安装,使用hadoop集群遇到的坑(vSphere虚拟化环境)
安装,使用hadoop集群遇到的坑(vSphere虚拟化环境)
(文章不定期更新)
1 环境概述
服务器:LENOVO ThinkServer RD540
虚拟化环境:Esxi5.5
虚拟机系统:Ubuntu 16.04LTS
虚拟机配置:
| 节点 | 处理器 | 内存 | 硬盘 |
|---|---|---|---|
| master | 全部 | 8G | 200G |
| slave10 | 全部 | 8G | 200G |
| slave20 | 全部 | 4G | 130G |
| slave30 | 全部 | 4G | 130G |
| slave40 | 全部 | 4G | 130G |
以上由于slave1-4的名称在局域网中已经被占用,则名后加0
2 坑
2.1 Esxi时断时连
装好Esxi后,在vSphere界面初步安装环境,却发现时断时连。如下图:
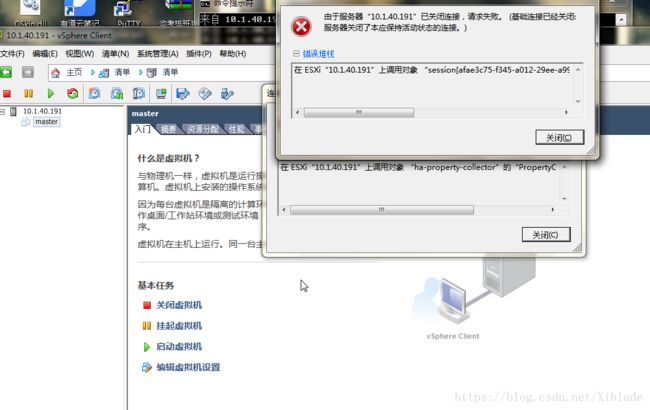
在连接过程中时不时会抛出异常。
而且在传输大文件必定无法成功:
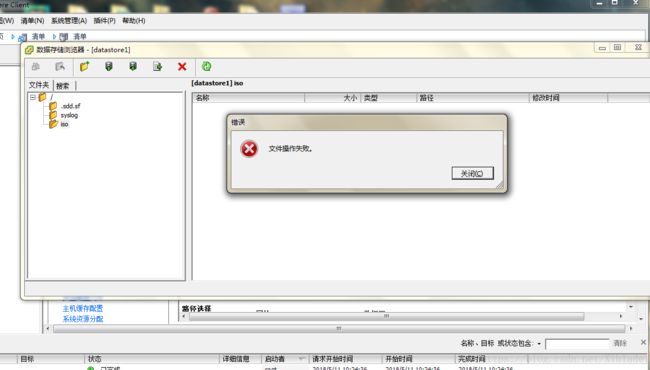
查看Esxi的hostd日志,有:
2018-05-11T02:30:00.023Z [FFE215B0 verbose ‘Statssvc.vim.PerformanceManager’] HostCtl Exception in stats collection. Turn on ‘trivia’ log for details
2018-05-11T02:30:02.219Z [FFE84B70 verbose ‘SoapAdapter’] Responded to service state request
2018-05-11T02:30:20.023Z [FFE215B0 verbose ‘Statssvc.vim.PerformanceManager’] HostCtl Exception in stats collection: Sysinfo error on operation returned status : Not initialized. Please see the VMkernel log for detailed error information
这个Exception指示去Kernel日志中获取详细信息。再查看Esxi的kernel日志:
/var/log # cat vmkernel.log | grep fail
2018-05-10T12:14:09.089Z cpu4:33645)ScsiDeviceIO: 2337: Cmd(0x412e803d1ac0) 0x85, CmdSN 0xa from world 34572 to dev “naa.600605b007e0a4201dfcf3440b1aeec1” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0.
2018-05-10T12:14:09.089Z cpu4:33645)ScsiDeviceIO: 2337: Cmd(0x412e803d1ac0) 0x4d, CmdSN 0xb from world 34572 to dev “naa.600605b007e0a4201dfcf3440b1aeec1” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0.
2018-05-10T12:14:09.089Z cpu4:33645)ScsiDeviceIO: 2337: Cmd(0x412e803d1ac0) 0x1a, CmdSN 0xc from world 34572 to dev “naa.600605b007e0a4201dfcf3440b1aeec1” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x24 0x0.
2018-05-10T12:14:09.099Z cpu4:33645)ScsiDeviceIO: 2337: Cmd(0x412e803d1ac0) 0x85, CmdSN 0xd from world 34572 to dev “naa.50000395a802efd4” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0.
2018-05-10T12:44:09.180Z cpu2:32848)ScsiDeviceIO: 2337: Cmd(0x412e82722980) 0x85, CmdSN 0x14 from world 34572 to dev “naa.600605b007e0a4201dfcf3440b1aeec1” failed H:0x0 D:0x2 P:0x0 Valid sense data: 0x5 0x20 0x0.
其中的数字是SCSI感知代码:
http://pubs.vmware.com/vsphere-50/index.jsp?topic=%2Fcom.vmware.vsphere.troubleshooting.doc_50%2FGUID-E8304C8B-E2EA-459E-A545-8531C1BF12B0.html
看样子好像是硬盘的问题。
官方也给出了详细的排查方案【ESX/ESXi 主机出现间歇性网络连接或无网络连接 (2077745)】
https://kb.vmware.com/s/article/2077745
有中文,不过排查方案略微繁杂,这里不推荐。
这边的方案是:直接在服务器上抹掉Esxi,安装Ubuntu系统,发现ssh一样时断时连,且xftp传输大文件必定失败,失败瞬间ping不通,过一段时间又可以ping通:
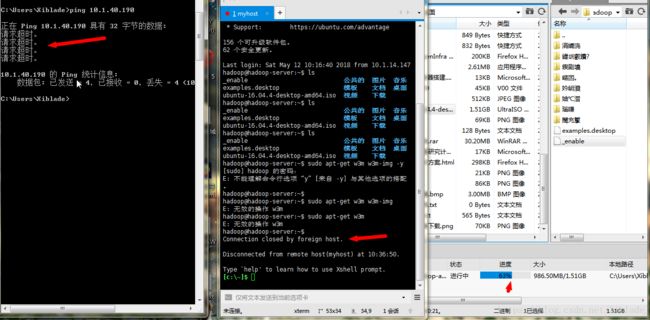
由此确定是网口问题
解决方案:拔掉两根网线,其中一根插到备用网卡的网口,问题解决。
2.2 hadoop集群可正常启动,但无法感知Slave节点
按照:
1. https://blog.csdn.net/dream_an/article/details/52946840
2. https://www.cnblogs.com/caiyisen/p/7373512.html
两位同行的技术博客搭建起hadoop。
启动虚拟集群。
master节点:
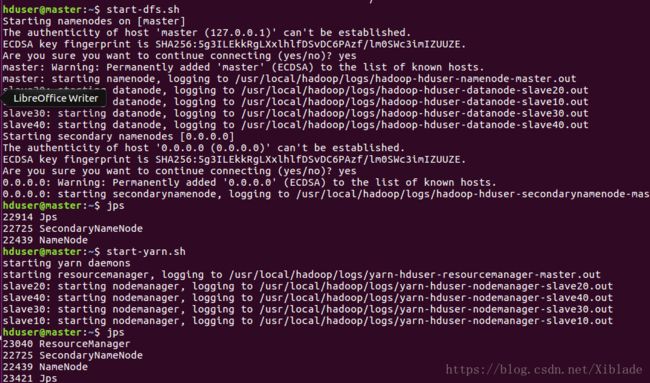
无明显问题
查看下Slave节点:

无明显问题
尝试在hdfs文件系统中建立用户目录没有问题,上传文件抛java异常:
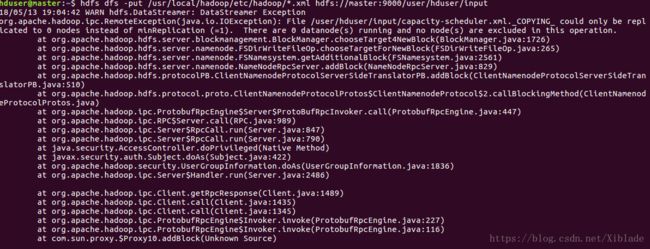
There are 0 Datanode(s) running…
发现不对,查看Slave节点相关日志:

子节点虽然有DataNode的子进程,但一直在尝试重连:
Problem connecting to the server master:…/9000
在主节点浏览器输入hdfs://master:9000可以看到页面,但在子节点浏览器无法看到页面。猜测是9000端口只允许本机访问, 并不允许其他机器访问。
参考https://blog.csdn.net/yjc_1111/article/details/53817750这篇文章
在主节点运行
cat /etc/hosts
发现定义了两个master的ip地址:
127.0.0.1 master
外网ip master
将127.0.0.1端口去掉即可访问,也即本机解析本机的地址,除了localhost, 其他位置都不用本机回环口,而是用本机配置的ip。
否则,节点将无法访问master:9000
在上述文章当中,可访问某个端口的ip范围没有弄清楚,不知道如何看。
2.3 yarn 出现FINISHED的State与FAILED的FinalStatus
出现这种情况的原因有很多。
2018年5月初,笔者开始安装了2.8.3的hadoop。发现yarn出现未知情况的FAILED:

Diagnose没有任何显示,事件类型显示TA_CONTAINER_COMPLETED。
已于stackoverflow公开了问题,没有回复:
https://stackoverflow.com/questions/50364279/mapreduce-job-to-yarn-got-finished-state-and-failed-finalstatus
尔后根据相关资料,据说是2.8.3版本问题,具体是内存或者其他资源分配不足造成:
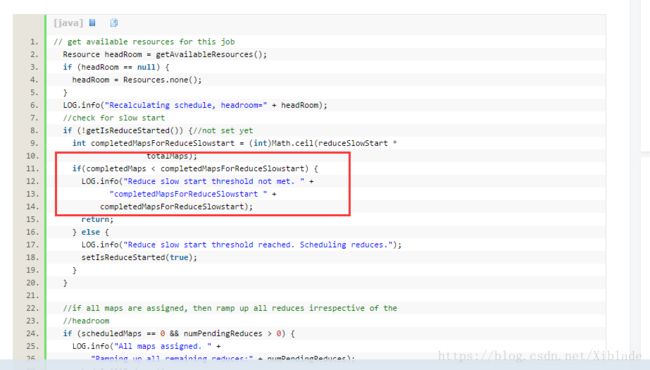
重装hadoop,替换版本为2.6.3
开启yarn,运行后仍然出现Failed,查看日志,发现:
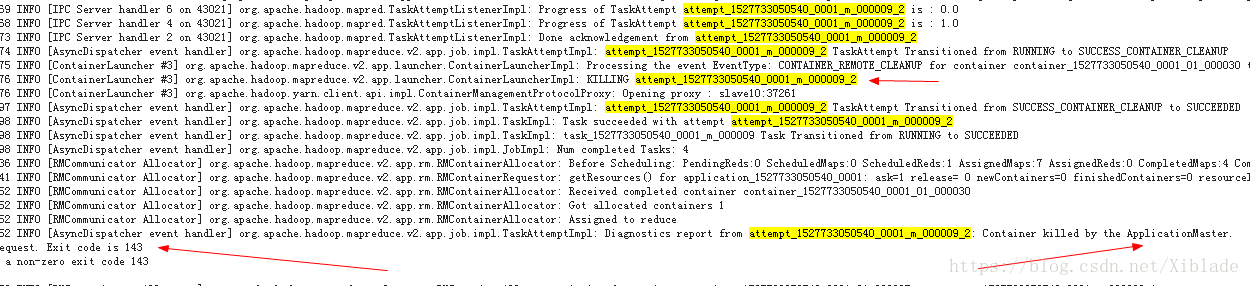
诊断原因已经显示了,为Container killed by the AppcationMaster。Exit code 是143。
Google相关问题结果:
https://stackoverflow.com/questions/15281307/the-reduce-fails-due-to-task-attempt-failed-to-report-status-for-600-seconds-ki
没有按照第一项描述修改超时时间,而是按照第二项修改了mapred.child.java.opts为-Xmx2048
尔后出现VMEM不够的问题:

遇到这种问题首先考虑调节分配比例:
https://blog.csdn.net/lively1982/article/details/50598847
yarn.nodemanager.vmem-pmem-ratio 改为6
调节完毕之后,又出现了FAILED问题:
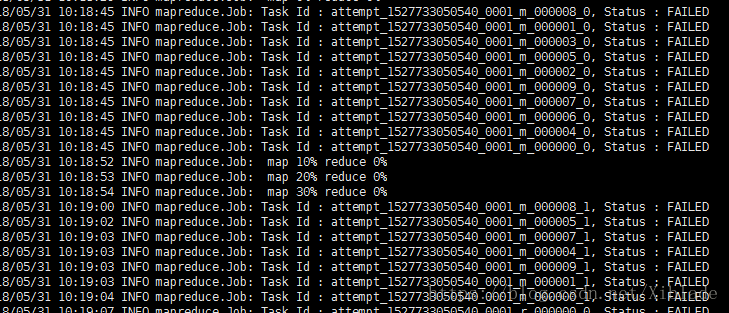
查看日志:
![]()
诊断没有结果,但Attempt变成了FAIL_CONTAINER_CLEANUP
以该关键词查询相关信息:
https://stackoverflow.com/questions/42416921/hadoop-mapreduce-teragen-fail-container-cleanup
stackoverflow明确有结果:干掉本机环回口。
注释掉master和slave的localhost一行后,问题解决。
2.4 执行hql命令,查询大表内存不足
MapReduce Total cumulative CPU time: 0 days 5 hours 51 minutes 10 seconds 340 msec
Ended Job = job_1527733050540_0066 with errors
Error during job, obtaining debugging information...
Examining task ID: task_1527733050540_0066_m_000000 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_m_000040 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_m_000010 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_m_000025 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_m_000037 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_m_000046 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000009 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000020 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000028 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000036 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000042 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000004 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000022 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000039 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000004 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000025 (and more) from job job_1527733050540_0066
Examining task ID: task_1527733050540_0066_r_000034 (and more) from job job_1527733050540_0066
Task with the most failures(4):
-----
Task ID:
task_1527733050540_0066_r_000023
URL:
http://master:8088/taskdetails.jsp?jobid=job_1527733050540_0066&tipid=task_1527733050540_0066_r_000023
-----
Diagnostic Messages for this Task:
Container [pid=23997,containerID=container_1527733050540_0066_01_000167] is running beyond virtual memory limits. Current usage: 1.1 GB of 1 GB physical memory used; 7.5 GB of 6 GB virtual memory used. Killing container.
Dump of the process-tree for container_1527733050540_0066_01_000167 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 24690 24003 23997 23997 (java) 0 0 4036775936 148677 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx2048m -Djava.io.tmpdir=/home/hduser/hadoop/nm-local-dir/usercache/hduser/appcache/application_1527733050540_0066/container_1527733050540_0066_01_000167/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/bigdata/hadoop-2.6.2/logs/userlogs/application_1527733050540_0066/container_1527733050540_0066_01_000167 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA org.apache.hadoop.mapred.YarnChild 10.1.40.192 42803 attempt_1527733050540_0066_r_000023_3 167
|- 24003 23997 23997 23997 (java) 23195 949 4036775936 148677 /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx2048m -Djava.io.tmpdir=/home/hduser/hadoop/nm-local-dir/usercache/hduser/appcache/application_1527733050540_0066/container_1527733050540_0066_01_000167/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/bigdata/hadoop-2.6.2/logs/userlogs/application_1527733050540_0066/container_1527733050540_0066_01_000167 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA org.apache.hadoop.mapred.YarnChild 10.1.40.192 42803 attempt_1527733050540_0066_r_000023_3 167
|- 23997 23995 23997 23997 (bash) 0 0 20090880 13 /bin/bash -c /usr/lib/jvm/java-8-openjdk-amd64/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx2048m -Djava.io.tmpdir=/home/hduser/hadoop/nm-local-dir/usercache/hduser/appcache/application_1527733050540_0066/container_1527733050540_0066_01_000167/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/bigdata/hadoop-2.6.2/logs/userlogs/application_1527733050540_0066/container_1527733050540_0066_01_000167 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA org.apache.hadoop.mapred.YarnChild 10.1.40.192 42803 attempt_1527733050540_0066_r_000023_3 167 1>/bigdata/hadoop-2.6.2/logs/userlogs/application_1527733050540_0066/container_1527733050540_0066_01_000167/stdout 2>/bigdata/hadoop-2.6.2/logs/userlogs/application_1527733050540_0066/container_1527733050540_0066_01_000167/stderr
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 54 Reduce: 57 Cumulative CPU: 21070.34 sec HDFS Read: 14377223631 HDFS Write: 6767047512 FAIL
Total MapReduce CPU Time Spent: 0 days 5 hours 51 minutes 10 seconds 340 msec
可以看到:
Current usage: 1.1 GB of 1 GB physical memory used; 7.5 GB of 6 GB virtual memory used. Killing container.
这意味着相关的物理内存和虚拟内存都分配不到位。
上网查询内存分配方法:
https://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/
https://stackoverflow.com/questions/21005643/container-is-running-beyond-memory-limits
参考了一些参数的含义
- 理解mapreduce.map.memory.mb、mapreduce.reduce.memory.mb:https://www.cnblogs.com/yesecangqiong/p/6274427.html
主要按照
* https://hortonworks.com/blog/how-to-plan-and-configure-yarn-in-hdp-2-0/
这个文章修改了各个参数
2.5 存储不足造成Unhealthy节点的问题
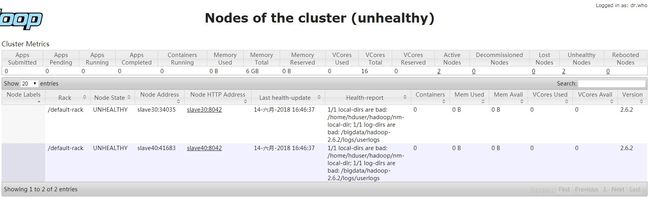
开始认为是设置了上述参数导致了节点不健康,在不健康的slave端运行df -h
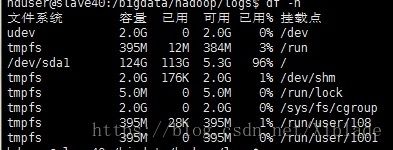
这说明因为存储超限。
查询相关资料,有各种方法:
- 虚拟机扩容:https://www.aliyun.com/jiaocheng/160232.html
- 降低副本数后进行节点均衡:http://blog.51cto.com/zlfwmm/1742213
- 修改上下限,禁止yarn报警的:https://blog.csdn.net/kaede1209/article/details/77881799
- 同上:修改上下限:https://stackoverflow.com/questions/29131449/why-does-hadoop-report-unhealthy-node-local-dirs-and-log-dirs-are-bad
- 修改完一切东西之后,还需要重新启动才行:https://blog.csdn.net/lazythinker/article/details/47832117
这里选择降低副本数,均衡,并重新在270G的硬盘中开辟了虚拟机。
按照
https://blog.csdn.net/chengyuqiang/article/details/79139432
执行了
hdfs dfs -setrep -w 2 /user
将user中的大文件冗余度都降低成2
重新拓展了一个虚拟机,hdfs存储扩充成了800G
节点恢复后,使用
start-balancer.sh
启动Balancer后台均衡进程。并在
$HADOOP_HOME/logs
目录中找到
hadoop-hduser-balancer-master.log
查看Balancer的进度。