从一次 FULL GC 卡顿谈对服务的影响
Full GC 的时间和次数是管理java的应用服务不得不考虑的问题,高吞吐量和低停顿是追求高质量服务重要目标,从而会有根据业务的特点衍生出各种垃圾回收器。在实战中如何根据如何使用ParNew ,CMS等回收器和配置各种参数,要在理论结合实践中不断优化。
一、问题的发现
看到线上的服务机器一些节点时不时地有TCP报警 ,所以我们断定是TCP的连接出现了问题。
让我们来回顾一下TCP的三次握手和四次挥手,借网上的一个图:
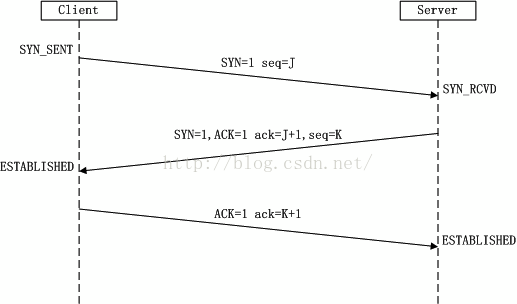
当第一次握手,建立半连接状态:
client 通过 connect 向 server 发出 SYN 包时,client 会维护一个 socket 队列,如果 socket 等待队列满了,而 client 也会由此返回 connection time out,只要是 client 没有收到 第二次握手SYN+ACK,3s 之后,client 会再次发送,如果依然没有收到,9s 之后会继续发送。
此时server 会维护一个 SYN 队列,半连接 syn 队列的长度为 max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog) ,在机器的tcp_max_syn_backlog值在/proc/sys/net/ipv4/tcp_max_syn_backlog下配置,当 server 收到 client 的 SYN 包后,会进行第二次握手发送SYN+ACK 的包加以确认,client 的 TCP 协议栈会唤醒 socket 等待队列,发出 connect 调用。
当第三次握手时,当server接收到ACK 报之后, 会进入一个新的叫 accept 的队列,该队列的长度为 min(backlog, somaxconn),默认情况下,somaxconn 的值为 128,表示最多有 129 的 ESTAB 的连接等待 accept(),而 backlog 的值则应该是由 int listen(int sockfd, int backlog) 中的第二个参数指定,listen 里面的 backlog 可以有我们的应用程序去定义的。
那么我们的RPC服务的thrift协议封装定义在TCP这层的backlog的大小是50。
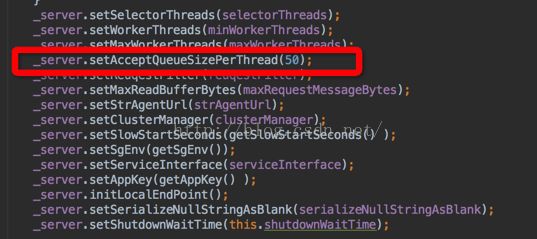
同样通过,ss -l可以知道Send-Q 表示的则是最大的 listen backlog 数值,这就就是上面提到的 min(backlog, somaxconn) 的值。
当 accept 队列满了之后,即使 client 继续向 server 发送 ACK 的包,也会不被相应,此时,server 通过 /proc/sys/net/ipv4/tcp_abort_on_overflow 来决定如何返回,0 表示直接丢丢弃该 ACK,1 表示发送 RST 通知 client;相应的,client 则会分别返回 read timeout 或者 connection reset by peer。
总的来说:可以看到,整个 TCP 连接中我们的Server端 有如下的两个 queue:
1. 一个是 半连接队列:(syn queue) queue(max(tcp_max_syn_backlog, 64)),用来保存 SYN_SENT 以及 SYN_RECV 的信息。
2. 另外一个是完全连接队列: accept queue(min(somaxconn, backlog)),保存 ESTAB 的状态,那么建立连接之后,我们的应用服务的线程就可以accept()处理业务需求了。
那么回到报警的问题,通过监控观察发现,每次报警都会和一次full gc的时间点吻合,而且full time达几秒,到先线上去看一下我们服务的线程数,没有到高峰期,但业务线程就会达到200+,在高并发的情况下,可以想像所有的服务线程暂停导致对上面的accept队列堆积的影响。
可知,服务由于full gc 暂停卡顿引起的tcp连接 ,看看GC日志同样验证问题。
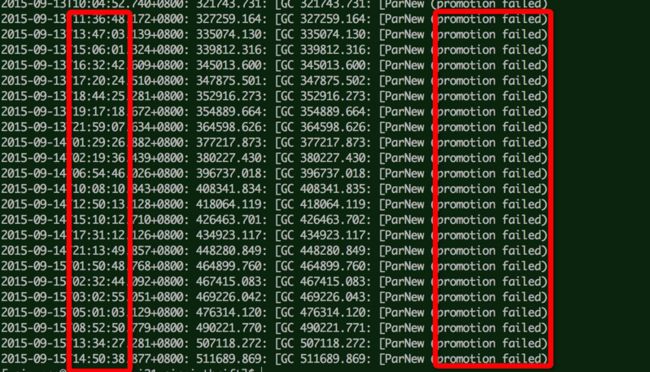
发现这时服务都没有监控了。可能卡住了,监控也不上报了。
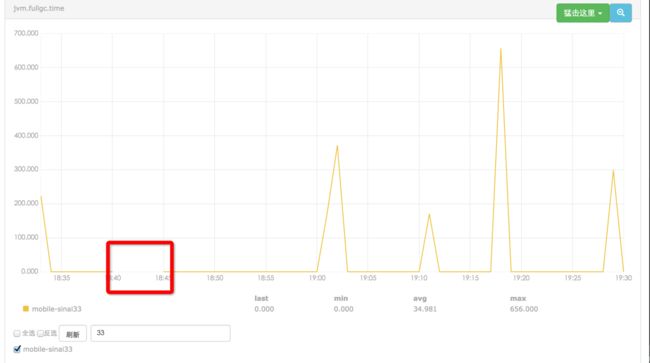
可以看出问题的原因是由于promotion failed,concurrent mode failure或promotion failed 会导致一次full gc,而gc time 回达数秒。下面两种情况都会转向Full GC,网站停顿时间较长
垃圾回收时promotion failed是个比较严重问题,一般可能是两种原因产生。
第一个原因是救助空间不够,救助空间里的对象还不应该被移动到年老代,但年轻代又有很多对象需要放入Survivor救助空间;
第二个原因是年老代没有足够的空间接纳来自年轻代的对象;这两种情况都会转向Full GC,网站停顿时间较长。
线上机器JVM 参数配置:
JVM_GC="-XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:ParallelCMSThreads=4 -XX:CMSInitiatingOccupancyFraction=80 -XX:+CMSParallelRemarkEnabled -XX:+ExplicitGCInvokesConcurrent -XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled"
JVM_SIZE="-Xms4500m -Xmx4500m"
JVM_HEAP="-XX:PermSize=128m -XX:MaxPermSize=256m -XX:SurvivorRatio=8 -XX:NewRatio=3" 根据上面介绍了promontion faild产生的原因是EDEN空间不足的情况下将EDEN与From survivor中的存活对象存入To survivor区时,To survivor区的空间不足,再次晋升到old gen区,而old gen区内存也不够的情况下产生了promontion faild从而导致full gc.那可以推断出:eden+from survivor < old gen区剩余内存时,不会出现promontion faild的情况,即:
(Xmx-Xmn)*(1-CMSInitiatingOccupancyFraction/100)>=(Xmn-Xmn/(SurvivorRatior+2)) 进而推断出:
CMSInitiatingOccupancyFraction <=((Xmx-Xmn)-(Xmn-Xmn/(SurvivorRatior+2)))/(Xmx-Xmn)*100(只有这个公式满足时才有可能不会promontion faild)
按线上配置计算,((Xmx-Xmn)-(Xmn-Xmn/(SurvivorRatior+2)))/(Xmx-Xmn)*100=73%,所以有时后young区大对象到old区,因为线上– XX:CMSInitiatingOccupancyFraction =80, 而这时old区恰好到大于73%,空间不足,会发生promontion faild。
二、优化的第一步
实验策略:CMSInitiatingOccupancyFraction调整为70,这样单纯的修改XX:CMSInitiatingOccupancyFraction阀值,目的是尝试更早的对old区开始收集,已避免上面提到的情况:在回收完成之前,堆没有足够空间分配。
发布到线上,观察一段时间,发现日志没有了promontion faild,但是full gc times和count并没有明显的变化。
三、优化的第二步
上面方法不太好,因为没有用到救助空间,所以年老代容易满,CMS执行会比较频繁。我改善了一下,还是用救助空间,但是把救助空间加大,这样也不会有promotion failed。为了解决暂停问题和promotion failed问题,最后设置-XX:SurvivorRatio=1 ,并把MaxTenuringThreshold去掉,这样即没有暂停又不会有promotoin failed,而且更重要的是,年老代和永久代上升非常慢(因为好多对象到不了年老代就被回收了),所以CMS执行频率非常低,好近小时才执行一次,这样,服务器都不用重启了。
JVM_GC="-XX:+PrintGC -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintTenuringDistribution -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=1 -XX:ParallelCMSThreads=4 -XX:CMSInitiatingOccupancyFraction=56 -XX:+CMSParallelRemarkEnabled -XX:+ExplicitGCInvokesConcurrent -XX:+CMSPermGenSweepingEnabled -XX:+CMSClassUnloadingEnabled"
JVM_SIZE="-Xms4500m -Xmx4500m"
JVM_HEAP="-Xmn1500m -XX:PermSize=128m -XX:MaxPermSize=256m -XX:SurvivorRatio=1"参数解释说明:
-XX:CMSInitiatingOccupancyFraction=60(尝试更早的对old区开始收集,已避免上面提到的情况:在回收完成之前,堆没有足够空间分配)
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=1(CMS垃圾回收会产生脆片,GC的时候整理一下)
-Xmn1500m(增加年轻态的内存空间)
-XX:SurvivorRatio=1(MaxTenuringThreshold去掉,这样即没有暂停又不会有promotoin failed,而且更重要的是,年老代和永久代上升非常慢)
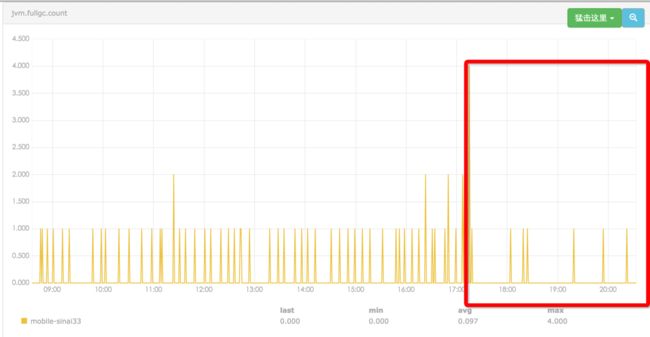
四、优化的第三步
(1)调整缓存过期时间
dump内存发现,IdServer对象比较大,这个是定时更新任务引起。一般的,gc的行为和代码的结构及内存中的对象有很大的关系,代码中用了guava的本地缓存对象达几百M,11分钟会更新一次,每当做一次数据的更新,会产生大对象到old区,会promotion failed 导致full gc,现在根据业务特点调整cache时间为1小时。
(2)调整JVM参数只是一方面,更应该精简代码层面去优化,减少内存使用率
下一步要把,这个本地缓存进行精简,清楚一些没有必要的对象,节约内存,如果必须的可考虑使用序列化后本地缓存只保存序列化后的版本,在使用该对象的时候进行反序列化。
五、总结
CMS的另一个缺点是它需要更大的堆空间。因为CMS标记阶段应用程序的线程还是在执行的,那么就会有堆空间继续分配的情况,为了保证在CMS回收完堆之前还有空间分配给正在运行的应用程序,必须预留一部分空间。也就是说,CMS不会在老年代满的时候才开始收集。相反,它会尝试更早的开始收集,已避免上面提到的情况:在回收完成之前,堆没有足够空间分配!默认当老年代使用68%的时候,CMS就开始行动了。 X:CMSInitiatingOccupancyFraction =n 来设置这个阀值,总得来说,CMS回收器减少了回收的停顿时间,但是降低了堆空间的利用率。