_NAME LOGON_DATE
-------------------------------- -------------------------------- -----------
1 ZhangSan 4/1/2018
1 ZhangSan 4/2/2018
1 ZhangSan 4/4/2018
1 ZhangSan 4/5/2018
1 ZhangSan 4/7/2018
2 LiSi 4/15/2018
2 LiSi 4/16/2018
2 LiSi 4/17/2018
3 WangWu 4/8/2018
3 WangWu 4/9/2018
3 WangWu 4/10/2018
3 WangWu 4/11/2018
12 rows selected
SQL>
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××88
如上结果,如何查询出最近连续3天登录的用户?大家讨论一下,看看谁的解决方案好。
10
USER_ID USER_NAME LOGON_DATE
-------------------------------- -------------------------------- -----------
1 ZhangSan 4/1/2018
1 ZhangSan 4/2/2018
1 ZhangSan 4/4/2018
1 ZhangSan 4/5/2018
1 ZhangSan 4/7/2018
2 LiSi 4/15/2018
2 LiSi 4/16/2018
2 LiSi 4/17/2018
3 WangWu 4/8/2018
3 WangWu 4/9/2018
3 WangWu 4/10/2018
3 WangWu 4/11/2018
12 rows selected
SQL>
×××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××××88
如上结果,如何查询出最近连续3天登录的用户?大家讨论一下,看看谁的解决方案好。
全部回复
只看楼主 倒序排列![]() javaanddonet 楼主 LV22楼
javaanddonet 楼主 LV22楼
我先给出我自己的写法,这个方法比较笨拙。第一步:在原表的结构上,虚拟出四列,其中分别是:当前行的logon_date的下一天,当前行的logon_date的下两天,当前行的往后推一行的logon_date,当前行的往后推两行的logon_date,sql如下所示:
select
t.user_id,
t.user_name,
t.logon_date,
t.logon_date+1 as next_1day_date,
t.logon_date+2 as next_2days_date,
lead(t.logon_date, 1, null) over(partition by t.user_id order by t.logon_date) as next_1row_date,
lead(t.logon_date, 2, null) over(partition by t.user_id order by t.logon_date) as next_2row2_date
from
user_logon_history t
order by t.user_id, t.logon_date
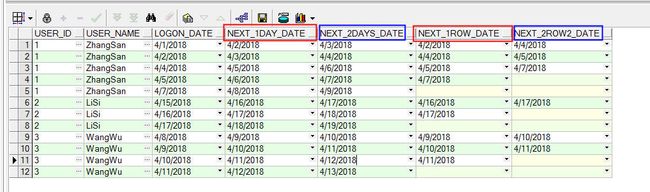
第二步:对上述的结果进行过滤,得到符合条件的记录,筛选过滤的条件是:上图中红色的列相等,并且蓝色的列也相等。sql语句如下:
select a.* from (
select
t.user_id,
t.user_name,
t.logon_date,
t.logon_date+1 as next_1day_date,
t.logon_date+2 as next_2days_date,
lead(t.logon_date, 1, null) over(partition by t.user_id order by t.logon_date) as next_1row_date,
lead(t.logon_date, 2, null) over(partition by t.user_id order by t.logon_date) as next_2row2_date
from
user_logon_history t
order by t.user_id, t.logon_date
) a where a.next_1day_date = a.next_1row_date
and a.next_2days_date = next_2row2_date

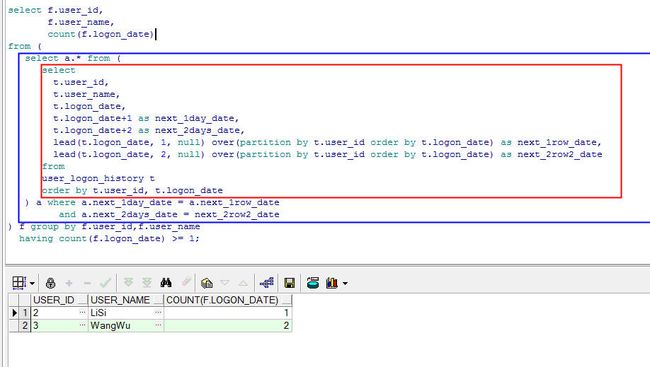
第三部就是再包装一层查询,统计出最后的结果,sql语句如下:
select f.user_id,
f.user_name,
count(f.logon_date)
from (
select a.* from (
select
t.user_id,
t.user_name,
t.logon_date,
t.logon_date+1 as next_1day_date,
t.logon_date+2 as next_2days_date,
lead(t.logon_date, 1, null) over(partition by t.user_id order by t.logon_date) as next_1row_date,
lead(t.logon_date, 2, null) over(partition by t.user_id order by t.logon_date) as next_2row2_date
from
user_logon_history t
order by t.user_id, t.logon_date
) a where a.next_1day_date = a.next_1row_date
and a.next_2days_date = next_2row2_date
) f group by f.user_id,f.user_name
having count(f.logon_date) >= 1;
select
t.user_id,
t.user_name,
t.logon_date,
t.logon_date+1 as next_1day_date,
t.logon_date+2 as next_2days_date,
lead(t.logon_date, 1, null) over(partition by t.user_id order by t.logon_date) as next_1row_date,
lead(t.logon_date, 2, null) over(partition by t.user_id order by t.logon_date) as next_2row2_date
from
user_logon_history t
order by t.user_id, t.logon_date
第二步:对上述的结果进行过滤,得到符合条件的记录,筛选过滤的条件是:上图中红色的列相等,并且蓝色的列也相等。sql语句如下:
select a.* from (
select
t.user_id,
t.user_name,
t.logon_date,
t.logon_date+1 as next_1day_date,
t.logon_date+2 as next_2days_date,
lead(t.logon_date, 1, null) over(partition by t.user_id order by t.logon_date) as next_1row_date,
lead(t.logon_date, 2, null) over(partition by t.user_id order by t.logon_date) as next_2row2_date
from
user_logon_history t
order by t.user_id, t.logon_date
) a where a.next_1day_date = a.next_1row_date
and a.next_2days_date = next_2row2_date
第三部就是再包装一层查询,统计出最后的结果,sql语句如下:
select f.user_id,
f.user_name,
count(f.logon_date)
from (
select a.* from (
select
t.user_id,
t.user_name,
t.logon_date,
t.logon_date+1 as next_1day_date,
t.logon_date+2 as next_2days_date,
lead(t.logon_date, 1, null) over(partition by t.user_id order by t.logon_date) as next_1row_date,
lead(t.logon_date, 2, null) over(partition by t.user_id order by t.logon_date) as next_2row2_date
from
user_logon_history t
order by t.user_id, t.logon_date
) a where a.next_1day_date = a.next_1row_date
and a.next_2days_date = next_2row2_date
) f group by f.user_id,f.user_name
having count(f.logon_date) >= 1;
10 小时前
![]() javaanddonet 楼主 LV23楼
javaanddonet 楼主 LV23楼
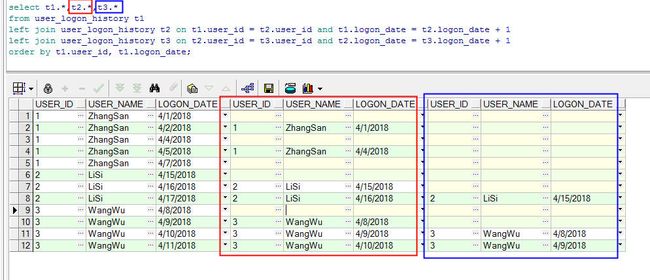
另外一种思路,自连接:
select t1.*,t2.*,t3.* from user_logon_history t1
left join user_logon_history t2 on t1.user_id = t2.user_id and t1.logon_date = t2.logon_date + 1
left join user_logon_history t3 on t2.user_id = t3.user_id and t2.logon_date = t3.logon_date + 1
order by t1.user_id, t1.logon_date;
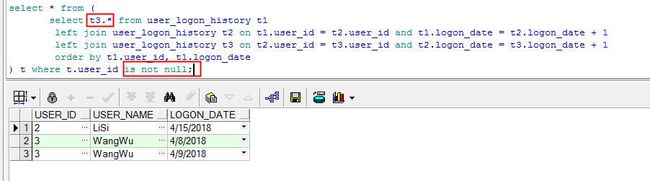
select * from (
select t3.* from user_logon_history t1
left join user_logon_history t2 on t1.user_id = t2.user_id and t1.logon_date = t2.logon_date + 1
left join user_logon_history t3 on t2.user_id = t3.user_id and t2.logon_date = t3.logon_date + 1
order by t1.user_id, t1.logon_date
) t where t.user_id is not null;
select t1.*,t2.*,t3.* from user_logon_history t1
left join user_logon_history t2 on t1.user_id = t2.user_id and t1.logon_date = t2.logon_date + 1
left join user_logon_history t3 on t2.user_id = t3.user_id and t2.logon_date = t3.logon_date + 1
order by t1.user_id, t1.logon_date;
select * from (
select t3.* from user_logon_history t1
left join user_logon_history t2 on t1.user_id = t2.user_id and t1.logon_date = t2.logon_date + 1
left join user_logon_history t3 on t2.user_id = t3.user_id and t2.logon_date = t3.logon_date + 1
order by t1.user_id, t1.logon_date
) t where t.user_id is not null;
9 小时前
![]() hyj4楼
hyj4楼
这里先说下思路,看表中已经对数据排序了。也就是分别按照用户名和日期排序。首先根据第一条记录,也就是起始日期。然后通过日期函数自增,与数据库中日期比较。如果自增日期等于当前日期,说明是连续的,继续比较。直到找到大于当前日期。这就说明不连续。当然连续三天的话,再加个过滤条件就可以了。
9 小时前
![]() fly2015 LV45楼
fly2015 LV45楼
javaanddonet 发表于 2018-4-26 10:30
另外一种思路,自连接:
select t1.*,t2.*,t3.* from user_logon_history t1
left join user_logon_histor ...
另外一种思路,自连接:
select t1.*,t2.*,t3.* from user_logon_history t1
left join user_logon_histor ...
需求到底是 最近连续3天 还是只要有连续3天 就行,如果是像你描述的 最近连续3天 应该会简单好多
8 小时前
![]() javaanddonet 楼主 LV26楼
javaanddonet 楼主 LV26楼
fly2015 发表于 2018-4-26 11:29
需求到底是 最近连续3天 还是只要有连续3天 就行,如果是像你描述的 最近连续3天 应该会简单好多
需求到底是 最近连续3天 还是只要有连续3天 就行,如果是像你描述的 最近连续3天 应该会简单好多
只要连续三天就行,一定是最近的。上个月出现连续登录的三天也可以算是连续登录。
其实如果要加上最近这个条件,只要再最原始的数据表中对logon_data进行最近3天 这个条件先筛选一次就可以了吧?这样以前连续3天以上的登录记录就砍掉了。
8 小时前
![]() javaanddonet 楼主 LV27楼
javaanddonet 楼主 LV27楼
hyj 发表于 2018-4-26 11:16
这里先说下思路,看表中已经对数据排序了。也就是分别按照用户名和日期排序。首先根据第一条记录,也就是起 ...
这里先说下思路,看表中已经对数据排序了。也就是分别按照用户名和日期排序。首先根据第一条记录,也就是起 ...
| 这里先说下思路,看表中已经对数据排序了。也就是分别按照用户名和日期排序。 首先根据第一条记录,也就是起始日期。然后通过日期函数自增,与数据库中日期比较(疑问:这里的与数据库中的期是指?)。 如果自增日期等于当前日期(疑问:这里的当前日期是指?),说明是连续的,继续比较。直到找到大于当前日期(疑问:知道找到谁大于当前日期?)。这就说明不连续。当然连续三天的话,再加个过滤条件就可以了。 能帮忙解释一下吗?多谢~ |
8 小时前
![]() hyj8楼
hyj8楼
javaanddonet 发表于 2018-4-26 11:42
这里先说下思路,看表中已经对数据排序了。也就是分别按照用户名和日期排序。
首先根据第一条记录,也就是起始日期。然后通过日期函数自增,与数据库中日期比较 (疑问:这里的与数据库中的期是指?)。这里是指 LOGON_DATE字段的日期数据,我们新增了一个(字段)数据,就是 连续日期。详细如下
USER_ID USER_NAME LOGON_DATE
-------------------------------- -------------------------------- -----------
1 ZhangSan 4/1/2018
1 ZhangSan 4/2/2018
1 ZhangSan 4/4/2018
1 ZhangSan 4/5/2018
1 ZhangSan 4/7/2018
2 LiSi 4/15/2018
2 LiSi 4/16/2018
2 LiSi 4/17/2018
3 WangWu 4/8/2018
3 WangWu 4/9/2018
3 WangWu 4/10/2018
3 WangWu 4/11/2018首先获取张三的日期,初始日期为4/1/2018,然后初始日期+1,这个是第二天,这个操作是我们自增的。也就是 4/2/2018,这时候跟数据中的下一条数据对比 4/2/2018 ,正好二者相等,这说明是连续的,然后我们接着自增 4/3/2018 ,这时候第三条数据为 4/4/2018,而自增的是 4/3/2018,这说明到此为止,到第三条已经不连续,这个记录就不符了。
-------------------------------- -------------------------------- -----------
1 ZhangSan 4/1/2018
1 ZhangSan 4/2/2018
1 ZhangSan 4/4/2018
1 ZhangSan 4/5/2018
1 ZhangSan 4/7/2018
2 LiSi 4/15/2018
2 LiSi 4/16/2018
2 LiSi 4/17/2018
3 WangWu 4/8/2018
3 WangWu 4/9/2018
3 WangWu 4/10/2018
3 WangWu 4/11/2018首先获取张三的日期,初始日期为4/1/2018,然后初始日期+1,这个是第二天,这个操作是我们自增的。也就是 4/2/2018,这时候跟数据中的下一条数据对比 4/2/2018 ,正好二者相等,这说明是连续的,然后我们接着自增 4/3/2018 ,这时候第三条数据为 4/4/2018,而自增的是 4/3/2018,这说明到此为止,到第三条已经不连续,这个记录就不符了。
如果自增日期等于当前日期 (疑问:这里的当前日期是指?【这个当前日志,也就是数据库中,上面例子LOGON_DATE的数据】),说明是连续的,继续比较。直到找到大于当前日期 (疑问:知道找到谁大于当前日期?【如上面示例,自增是 4月3号,数据中却是 4月4号,所以证明不连续】)。这就说明不连续。当然连续三天的话,再加个过滤条件就可以了。
5 小时前
![]() hyj9楼
hyj9楼
楼主的方法其实也是可以的。我这里主要是增加了一个自增日期。楼主t.logon_date+1 这个其实也是自增。当然这个可能涉及到游标,实现难度比较大一些。特别纯sql语句。如果结合代码就容易多了
5 小时前
![]() javaanddonet 楼主 LV210楼
javaanddonet 楼主 LV210楼
hyj 发表于 2018-4-26 14:30
楼主的方法其实也是可以的。我这里主要是增加了一个自增日期。楼主t.logon_date+1 这个其实也是自增。当然 ...
楼主的方法其实也是可以的。我这里主要是增加了一个自增日期。楼主t.logon_date+1 这个其实也是自增。当然 ...
恩,我明白你的意思了。你的思路要借助游标来实现,对吧。
我刚才有研究了一下分组排序的方法也可以实现。先说一下思路:
分组排序后,的结果如下,其实就是在原有的数据中增加了一个虚拟的列:根据userid分组后的每条记录在当前分组中的序号。然后我将每一行的logon_date - 它在组内的序号,这样就可以得到一个日期,在同一个组中,如果这个日期是相同的,那么就说明了该组中的logon_data是连续的。否则不是连续的,具体sql如下:
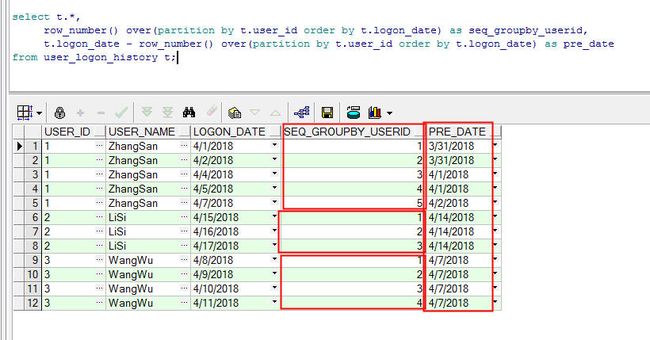
基于上面的结果,可以在查询一次,使用group by having 子句就可以得到结果。根据user_id, user_name, 相减后得到的日期 三个字段分组进行count聚合函数的统计,sql如下:
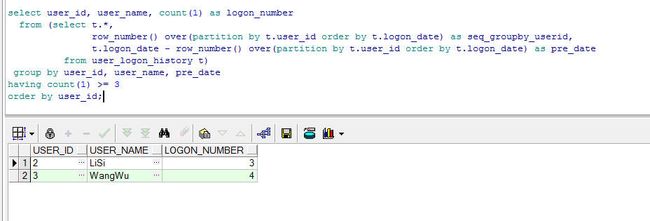
转:
http://wsq.discuz.com/?siteid=264104844&c=index&a=viewthread&tid=24418&source=pcscan