文章目录
- 评估结果
- 1、贝叶斯
- 2、贝叶斯+TF-IDF
- 3、逻辑回归+词向量(FastText)
- 4、神经网络(CNN或RNN)
- 5、神经网络+词向量(FastText)
- 附录
评估结果
| 模型 |
时间 |
空间 |
精度 |
| 贝叶斯 |
1 |
高 |
0.83 |
| 逻辑回归 |
100 |
高 |
0.85 |
| 决策树 |
27 |
高 |
0.76 |
| 随机森林 |
16 |
高 |
0.78 |
| -------------------- |
-------------------- |
-------------------- |
-------------------- |
| 贝叶斯+TfIdf |
1 |
高 |
0.83 |
| 逻辑回归+TfIdf |
13 |
高 |
0.85 |
| 决策树+TfIdf |
30 |
高 |
0.76 |
| 随机森林+TfIdf |
16 |
高 |
0.80 |
| -------------------- |
-------------------- |
-------------------- |
-------------------- |
| 贝叶斯+FastText |
1 |
低 |
0.77 |
| 逻辑回归+FastText |
21 |
低 |
0.82 |
| 决策树+FastText |
6 |
低 |
0.71 |
| 随机森林+FastText |
23 |
低 |
0.80 |
| SVM+FastText |
22 |
低 |
0.83 |
| -------------------- |
-------------------- |
-------------------- |
-------------------- |
| 贝叶斯+Word2Vec |
1 |
低 |
0.78 |
| 逻辑回归+Word2Vec |
20 |
低 |
0.82 |
| 决策树+Word2Vec |
6 |
低 |
0.75 |
| 随机森林+Word2Vec |
23 |
低 |
0.81 |
| SVM+Word2Vec |
23 |
低 |
0.82 |
| -------------------- |
-------------------- |
-------------------- |
-------------------- |
| 贝叶斯+Word2Vec+TfIdf |
1 |
低 |
0.78 |
| 逻辑回归+Word2Vec+TfIdf |
60 |
低 |
0.83 |
| 决策树+Word2Vec+TfIdf |
7 |
低 |
0.75 |
| 随机森林+Word2Vec+TfIdf |
23 |
低 |
0.82 |
| SVM+Word2Vec+TfIdf |
51 |
低 |
0.85 |
| -------------------- |
-------------------- |
-------------------- |
-------------------- |
| CNN |
317(5 epoch) |
中 |
0.83 |
| GRU |
976(6 epoch) |
中 |
0.78 |
| -------------------- |
-------------------- |
-------------------- |
-------------------- |
| CNN+FastText |
181(4 epoch) |
中 |
0.81 |
| GRU+FastText |
1218(8 epoch) |
中 |
0.84 |
| CNN+Word2Vec |
134(3 epoch) |
中 |
0.81 |
| GRU+Word2Vec |
1159(8 epoch) |
中 |
0.84 |
| CNN+Word2Vec+TfIdf |
188(4 epoch) |
中 |
0.80 |
| GRU+Word2Vec+TfIdf |
1696(9 epoch) |
中 |
0.82 |
1、贝叶斯
from a_Data_preprocessing import load_xy, vocabs
from numpy import zeros
from b_metrics import metric, Timer
from sklearn.naive_bayes import MultinomialNB
"""数据加载、预处理"""
X_train, X_test, y_train, y_test = load_xy(1)
def ls_of_w2id(ls_of_wids):
length = len(ls_of_wids)
ls_of_wid = zeros((length, vocabs))
for i in range(length):
for wid in ls_of_wids[i]:
ls_of_wid[i, wid - 1] += 1
return ls_of_wid
X_train = ls_of_w2id(X_train)
X_test = ls_of_w2id(X_test)
"""建模"""
t = Timer()
clf = MultinomialNB()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
"""预测结果"""
metric(y_test, y_pred)
2、贝叶斯+TF-IDF
from a_Data_preprocessing import load_xy, vocabs
from gensim.corpora import Dictionary
from gensim.models import TfidfModel
from numpy import zeros
from sklearn.naive_bayes import MultinomialNB
from b_metrics import metric, Timer
"""数据加载、预处理"""
X_train, X_test, y_train, y_test = load_xy()
dt = Dictionary(X_train)
X_train = [dt.doc2bow(x) for x in X_train]
X_test = [dt.doc2bow(x) for x in X_test]
tfidf = TfidfModel(X_train).idfs
def ls_of_w2id(ls_of_wid):
length = len(ls_of_wid)
ls_of_idf = zeros((length, vocabs), dtype='float')
for i in range(length):
for (wid, cnt) in ls_of_wid[i]:
ls_of_idf[i, wid] += cnt * tfidf[wid]
return ls_of_idf
X_train = ls_of_w2id(X_train)
X_test = ls_of_w2id(X_test)
"""建模"""
t = Timer()
clf = MultinomialNB()
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
"""预测结果"""
metric(y_test, y_pred)
3、逻辑回归+词向量(FastText)
X = [[str(y)] + x for x, y in zip(X_train, y_train)]
model = FastText(X, size=size, window=window)
w2i = {w: i for i, w in enumerate(model.wv.index2word)}
vectors = model.wv.vectors
w2v = lambda w: vectors[w2i[w]]
X_train_v = [[w2v(w) for w in x] for x in X_train]
X_test_v = [[w2v(w) for w in x if w in w2i] for x in X_test]
with open(PATH_XY_VEC, 'wb') as f:
pickle.dump((X_train_v, X_test_v, y_train, y_test), f)
from a_Data_preprocessing import load_xy
from numpy import mean
from sklearn.linear_model import LogisticRegression
from b_metrics import metric, Timer
"""数据加载、预处理"""
X_train, X_test, y_train, y_test = load_xy(2)
X_train = [mean(x, axis=0) for x in X_train]
X_test = [mean(x, axis=0) for x in X_test]
"""建模"""
t = Timer()
clf = LogisticRegression()
clf.fit(X_train, y_train)
"""预测结果"""
y_pred = clf.predict(X_test)
metric(y_test, y_pred)
4、神经网络(CNN或RNN)
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Embedding, Dense
from tensorflow.python.keras.callbacks import EarlyStopping
from tensorflow.python.keras.utils import to_categorical
from numpy import argmax
from a_Data_preprocessing import load_xy, vocabs
from b_metrics import metric, Timer
"""配置"""
maxlen = 200
input_dim = vocabs + 1
output_dim = 100
batch_size = 256
epochs = 99
verbose = 2
patience = 1
callbacks = [EarlyStopping('val_acc', patience=patience)]
validation_split = .05
"""数据读取与处理"""
X_train, X_test, y_train, y_test = load_xy(1)
X_train = pad_sequences(X_train, maxlen)
X_test = pad_sequences(X_test, maxlen)
y_train = to_categorical(y_train, 9)
y_test = to_categorical(y_test, 9)
"""建模"""
from tensorflow.python.keras.layers import Conv1D, MaxPool1D, GlobalMaxPool1D
filters = 50
kernel_size = 10
model = Sequential(name='CNN')
model.add(Embedding(input_dim, output_dim, input_length=maxlen, input_shape=(maxlen,)))
model.add(Conv1D(filters, kernel_size * 2, padding='same', activation='relu'))
model.add(MaxPool1D(pool_size=2))
model.add(Conv1D(filters * 2, kernel_size, padding='same', activation='relu'))
model.add(GlobalMaxPool1D())
model.add(Dense(9, activation='softmax'))
model.summary()
"""编译、训练"""
timer = Timer()
model.compile('adam', 'categorical_crossentropy', ['acc'])
model.fit(X_train, y_train, batch_size, epochs, verbose, callbacks, validation_split)
"""结果打印"""
y_pred = model.predict(X_test)
metric(argmax(y_test, axis=1), argmax(y_pred, axis=1))
5、神经网络+词向量(FastText)
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.callbacks import EarlyStopping
from tensorflow.python.keras.utils import to_categorical
from numpy import argmax
from a_Data_preprocessing import load_xy, size
from b_metrics import metric, Timer
"""配置"""
maxlen = 200
output_dim = size
batch_size = 512
epochs = 99
verbose = 2
patience = 1
callbacks = [EarlyStopping('val_acc', patience=patience)]
validation_split = .05
"""数据读取与处理"""
X_train, X_test, y_train, y_test = load_xy(2)
X_train = pad_sequences(X_train, maxlen, dtype='float')
X_test = pad_sequences(X_test, maxlen, dtype='float')
y_train = to_categorical(y_train, 9)
y_test = to_categorical(y_test, 9)
"""建模"""
from tensorflow.python.keras.layers import Conv1D, MaxPool1D, GlobalMaxPool1D
filters = 50
kernel_size = 10
model = Sequential(name='CNN')
model.add(Conv1D(filters, kernel_size * 2, padding='same', activation='relu', input_shape=(maxlen, size)))
model.add(MaxPool1D(pool_size=2))
model.add(Conv1D(filters * 2, kernel_size, padding='same', activation='relu'))
model.add(GlobalMaxPool1D())
model.add(Dense(9, activation='softmax'))
model.summary()
"""编译、训练"""
timer = Timer()
model.compile('adam', 'categorical_crossentropy', ['acc'])
model.fit(X_train, y_train, batch_size, epochs, verbose, callbacks, validation_split)
"""结果"""
y_pred = model.predict(X_test)
metric(argmax(y_test, axis=1), argmax(y_pred, axis=1))
附录
模型评估模块
from time import time
from sklearn.metrics import classification_report, confusion_matrix
from a_Data_preprocessing import id2label
from seaborn import heatmap
from matplotlib import pyplot
from pandas import DataFrame
class Timer:
def __init__(self):
self.t = time()
def __del__(self):
print('\033[033m%.2f分钟\033[0m' % ((time() - self.t) / 60))
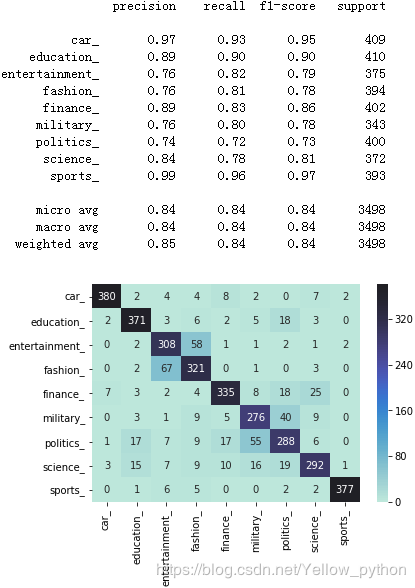
def metric(y_test, y_pred):
i2l = id2label()
y_test = [i2l[i] for i in y_test]
y_pred = [i2l[i] for i in y_pred]
report = classification_report(y_test, y_pred)
print(report)
labels = [i2l[i] for i in range(9)]
matrix = confusion_matrix(y_test, y_pred)
matrix = DataFrame(matrix, labels, labels)
heatmap(matrix, center=400, fmt='d', annot=True)
pyplot.show()
其它
-
首发日期
-
2019年5月9日
-
语料地址
-
https://github.com/AryeYellow/PyProjects/tree/master/tf2/新闻分类
-
TensorFlow版本
-
2.0 Preview