mysql核心内幕第七章-查询解析与优化器
查询优化器是指生成查询计划的子系统,该子系统通常完全处于服务器端,根据要参与连接(join)的表、数据读取方式(所殷读取或表扫描)和索引选择等因素制定查询计划。以基于开销的优化器为例,数据库查询优化器的任务是,通过产生可供选择的多个执行计划,并从中选出最低估算开销的执行计划,来优化一条SQL语句。这在数据库系统和SQL语句性能表现上扮演了至关重要的角色。
MySQL解析器
MySQL解析器主要有两部分组成:
- 词法分析(Lexical Analysis 或 Scanner)
- 语法分析(Syntax Analysis 或 Parser)
词法分析阶段是MySQL解析SQL语句过程的第一个阶段。这个阶段的任务是从左到右一个字符、一个字符地读入源输入,即对构成源程序的字符流进行扫描,然后根据构词规则识别单词(也称单词符号或符号)。词法分析程序实现这个任务。词法分析程序可以使用 lex 或 GNU 开源的 Flex 等工具自动生成。
语法分析是MySQL解析过程的第二个阶段,该过程是一个逻辑阶段。语法分析的任务是在词法分析的基础上将单词序列组合成各类语法短语,如“程序”,“语句”,“表达式”等。语法分析程序判断源程序在结构上是否正确。源程序的结构由上下文五官文法描述。语法分析常用Bison工具自动处理。
词法分析程序将整个查询语句分解成各类标志,语法分析根据定义的系统语言将“各类标志”转为对MySQL有意义的组合(Item类)。最后系统生成一个语法树,语法树便是优化器依赖的数据结构。
下面是一个查询语句的例子:
SELECT name FROM faculty f, classes c where f.id = c.fac_id AND f.department_id = 'CS' AND c.semester = 'F2001';这个查询语句的作用是找到计算机专业在2001年秋季的所有课程名
语法分析程序检查输入的字节流,并将整个字节流转为各类标志。对于上面的这个查询,标志如下:
- SELECT
- name
- FROM
- faculty
- f
- classes
- c
- WHERE
- f
- .
- id
- =
- c
- .
- fac_id
- AND
- f
- .
- department_id
- =
- CS
- AND
- c
- .
- semester
- =
- F2001
所有这些标志在MySQL内部都是一个对象。它们都属于Item类的子类,例如关键字、字符串、数字和操作符等。语法分析器(Parser)根据设定的规则,组合这些标志。在本例中,select语句的语法规则可在sql/sql_yacc.cc中找到。最终sql/sql_yacc.cc得到的语法树如下图:
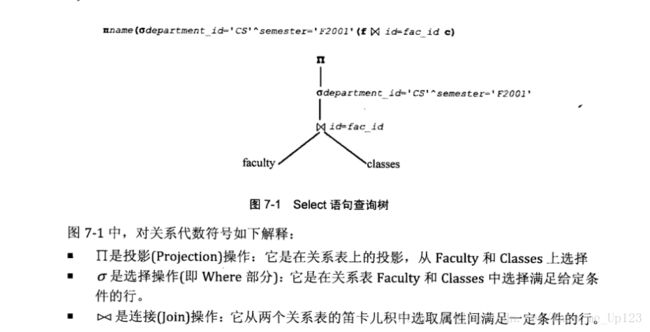
词法分析程序
sql/lex.h 中定义了 MySQL 关键字:
static SYMBOL symbols[] = {
{“&&”, SYM(AND_AND_SYM)},
{“<”, SYM(LT)},
{“<=”, SYM(LE)},
{“<>”, SYM(NE)},
{“!=”, SYM(NE)},
{“=”, SYM(EQ)},
{“>”, SYM(GT_SYM)},
{“>=”, SYM(GE)},
{“<<”, SYM(SHIFT_LEFT)},
{“>>”, SYM(SHIFT_RIGHT)},
{“ACTION”, SYM(ACTION)},
{“ADD”, SYM(ADD)},
…
}
sql/lex.h 中定义的MySQL函数关键字:
static SYMBOL sql_function[] = {
“ADDDATE”, SYM(ADDDATE_SYM)},
“COUNT”, SYM(COUNT_SYM),
“EXTRACT”, SYM(EXTRACT_SYM),
“MAX”, SYM(MAX_SYM),
“MIN”, SYM(MIN_SYM),
“NOW”, SYM(NOW_SYM),
}
语法分析器
MySQL的语法规则使用了GNU Bison 工具。在sql/sql_yaacc.yy中我们可以找到 MySQL 的语法定义,MySQLL利用 sql_yacc.yy 生成 sql_yacc.cc文件。语法分析器从 yyparse 开始执行。
例子:几个常见的类
如下,是SELECT 和 UNION 操作的解析:
UNION 表达式 := (SELECT 表达式|UNION 表达式) UNION (SELECT 表达式|UNIOIN表达式)
SELECT 表达式 := SELECT (SELECT 表达式*)- MySQL 用 SELECT 结点来代表一个 SELECT 查询,而用一个 UNIT 结点来代表一个 UNION 操作符或者 SELECT 下的子查询;
- LEX::unit 为根节点,LEX::select_lex 指向 SQL 中的第一个 SELECT 语句。
下面举例说明 MySQL 解析 select 和 union 后生成的解析树:

以下说明 JOIN 类和 TABLE_LIST 类
在 MySQL 的解析树中,MySQL 将所有查询语句都理解成 JOIN操作。这里的 JOIN 比 SQL 语句中的 JOIN 概念要广泛得多。在 SQL 语句中,我们对一个表的读取并不采用 JOIN 操作,而在解析树中,一个表也是 JOIN 操作。
TABLE_LIST 类是 TABLE 容器类,JOIN 操作使用的 TABLE 对象群被放置于 TABLE_LIST 中。TABLE_LIST 类的成员和方法如下:
JOIN 操作符具有下面的形式:
- JOIN 表达式 := (JOIN 表达式|JOIN嵌套) JOIN (JOIN 表达式|JOIN嵌套)
- JOIN 嵌套 := ‘(‘(表引用|JOIN表达式)(.表引用|JOIN表达式)*’)’ | 表引用
因此所有的JOIN 表达式都可以用JOIN 表达式和 JOIN 嵌套这两个基本结点来代表,如下图所示:

X,Y结点可以是 JOIN 表达式、JOIN 嵌套或表引用之一,而 ON (…)表达式一定在 Y 结点上。同时当 Y 为表引用时,也称之为内表(inner table)。nest_last_join 和 nested_join 都称之为“嵌套结点”。
查询优化器
采用优化器的主要原因:
- 优化器可以从数据字典中获取许多统计信息,例如表中的行数、表中的每个列的分布情况等。优化器可以根据这些信息选择有效的执行计划,而用户程序则难以获得这些信息;
- 优化器可以考虑百种不同的执行计划,而程序员一般只能考虑有限的几种可能;
- 优化器中包含了许多复杂的优化技术,这些优化技术往往比最好的程序员掌握的还要多。系统的自动优化相当于使得所有人都拥有这些优化技术。