hadoop HA集群安装部署
1.运行环境
1.1 软件环境
三个节点
OS:64位RHEL5及以上或者64位CentOS6.0及以上
JVM:预装64位JDK 1.8及以上版本
1.2 浏览器要求
Firefox 39.0.0版本及以上或者Google Chrome 54.0.2840.8版本及以上。
BEH-Manager-4.1.2安装包于官方网站下载:http://beh.pezy.cn/
2 安装准备
2.1准备虚拟机
准备三个节点的虚拟机
2.2 修改主机名
在各个节点执行以下操作来修改主机名,使集群下的主机有格式一个统一的主机名,以便后续的操作和维护
修改主机名
vi /etc/sysconfig/network
192.168.xx.210 ha01
(其它俩台分别修改自己的ha02 ha03)
修改host映射
vi /etc/hosts
192.168.xx.210 ha01
192.168.xx.220 ha02
192.168.xx.230 ha03
W5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1dhbmdaaGFvTG9uZ2pr,size_16,color_FFFFFF,t_70)2.3 关闭防火墙
service iptables stop
chkconfig iptables off
2.4 配置时间同步
yum –y install ntpdate
ntpdate pool.ntp.org
2.5 配置ssh免秘登录
yum –y install openssh-clients
ssh-keygen –t rsa
ssh-copy-id ha0x(记得给自己和其它俩台都要发)
2.6 安装jdk
自己安装(记得配置环境变量)
3 安装其他组件
3.1 安装zookeeper
注:以下所有安装默认是在ha01上执行!
- 解压软件包
将zookeeper-3.4.6.tar.gz 解压缩,
tar -zxvf zookeeper-3.4.6.tar.gz –C /usr/local/
- 修改配置文件(在ha01执行)
修改Zookeeper配置文件/usr/local/zookeeper3.4.6/conf/zoo_sample.cfg重名为zoo.cfg。
mv zoo_sample.cfg zoo.cfg
修改zoo.cfg,添加如下内容
server.1=ha01:2888:3888
server.2=ha02:2888:3888
server.3=ha03:2888:3888
- 创建相关目录
创建/tmp/zookeeper目录,并在此目录下创建myid文件。
mkdir /tmp/zookeeper
cd /tmp/zookeeper
vi myid
在文件中写入数字
![]()
4. 分发zookeeper软件包
scp -r /usr/local/zookeeper-3.4.6 ha02:/usr/local
scp -r /usr/local/zookeeper-3.4.6 ha03:/usr/local
5. 修改myid文件
到ha2与ha3上重复三步骤,分别把myid修改为2,3
6.启动Zookeeper
在ha01,ha02,ha03上执行
zkServer.sh start
查看进程QuorumPeerMain是否启动![]()
查看zookeeper状态
3.2 安装高可用hadoop
hadoop部分的配置分为两部分hdfs和yarn。
3.2.1 HDFS
6. 修改配置文件
修改core-site.xml(如果文件不存在,但是core-site.xml.template文件存在,则先修改文件名,执行mv core-site.xml.template core-site.xml)
vi /usr /local/hadoop-2.7.3/etc/hadoop/core-site.xml
修改为以下内容:
fs.defaultFS
hdfs://beh
false
hadoop.tmp.dir
/usr/local/hadoopdata
false
ha.zookeeper.quorum
ha01:2181,ha02:2181,ha03:2181
false
修改hdfs-site.xml
vi /usr/local/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
修改为以下内容:
dfs.nameservices
beh
false
dfs.ha.namenodes.beh
nn1,nn2
false
dfs.namenode.rpc-address.beh.nn1
ha01:9000
false
dfs.namenode.http-address.beh.nn1
ha01:50070
false
dfs.namenode.rpc-address.beh.nn2
ha02:9000
false
dfs.namenode.http-address.beh.nn2
ha02:50070
false
dfs.namenode.shared.edits.dir
qjournal://ha01:8485;ha02:8485;ha03:8485/beh
false
dfs.ha.automatic-failover.enabled.beh
true
false
dfs.client.failover.proxy.provider.beh
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
false
dfs.journalnode.edits .dir
/usr/local/metadata/journal
false
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
false
dfs.ha.fencing.ssh.private-key-files
/usr/local/.ssh/id_rsa
true
dfs.replication
2
false
修改slaves
vi /usr/local/hadoop-2.7.3/etc/hadoop/slaves
修改为以下内容:
ha02
ha03
3.2.2 YARN
修改mapred-site.xml
vi /usr/local/hadoop2.7.3/etc/hadoop/mapred-site.xml
修改为以下内修改为以下内容:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
ha02:10020
mapreduce.jobhistory.webapp.address
ha03:19888
yarn.app.mapreduce.am.staging-dir
/usr/local/metadata/hadoop-yarn/staging
修改yarn-site.xml
vi /usr/local/hadoop2.7.3/etc/hadoop/yarn-site.xml
修改为以下内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.local-dirs
/usr/local/metadata/yarn
yarn.nodemanager.log-dirs
/usr/local/logs/yarn/userlogs
yarn.log-aggregation-enable
true
Where to aggregate logs
yarn.nodemanager.remote-app-log-dir
hdfs://beh/var/log/hadoop-yarn/apps
yarn.resourcemanager.connect.retry-interval.ms
2000
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.cluster-id
beh
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.ha.id
rm1
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk.state-store.address
ha01:2181,ha02:2181,ha03:2181
yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms
5000
yarn.resourcemanager.address.rm1
ha01:23140
yarn.resourcemanager.scheduler.address.rm1
ha01:23130
yarn.resourcemanager.webapp.https.address.rm1
ha01:23189
yarn.resourcemanager.webapp.address.rm1
ha01:23188
yarn.resourcemanager.resource-tracker.address.rm1
ha01:23125
yarn.resourcemanager.admin.address.rm1
ha01:23141
yarn.resourcemanager.address.rm2
ha02:23140
yarn.resourcemanager.scheduler.address.rm2
ha02:23130
yarn.resourcemanager.webapp.https.address.rm2
ha02:23189
yarn.resourcemanager.webapp.address.rm2
ha02:23188
yarn.resourcemanager.resource-tracker.address.rm2
ha02:23125
yarn.resourcemanager.admin.address.rm2
ha02:23141
mapreduce.shuffle.port
23080
yarn.resourcemanager.zk-address
ha01:2181,ha02:2181,ha03:2181
修改环境变量
**vim /usr/local/hadoop-2.7.3/etc/hadoop/hadoop-env.sh
vim /usr/local/hadoop-2.7.3/etc/hadoop/yarn-env.sh**
修改为以下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_102
3.2.3 分发配置文件
scp -r /usr/local/hadoop2.7.3 ha02:/usr/local
scp -r /usr/local/hadoop2.7.3 ha03:/usr/local
注:将以上配置复制到所有节点
3.2.4 启动HDFS
启动journalnode(进程名:JournalNode)
注 (这个要在3台全部运行)如果配了环境变量就不用打sbin
sbin/hadoop-daemon.sh start journalnode
格式化zookeeper,![]()
对ha01节点进行格式化和启动启动namenode(进程名:NameNode):
hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
对ha02节点进行格式化和启动
hdfs namenode -bootstrapStandby
sbin/hadoop-daemon.sh start namenode
**在ha01和ha02上启动zkfc服务(zkfc服务进程名:DFSZKFailoverController):此时ha01和ha02就会有一个节点变为active状态**
sbin/hadoop-daemon.sh start zkfc
启动datanode(进程名:DataNode):在ha01上执行
sbin/hadoop-daemons.sh start datanode
3.2.5 验证是否成功
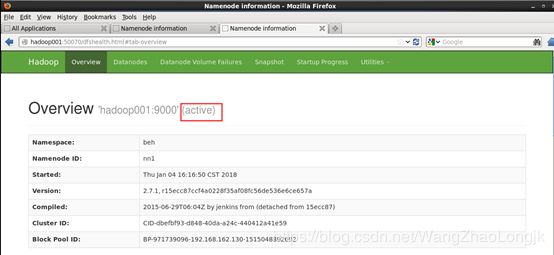
打开浏览器,访问 hadoop1:50070 以及 hadoop2:50070,你将会看到两个namenode一个是active而另一个是standby。
然后kill掉其中active的namenode进程,另一个standby的naemnode将会自动转换为active状态
ha02:50070
或端口号
192.168.83.140:50070
 3.2.6 启动yarn
3.2.6 启动yarn
在hadoop1上启动(此脚本将会启动hadoop1上的resourcemanager及所有的nodemanager)
$HADOOP_HOME/sbin/start-yarn.sh
在hadoop2上启动resourcemanagerl
$HADOOP_HOME/sbin/yarn-daemon.sh start resourcemanager
3.2.7 验证是否配置成功
打开浏览器,访问ha01:23188或者ha02:23188,只有active的会打开如下界面,standby的那个不会看到页面。
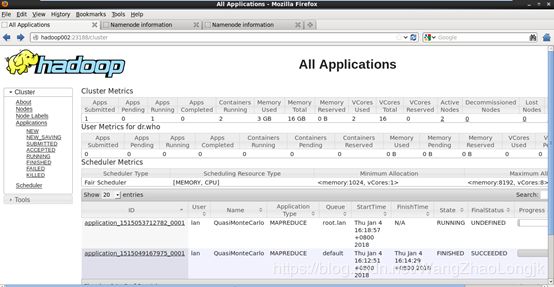
然后kill掉active的resourcemanager另一个将会变为active的,说明resourcemanager HA是成功的