Linux入门小抄-part5.3-Shell编程进阶(上)
Shell操作日期时间
date - linux系统为我们提供了一个命令date,专门用来显示或者设置系统日期时间的。
语法格式为:
date [OPTION]... [+FORMAT] 或者 date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
常用的可选项有:
--help:显示辅助信息
--version:显示date命令版本信息
-u:显示目前的格林威治时间
-d:做日期时间相关的运算
--date='-dateStr':做日期时间的相关运算
用法举例:
- 显示当前系统的日期时间
[root@hadoop ~]# date ![]()
- 以指定的格式显示日期时间
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S' ![]()
- 设置系统日期时间
[root@hadoop ~]# date -s "2018-01-01 01:01"
[root@hadoop ~]# date --set="208-01-01 01:01"
- 有时候,我们操作日期时间,经常会要获取前几天或者后几天的时间,那么date命令也给我们提供了实现这个功能的可选项'-d'和'--date',请看下面细细的例子
-
-d:
--date:
## 获取:下一天的时间
[root@hadoop ~]# date -d next-day '+%Y-%m-%d %H:%M:%S'
[root@hadoop ~]# date -d 'next day' '+%Y-%m-%d %H:%M:%S'
另外一种写法:
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S' -d tomorrow
## 获取上一天的时间
[root@hadoop ~]# date -d last-day '+%Y-%m-%d %H:%M:%S'
另外一种写法:
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S' -d yesterday
## 获取下一月的时间
[root@hadoop ~]# date -d next-month '+%Y-%m-%d %H:%M:%S'
## 获取上一月的时间
[root@hadoop ~]# date -d last-month '+%Y-%m-%d %H:%M:%S'
## 获取下一年的时间
[root@hadoop ~]# date -d next-year '+%Y-%m-%d %H:%M:%S'
## 获取上一年的时间
[root@hadoop ~]# date -d last-year '+%Y-%m-%d %H:%M:%S'
## 获取上一周的日期时间:
[root@hadoop ~]# date -d next-week '+%Y-%m-%d %H:%M:%S'
[root@hadoop ~]# date -d next-monday '+%Y-%m-%d %H:%M:%S'
[root@hadoop ~]# date -d next-thursday '+%Y-%m-%d %H:%M:%S'
那么类似的,其实,last-year,last-month,last-day,last-week,last-hour,last-minute,last-second都有对应的实现。相反的,last对应next,自己可以根据实际情况灵活组织
## 获取一天以后的日期时间
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S' --date='1 day'
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S' --date='-1 day ago'
## 获取一天以前的日期时间
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S' --date='-1 day'
[root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S' --date='1 day ago'
上面的例子显示出来了使用的格式,使用精髓在于改变前面的字符串显示格式,改变数据,改变要操作的日期对应字段,除了天也有对应的其他实现:year,month,week,day,hour,minute,second,monday(星期,七天都可)
-
- date 能用来显示或设定系统的日期和时间,在显示方面,使用者能设定欲显示的格式,格式设定为一个加号后接数个标记,其中可用的标记列表如下:
使用范例 : [root@hadoop ~]# date '+%Y-%m-%d %H:%M:%S'-
%a : 星期几 (Sun..Sat)
%A : 星期几 (Sunday..Saturday)
%b : 月份 (Jan..Dec)
%B : 月份 (January..December)
%c : 直接显示日期和时间
%d : 日 (01..31)
%D : 直接显示日期 (mm/dd/yy)
%h : 同 %b
%j : 一年中的第几天 (001..366)
%m : 月份 (01..12)
%U : 一年中的第几周 (00..53) (以 Sunday 为一周的第一天的情形)
%w : 一周中的第几天 (0..6)
%W : 一年中的第几周 (00..53) (以 Monday 为一周的第一天的情形)
%x : 直接显示日期 (mm/dd/yyyy)
%y : 年份的最后两位数字 (00.99)
%Y : 完整年份 (0000..9999)
%%: 打印出%
%n : 下一行
%t : 跳格
%H : 小时(00..23)
%k : 小时(0..23)
%l : 小时(1..12)
%M : 分钟(00..59)
%p : 显示本地AM或PM
%P : 显示本地am或pm
%r : 直接显示时间(12 小时制,格式为 hh:mm:ss [AP]M)
%s : 从 1970 年 1 月 1 日 00:00:00 UTC 到目前为止的秒数
%S : 秒(00..61)
%T : 直接显示时间(24小时制)
%X : 相当于%H:%M:%S %p
%Z : 显示时区
-
若是不以加号作为开头,则表示要设定时间,而时间格式为 MMDDhhmm[[CC]YY][.ss]
-
MM 为月份,
DD 为日,
hh 为小时,
mm 为分钟,
CC 为年份前两位数字,
YY 为年份后两位数字,
ss 为秒数
例子:date "050602032017.55"

-
-
- 有用的小技巧
-
## 获取相对某个日期前后的日期:
[root@hadoop ~]# date -d 'may 14 -2 weeks'
## 把时间当中无用的0去掉,比如:01:02:25会变成1:2:25
[root@hadoop ~]# date '+%-H:%-M:%-S'
## 显示文件最后被更改的时间
[root@hadoop ~]# date "+%Y-%m-%d %H:%M:%S" -r bin/removeJDK.sh
## 求两个字符串日期之间相隔的天数
[root@hadoop ~]#
expr '(' $(date +%s -d "2016-08-08") - $(date +%s -d "2016-09-09") ')' / 86400
expr `expr $(date +%s -d "2016-08-08") - $(date +%s -d "2016-09-09")` / 86400
r
## shell中加减指定间隔单位
[root@hadoop ~]# A=`date +%Y-%m-%d`
[root@hadoop ~]# B=`date +%Y-%m-%d -d "$A +48 hours"`
-
高级文本处理命令
1、wc
功能: 统计文件行数、字节、字符数
常用选项:
-l:统计多少行
-w:统计字数
-c:统计文件字节数,一个英文字母1字节,一个汉字占2-4字节(根据编码)
-m:统计文件字符数,一个英文字母1字符,一个汉字占1个字符
-L:统计最长行的长度, 也可以统计字符串长度
-help:显示帮助信息
--version:显示版本信息
注意:一个汉字到底几个字节?
| 占2个字节的:〇 占3个字节的:基本等同于GBK,含21000多个汉字 占4个字节的:中日韩超大字符集里面的汉字,有5万多个 一个utf8数字占1个字节 一个utf8英文字母占1个字节 |
演示:
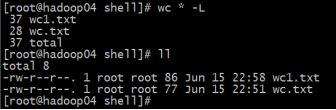
| 统计文件信息 [linux@linux ~]$ wc wc.txt 4 8 77 mingxing.txt 行数 单词数 字节数 文件名
统计字符串长度 [linux@linux ~]$ echo "hello" | wc -L 5
统计文件行数: [linux@linux ~]$ wc -l mingxing.txt 6 mingxing.txt
统计文件字数: [linux@linux ~]$ wc -w mingxing.txt 7 mingxing.txt |


2、sort
功能:排序文本,默认对整列有效
常用选项:
-f:忽略字母大小写,就是将小写字母视为大写字母排序
-M:根据月份比较,比如 JAN、DEC
-h:根据易读的单位大小比较,比如 2K、1G
-g:按照常规数值排序
-n:根据字符串数值比较
-r:倒序排序
-k:位置1,位置2根据关键字排序,在从第位置1开始,位置2结束
-t:指定分隔符
-u:去重重复行
-o:将结果写入文件
演示:
我们先准备一个sort.txt这个文件,里面的内容如下:
aaa:10:1.1
ccc:20:3.3
bbb:40:4.4
eee:40:5.5
ddd:30:3.3
bbb:40:4.4
fff:30:2.2具体使用:
| [linux@linux ~]$ cat sort.txt ## 准备排序文件,查看该内容 aaa:10:1.1 ccc:20:3.3 bbb:40:4.4 eee:40:5.5 ddd:30:3.3 bbb:40:4.4 fff:30:2.2
[linux@linux ~]$ sort sort.txt ## 直接排序,把整行当做一列字符串,字典顺序 aaa:10:1.1 bbb:40:4.4 bbb:40:4.4 ccc:20:3.3 ddd:30:3.3 eee:40:5.5 fff:30:2.2
[linux@linux ~]$ sort -nk 2 -t : sort.txt ## 以:作为分隔符,取第二个字段按照数值进行排序 aaa:10:1.1 ccc:20:3.3 fff:30:2.2 ddd:30:3.3 bbb:40:4.4 bbb:40:4.4 eee:40:5.5
[linux@linux ~]$ sort -nk 2 -u -t : sort.txt ## 和上一个不一样的是-u为了去重 aaa:10:1.1 ccc:20:3.3 ddd:30:3.3 bbb:40:4.4
多列排序:以:分隔,按第二列数值排倒序,第三列正序 [linux@linux ~]$ sort -n -t: -k2,2r -k3 sort.txt bbb:40:4.4 bbb:40:4.4 eee:40:5.5 fff:30:2.2 ddd:30:3.3 ccc:20:3.3 aaa:10:1.1 |
3、uniq
功能:去除重复行,只会统计相邻的
常用选项:
-c:打印出现的次数
-d:只打印重复行
-u:只打印不重复行
-D:只打印重复行,并且把所有重复行打印出来
-f N:比较时跳过前N列
-i:忽略大小写
-s N:比较时跳过前N个字符
-w N:对每行第N个字符以后内容不做比较
演示:
这里我们也准备一个文件uniq.txt,里面的内容如下:
abc
xyz
cde
cde
xyz
abd具体操作:
例子1:
| [linux@linux ~]$ uniq uniq.txt ## 直接去重,只能在相邻行去重 abc xyz cde xyz abd
[linux@linux ~]$ sort uniq.txt | uniq ## 先给文件排序,然后去重 abc abd cde xyz
[linux@linux ~]$ sort uniq.txt | uniq -c ## 打印每行重复次数 1 abc 1 abd 2 cde 2 xyz
[linux@linux ~]$ sort uniq.txt | uniq -u -c ## 打印不重复行,并给出次数 1 abc 1 abd
[linux@linux ~]$ sort uniq.txt | uniq -d -c ## 打印重复行,并给出次数 2 cde 2 xyz
[linux@linux ~]$ sort uniq.txt | uniq -w 2 ## 以开头前两个字符为判断标准去重 abc cde xyz |
例子2:
这里我们准备两个文件:a.txt ,b.txt ,内容如下
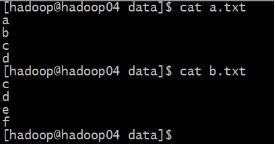
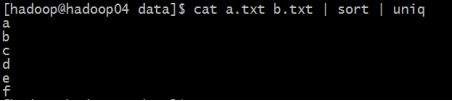
| 需求: 求两个文件的交集: [hadoop@hadoop04 data]$ cat a.txt b.txt | sort | uniq -d
求两个文件的并集: [hadoop@hadoop04 data]$ cat a.txt b.txt | sort | uniq
求a.txt和b.txt的差集 [hadoop@hadoop04 data]$ cat a.txt b.txt b.txt | sort | uniq -u
求b.txt和a.txt的差集 [hadoop@hadoop04 data]$ cat b.txt a.txt a.txt | sort | uniq -u
|
4、cut
cut命令可以从一个文本文件或者文本流中提取文本列
cut语法
cut -d'分隔字符' -f fields ## 用于有特定分隔字符
cut -c 字符区间 ## 用于排列整齐的信息
选项与参数:
-d:后面接分隔字符。与 -f 一起使用
-f:依据 -d的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思
-c:按照字符截取
-b:按照字节截取
例子:
| 首先看PATH变量: [root@localhost ~]# echo $PATH /usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
将PATH变量取出,找出第五个路径 [root@localhost ~]# echo $PATH | cut -d ':' -f 5 /usr/sbin
将PATH变量取出,找出第三和第五个路径,以下三种方式都OK [root@localhost ~]# echo $PATH | cut -d ':' -f 3,5 [root@localhost ~]# echo $PATH | cut -d : -f 3,5 [root@localhost ~]# echo $PATH | cut -d: -f3,5 /sbin:/usr/sbin
将PATH变量取出,找出第三到最后一个路径 [root@localhost ~]# echo $PATH | cut -d ':' -f 3- /sbin:/bin:/usr/sbin:/usr/bin:/root/bin
将PATH变量取出,找出第一到第三,还有第五个路径 [root@localhost ~]# echo $PATH | cut -d ':' -f 1-3,5 /usr/local/sbin:/usr/local/bin:/sbin:/usr/sbin |
| 先准备已空格分开的这么段数据: 黄渤 huangbo 18 jiangxi 徐峥 xuzheng 22 hunan 王宝强 wangbaoqiang 44 liujiayao
获取中间的年龄: [root@localhost ~]# cut -f 3 -d ' ' cut.txt 18 22 44
获取第二个字符到第五个字符之间的字符: [root@localhost ~]# cut -c 2-5 cut.txt 渤 hu 峥 xu 宝强 w
获取第四个字节到第六个字节中的字符: [root@hadoop ~]# cut -b 4-6 cut.txt 渤 峥 宝 |