SqueezeNet运用到Faster RCNN进行目标检测
目录
-
- 目录
- 一SqueezeNet介绍
- MOTIVATION
- FIRE MODULE
- ARCHITECTURE
- EVALUATION
- 二SqueezeNet与Faster RCNN结合
- 三SqueezeNetFaster RCNNOHEM
- 原文链接
一、SqueezeNet介绍
论文提交ICLR 2017
论文地址:https://arxiv.org/abs/1602.07360
代码地址:https://github.com/DeepScale/SqueezeNet
注:代码只放出了prototxt文件和训练好的caffemodel,因为整个网络都是基于caffe的,有这两样东西就足够了。
在这里只是简要的介绍文章的内容,具体细节的东西可以自行翻阅论文。
MOTIVATION
在相同的精度下,模型参数更少有3个好处:
- More efficient distributed training
- Less overhead when exporting new models to clients
- Feasible FPGA and embedded deployment
即 高效的分布式训练、更容易替换模型、更方便FPGA和嵌入式部署。
鉴于此,提出3种策略:
- Replace 3x3 filters with 1x1 filters.
- Decrease the number of input channels to 3x3 filters.
- Downsample late in the network so that convolution layers have large activation maps.
即
- 使用1x1的核替换3x3的核,因为1x1核参数是3x3的1/9;
- 输入通道减少3x3核的数量,因为参数的数量由输入通道数、卷积核数、卷积核的大小决定。因此,减少1x1的核数量还不够,还需要减少输入通道数量,在文中,作者使用squeeze layer来达到这一目的;
- 后移池化层,得到更大的feature map。作者认为在网络的前段使用大的步长进行池化,后面的feature map将会减小,而大的feature map会有较高的准确率。
FIRE MODULE
由上面的思路,作者提出了Fire Module,结构如下: 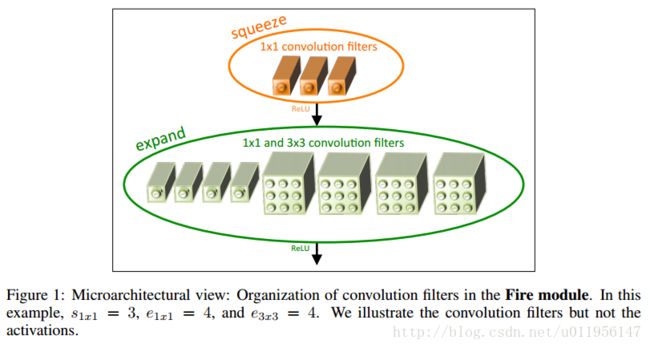
ARCHITECTURE
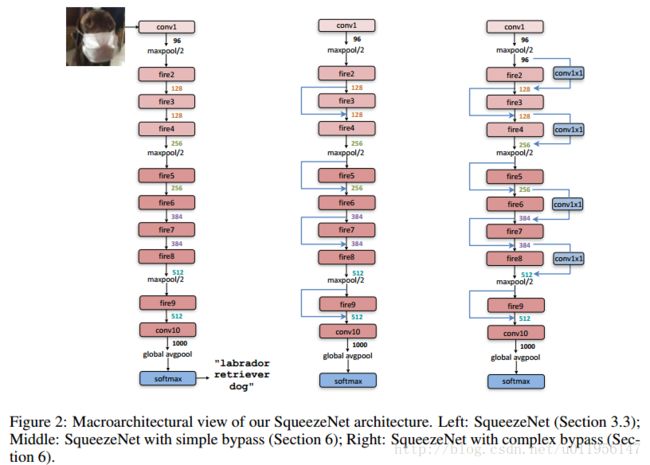
关于SqueezeNet的构建细节在文中也有详细的描述
- 为了3x3的核输出的feature map和1x1的大小相同,padding取1(主要是为了concat)
- squeezelayer和expandlayer后面跟ReLU激活函数
- Dropout比例为0.5,跟在fire9后面
- 取消全连接,参考NIN结构
- 训练过程采用多项式学习率(我用来做检测时改为了step策略)
- 由于caffe不支持同一个卷积层既有1x1,又有3x3,所以需要concat,将两个分辨率的图在channel维度concat。这在数学上是等价的
EVALUATION
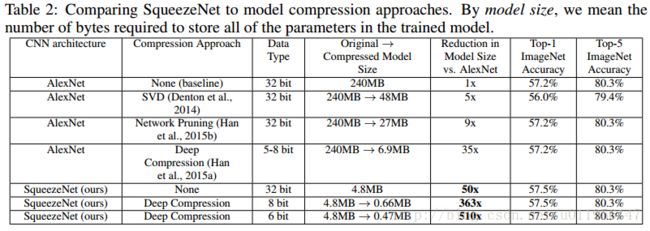
二、SqueezeNet与Faster RCNN结合
这里,我首先尝试的是使用alt-opt,但是很遗憾的是,出来的结果很糟糕,基本不能用,后来改为使用end2end,在最开始的时候,采用的就是faster rcnn官方提供的zfnet end2end训练的solvers,又很不幸的是,在网络运行大概400步后出现:
loss = NAN- 1
- 1
遇到这个问题,把学习率改为以前的1/10,解决。
直接上prototxt文件,前面都是一样的,只需要改动zfnet中的conv1-con5部分,外加把fc6-fc7改成squeeze中的卷积链接。
prototxt太长,给出每个部分的前面和后面部分:
name: "Alex_Squeeze_v1.1"
layer {
name: 'input-data'
type: 'Python'
top: 'data'
top: 'im_info'
top: 'gt_boxes'
python_param {
module: 'roi_data_layer.layer'
layer: 'RoIDataLayer'
param_str: "'num_classes': 4"
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 64
kernel_size: 3
stride: 2
}
}
.
.
.
layer {
name: "drop9"
type: "Dropout"
bottom: "fire9/concat"
top: "fire9/concat"
dropout_param {
dropout_ratio: 0.5
}
}
#========= RPN ============
layer {
name: "rpn_conv/3x3"
type: "Convolution"
bottom: "fire9/concat"
top: "rpn/output"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 256
kernel_size: 3 pad: 1 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
.
.
.
layer {
name: "drop9"
type: "Dropout"
bottom: "fire9/concat"
top: "fire9/concat"
dropout_param {
dropout_ratio: 0.5
}
}
#========= RPN ============
layer {
name: "rpn_conv/3x3"
type: "Convolution"
bottom: "fire9/concat"
top: "rpn/output"
param { lr_mult: 1.0 }
param { lr_mult: 2.0 }
convolution_param {
num_output: 256
kernel_size: 3 pad: 1 stride: 1
weight_filler { type: "gaussian" std: 0.01 }
bias_filler { type: "constant" value: 0 }
}
}
.
.
.
layer {
name: 'roi-data'
type: 'Python'
bottom: 'rpn_rois'
bottom: 'gt_boxes'
top: 'rois'
top: 'labels'
top: 'bbox_targets'
top: 'bbox_inside_weights'
top: 'bbox_outside_weights'
python_param {
module: 'rpn.proposal_target_layer'
layer: 'ProposalTargetLayer'
param_str: "'num_classes': 4"
}
}
#===================== RCNN =============
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "fire9/concat"
bottom: "rois"
top: "roi_pool5"
roi_pooling_param {
pooled_w: 7
pooled_h: 7
spatial_scale: 0.0625 # 1/16
}
}
layer {
name: "conv1_last"
type: "Convolution"
bottom: "roi_pool5"
top: "conv1_last"
param { lr_mult: 1.0 }
param { lr_mult: 1.0 }
convolution_param {
num_output: 1000
kernel_size: 1
weight_filler {
type: "gaussian"
mean: 0.0
std: 0.01
}
}
}
layer {
name: "relu/conv1_last"
type: "ReLU"
bottom: "conv1_last"
top: "relu/conv1_last"
}
layer {
name: "cls_score"
type: "InnerProduct"
bottom: "relu/conv1_last"
top: "cls_score"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 5
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "bbox_pred"
type: "InnerProduct"
bottom: "relu/conv1_last"
top: "bbox_pred"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 20
weight_filler {
type: "gaussian"
std: 0.001
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "loss_cls"
type: "SoftmaxWithLoss"
bottom: "cls_score"
bottom: "labels"
propagate_down: 1
propagate_down: 0
top: "loss_cls"
loss_weight: 1
}
layer {
name: "loss_bbox"
type: "SmoothL1Loss"
bottom: "bbox_pred"
bottom: "bbox_targets"
bottom: "bbox_inside_weights"
bottom: "bbox_outside_weights"
top: "loss_bbox"
loss_weight: 1
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
后面一部分的结构如图: 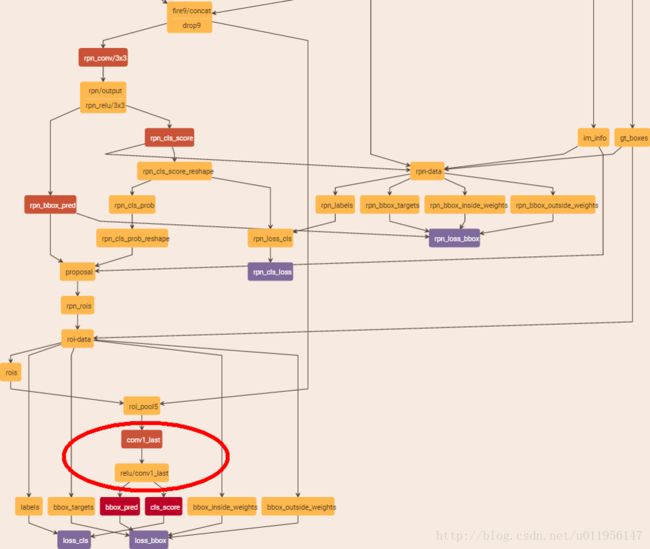
注意红圈部分,以前的fc换成了squ中的卷积层,这样网络参数大大减少,因为我改动了rpn部分选proposal的比例和数量,共采用改了70种选择,所以最后训练出来的模型为17M,比初始化4.8M大很多,不过也已经很小了。
三、SqueezeNet+Faster RCNN+OHEM
OHEM无非就是多了一个readonly部分,不过加上之后效果会好很多,和上面的方式一致,放出一部分prototxt,其他的课自行补上。从rpn那里开始,前面部分和上面给出的完全一样
#====== RoI Proposal ====================
layer {
name: "rpn_cls_prob"
type: "Softmax"
bottom: "rpn_cls_score_reshape"
top: "rpn_cls_prob"
}
layer {
name: 'rpn_cls_prob_reshape'
type: 'Reshape'
bottom: 'rpn_cls_prob'
top: 'rpn_cls_prob_reshape'
reshape_param { shape { dim: 0 dim: 140 dim: -1 dim: 0 } }
}
layer {
name: 'proposal'
type: 'Python'
bottom: 'rpn_cls_prob_reshape'
bottom: 'rpn_bbox_pred'
bottom: 'im_info'
top: 'rpn_rois'
python_param {
module: 'rpn.proposal_layer'
layer: 'ProposalLayer'
param_str: "'feat_stride': 16"
}
}
layer {
name: 'roi-data'
type: 'Python'
bottom: 'rpn_rois'
bottom: 'gt_boxes'
top: 'rois'
top: 'labels'
top: 'bbox_targets'
top: 'bbox_inside_weights'
top: 'bbox_outside_weights'
python_param {
module: 'rpn.proposal_target_layer'
layer: 'ProposalTargetLayer'
param_str: "'num_classes': 4"
}
}
##########################
## Readonly RoI Network ##
######### Start ##########
layer {
name: "roi_pool5_readonly"
type: "ROIPooling"
bottom: "fire9/concat"
bottom: "rois"
top: "pool5_readonly"
propagate_down: false
propagate_down: false
roi_pooling_param {
pooled_w: 6
pooled_h: 6
spatial_scale: 0.0625 # 1/16
}
}
layer {
name: "conv1_last_readonly"
type: "Convolution"
bottom: "pool5_readonly"
top: "conv1_last_readonly"
propagate_down: false
param {
name: "conv1_last_w"
}
param {
name: "conv1_last_b"
}
convolution_param {
num_output: 1000
kernel_size: 1
weight_filler {
type: "gaussian"
mean: 0.0
std: 0.01
}
}
}
layer {
name: "relu/conv1_last_readonly"
type: "ReLU"
bottom: "conv1_last_readonly"
top: "relu/conv1_last_readonly"
propagate_down: false
}
layer {
name: "cls_score_readonly"
type: "InnerProduct"
bottom: "relu/conv1_last_readonly"
top: "cls_score_readonly"
propagate_down: false
param {
name: "cls_score_w"
}
param {
name: "cls_score_b"
}
inner_product_param {
num_output: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "bbox_pred_readonly"
type: "InnerProduct"
bottom: "relu/conv1_last_readonly"
top: "bbox_pred_readonly"
propagate_down: false
param {
name: "bbox_pred_w"
}
param {
name: "bbox_pred_b"
}
inner_product_param {
num_output: 16
weight_filler {
type: "gaussian"
std: 0.001
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "cls_prob_readonly"
type: "Softmax"
bottom: "cls_score_readonly"
top: "cls_prob_readonly"
propagate_down: false
}
layer {
name: "hard_roi_mining"
type: "Python"
bottom: "cls_prob_readonly"
bottom: "bbox_pred_readonly"
bottom: "rois"
bottom: "labels"
bottom: "bbox_targets"
bottom: "bbox_inside_weights"
bottom: "bbox_outside_weights"
top: "rois_hard"
top: "labels_hard"
top: "bbox_targets_hard"
top: "bbox_inside_weights_hard"
top: "bbox_outside_weights_hard"
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
python_param {
module: "roi_data_layer.layer"
layer: "OHEMDataLayer"
param_str: "'num_classes': 4"
}
}
########## End ###########
## Readonly RoI Network ##
##########################
#===================== RCNN =============
layer {
name: "roi_pool5"
type: "ROIPooling"
bottom: "fire9/concat"
bottom: "rois_hard"
top: "roi_pool5"
propagate_down: true
propagate_down: false
roi_pooling_param {
pooled_w: 7
pooled_h: 7
spatial_scale: 0.0625 # 1/16
}
}
layer {
name: "conv1_last"
type: "Convolution"
bottom: "roi_pool5"
top: "conv1_last"
param {
lr_mult: 1.0
name: "conv1_last_w"
}
param {
lr_mult: 1.0
name: "conv1_last_b"
}
convolution_param {
num_output: 1000
kernel_size: 1
weight_filler {
type: "gaussian"
mean: 0.0
std: 0.01
}
}
}
layer {
name: "relu/conv1_last"
type: "ReLU"
bottom: "conv1_last"
top: "relu/conv1_last"
}
layer {
name: "cls_score"
type: "InnerProduct"
bottom: "relu/conv1_last"
top: "cls_score"
param {
lr_mult: 1
name: "cls_score_w"
}
param {
lr_mult: 2
name: "cls_score_b"
}
inner_product_param {
num_output: 4
weight_filler {
type: "gaussian"
std: 0.01
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "bbox_pred"
type: "InnerProduct"
bottom: "relu/conv1_last"
top: "bbox_pred"
param {
lr_mult: 1
name: "bbox_pred_w"
}
param {
lr_mult: 2
name: "bbox_pred_b"
}
inner_product_param {
num_output: 16
weight_filler {
type: "gaussian"
std: 0.001
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
name: "loss_cls"
type: "SoftmaxWithLoss"
bottom: "cls_score"
bottom: "labels_hard"
propagate_down: true
propagate_down: false
top: "loss_cls"
loss_weight: 1
}
layer {
name: "loss_bbox"
type: "SmoothL1Loss"
bottom: "bbox_pred"
bottom: "bbox_targets_hard"
bottom: "bbox_inside_weights_hard"
bottom: "bbox_outside_weights_hard"
top: "loss_bbox"
loss_weight: 1
propagate_down: false
propagate_down: false
propagate_down: false
propagate_down: false
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
结构图如下: 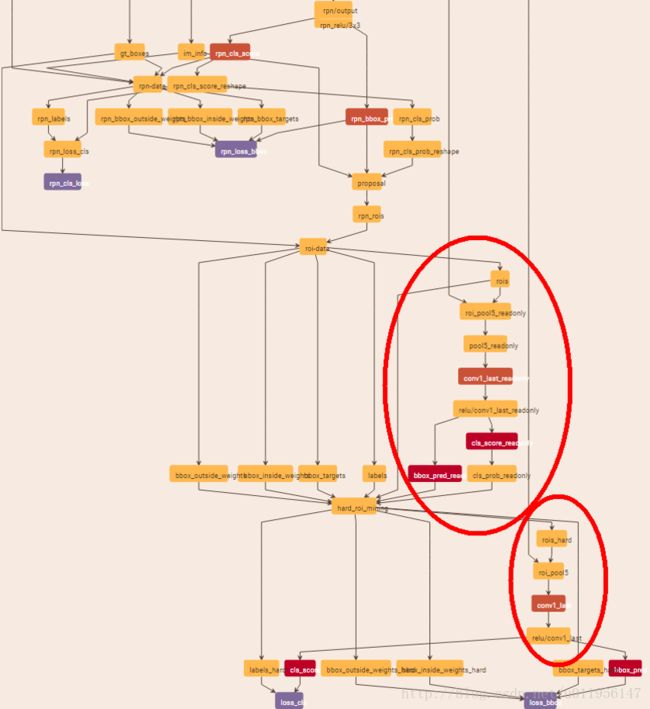
比前面训练的多一个readonly部分,具体可参考论文:
Training Region-based Object Detectors with Online Hard Example Mining
https://arxiv.org/abs/1604.03540 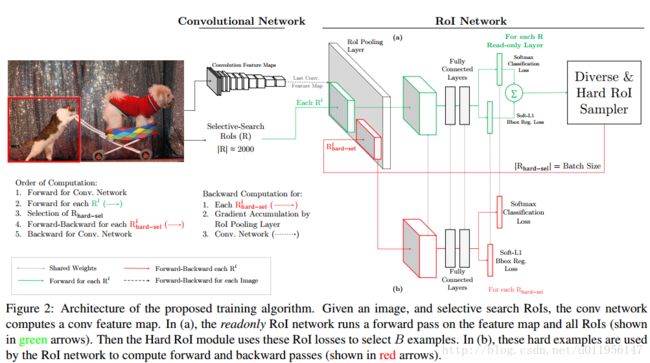
至此,SqueezeNet+Faster RCNN 框架便介绍完了,运行速度在GPU下大概是ZF的5倍,CPU下大概为2。5倍。
原文链接:
http://blog.csdn.net/u011956147/article/details/53714616