深度学习笔记(一)——卷积神经网络(CNN)经典模型:Lenet
声明:博客中有参考其他大神的博客以及解释,非常感谢(侵删)!
本文根据五个经典的卷积神经网络模型的时间顺序进行介绍:
- Lenet,1986年;
- Alexnet,2012年;
- GoogleNet,2014年;
- VGG,2014年;
- Deep Residual Learning 2015年。
LeNet
1998年,LeCun提出LeNet,并成功应用于美国手写数字识别。但很快,CNN的锋芒被SVM和手工设计的局部特征盖过。早期的包括卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件。
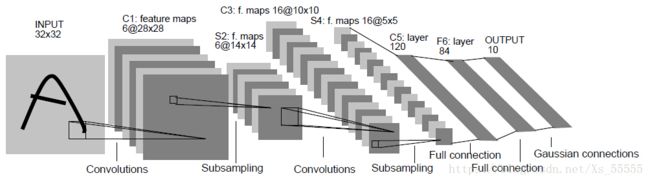
其中包括:
feature map 是指映射到的特征层,也就是输出通道
- 卷积层(conbolution):Input为32*32的图片,第一层卷积有6个5*5卷积核stride=1,所以(32-5)/1+1=28,第二层同样是5*5卷积核stride=1,输出通道是16,即生成了16个【(14-5)/1+1=】10*10的maps
- 池化层(subsampling):下采样层,使得输入缩小一倍。
- 全连接层(full connection):2个全连接层
import torch
import torchvision
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.autograd import Variable
from torch import optim
import torch.nn as nn
import torch.nn.functional as F
import time
import matplotlib.pyplot as plt
learning_rate = 1e-3
batch_size = 64
epoches = 50
trans_img = transforms.ToTensor()
trainset = MNIST('./minist/', train=True, transform=trans_img)
testset = MNIST('./minist/', train=False, transform=trans_img)
trainloader = DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=4)
testloader = DataLoader(testset, batch_size=batch_size, shuffle=False, num_workers=4)
# plt.imshow(trainset.train_data[0].numpy(), cmap='gray')
# plt.title('%i' % trainset.train_labels[0])
# plt.show()
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.fc = nn.Sequential(
nn.Linear(400, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
out = self.conv(x),
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
leNet = LeNet()
leNet.cuda()
Loss = nn.CrossEntropyLoss(size_average=False)
optimizer = torch.optim.SGD(leNet.parameters(), lr=learning_rate)
for i in range(epoches):
since = time.time()
running_loss = 0.
running_acc = 0.
for (img, label) in trainloader:
img = Variable(img).cuda()
label = Variable(label).cuda()
optimizer.zero_grad()
output = leNet(img)
loss = Loss(output, label)
# backward
loss.backward()
optimizer.step()
running_loss += loss.data[0]
_, predict = torch.max(output, 1)
correct_num = (predict == label).sum()
running_acc += correct_num.data[0]
running_loss /= len(trainset)
running_acc /= len(trainset)
print("[%d/%d] Loss: %.5f, Acc: %.2f, Time: %.1f s" %(i+1, epoches, running_loss, 100*running_acc, time.time()-since))注意!!!
def forward(self, x):
.........