用网络爬虫爬取新浪新闻----Python网络爬虫实战学习笔记
今天学完了网易云课堂上Python网络爬虫实战的全部课程,特在此记录一下学习的过程中遇到的问题和学习收获。
我们要爬取的网站是新浪新闻的国内版首页
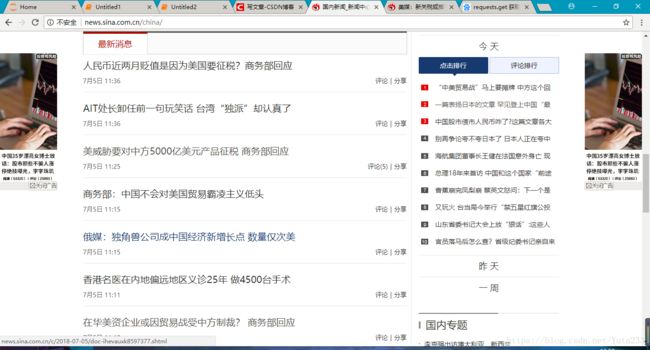
下面依次编写各个功能模块
1.得到某新闻页面下的评论数
评论数的数据是个动态内容,应该是存在服务器上,由js脚本传过来的,因此我们f12打开开发者工具在network下面找到js一栏,观察各个请求的preview页面,看看评论数包含在哪个请求中
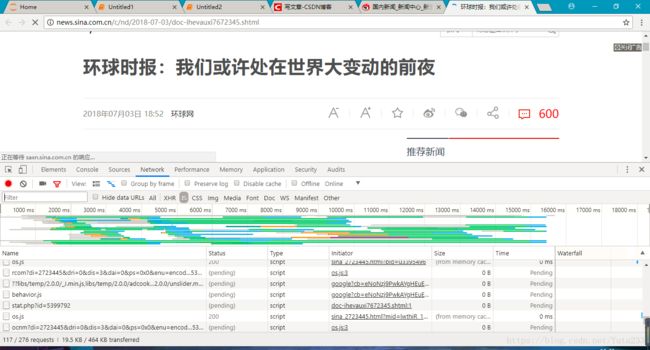
经过一番查找后,可以发现在这个请求中含有评论数目的数据,因此可以通过爬取这个请求获取评论数
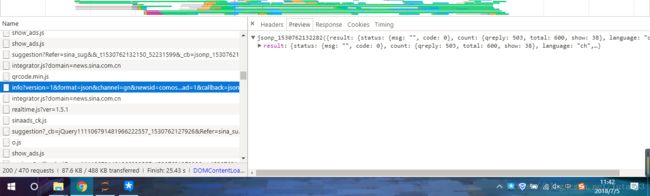
这是老师给出的爬取评论数的函数
import re
import requests
import json
commentURL='http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=comos-{}&group=undefined&\
compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3&t_size=3&h_size=3&thread=1'
def getCommentCounts(newsurl):
m = re.search('doc-i(.*).shtml',newsurl)
newsid = m.group(1)
comments = requests.get(commentURL.format(newsid))
jd = json.loads(comments.text)
return (jd['result']['count']['total'])由于新闻页面的评论的链接应该都比较相似,用于区分不同新闻的只是用到了newsid一项数据,因此可以先用{}代替,在批量抓取时用newsid替换即可。但是在实际使用时发现有的新闻评论抓取不成功,在用链接替换了newsid之后在地址栏打开会返回一个含有exception的错误数据,提示我们向新浪发送的这个请求出现异常,并没有找到这个新闻的评论,这是怎么回事呢?打开这条新闻,我发现他的评论的请求URL与其他的新闻在channel部分有些不同,大部分的都是gn,而少数则是sh,而我们没有考虑到这种情况,这样在遇到channel为sh的时候就无法抓取到评论,该如何解决呢?我最先想到是用Python的try except来处理没有找到页面的异常,但是可能由于异常是在服务器端的,服务器返回的信息只是告诉我地址有异常,而不是程序出现异常,并不能捕获到,因此我采用了一个比较低级但是很有效的方法:检测服务器返回的信息中是否含有exception字段,下面是考虑到这点后改进的函数,同时加入了处理超时异常的部分
import re
import requests
import json
commentURL1 = 'http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=gn&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3'
commentURL2 = 'http://comment5.news.sina.com.cn/page/info?version=1&format=json&channel=sh&newsid=comos-{}&group=undefined&compress=0&ie=utf-8&oe=utf-8&page=1&page_size=3'
def getCommentCount(newsurl): #得到某个新闻下面的评论数 #也有可能超时 也有可能是gn和sh
try:
m = re.search('doc-i(.*).shtml',newsurl)
newsid = m.group(1)
comments = requests.get(commentURL1.format(newsid),timeout=1)
jd = json.loads(comments.text)
flag = 'exception'
if (flag in comments.text):
comments = requests.get(commentURL2.format(newsid),timeout=1)
jd = json.loads(comments.text)
return jd['result']['count']['total']
else:
return jd['result']['count']['total']
except Exception as e:
return "timeoutflag"2.得到某个新闻的全部有效信息
我们想要得到的有标题、编辑、来源、时间、评论数、内容共六项信息,下面在网页中看看这些信息都被放在了什么地方
标题
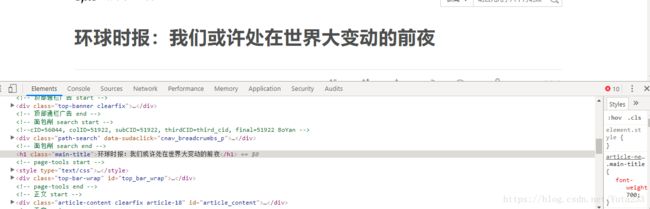
编辑
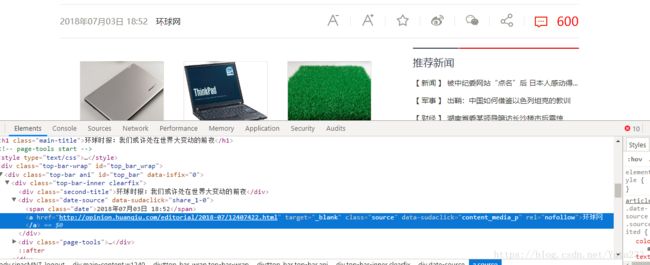
来源和时间
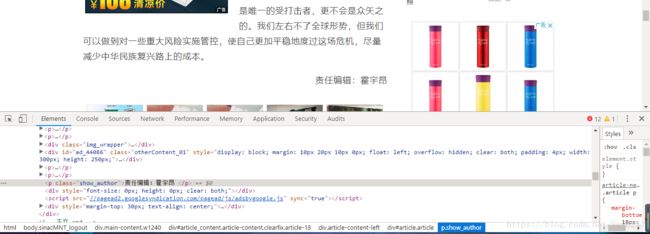
内容
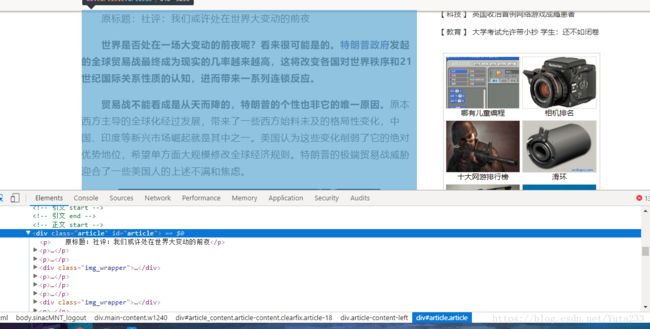
评论数我们使用getCommentCount方法获得
将这些获得信息的代码封装为函数(注意新闻页面部分元素名称做了修改)
import requests
from bs4 import BeautifulSoup
def getNewsDetail(newsurl):
result = {}
res = requests.get(newsurl) #bug
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
result['title'] = soup.select('.main-title')[0].text
result['newssource'] = soup.select('.date-source a')[0].text
result['time'] = soup.select('.date')[0].text
result['article'] = ' '.join([p.text.strip() for p in soup.select('#article p')[:-2]])
result['editor'] = soup.select('.show_author')[0].text.strip("责任编辑:")
result['comments'] = getCommentCounts(newsurl)
return result代码使用的时候,在采集新闻来源上出现和设计模块一时同样的问题:有些来源采集不到,对采集不到的新闻页面进行观察发现这些新闻的来源部分元素名称不太一样,因此在采集时需要做个判断,同时也加入了对采集的超时处理,下面是改进后的代码
from bs4 import BeautifulSoup
def getNewsDetail(newsurl): #得到某个新闻的全部信息
result = {}
try:
res = requests.get(newsurl,timeout=0.5)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
result['title'] = soup.select('.main-title')[0].text
if len(soup.select('.date-source a')):
result['newssource'] = soup.select('.date-source a')[0].text
else:
result['newssource'] = soup.select('.date-source .source')[0].text
result['time'] = soup.select('.date')[0].text
result['article'] = ' '.join([p.text.strip() for p in soup.select('#article p')[:-2]])
result['editor'] = soup.select('.show_author')[0].text.strip("责任编辑:")
result['comments'] = getCommentCount(newsurl)
return result
except Exception as e:
return result
3.得到某页全部新闻的信息
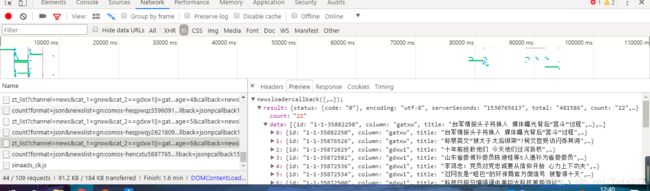
在点击下一页按钮的时候观察js请求,会发现新增了三个
![]()
其中一个就记录了该页的新闻的标题和链接,我们可以根据这个请求找到这一页所有新闻的链接,下面是实现这个功能的函数
def parseListLinks(url): #得到某页新闻的信息
newsdetails = []
res = requests.get(url)
jd = json.loads(res.text.lstrip(' newsloadercallback(').rstrip(');'))
for ent in jd['result']['data']:
newsdetails.append(getNewsDetail(ent['url']))
return newsdetails但是我们使用这个函数必须知道加载一页新闻的请求URL,打开这个请求的Headers,把他的URL复制下来

把page的赋值部分用{}代替,接下来我们使用这个函数对新浪新闻前三页的新闻信息进行爬取
4.调用函数进行新闻爬取
url = 'http://api.roll.news.sina.com.cn/zt_list?channel=news&cat_1=gnxw&\
cat_2==gdxw1||=gatxw||=zs-pl||=mtjj&level==1||=2&show_ext=1&show_all=1&show_num=22&\
tag=1&format=json&page={}'
news_total = []
for i in range(1,4):
newsurl = url.format(i)
newsary = parseListLinks(newsurl)
news_total.extend(newsary)显示爬到的信息
import pandas
df = pandas.DataFrame(news_total)
pandas.set_option('display.max_rows',None)
df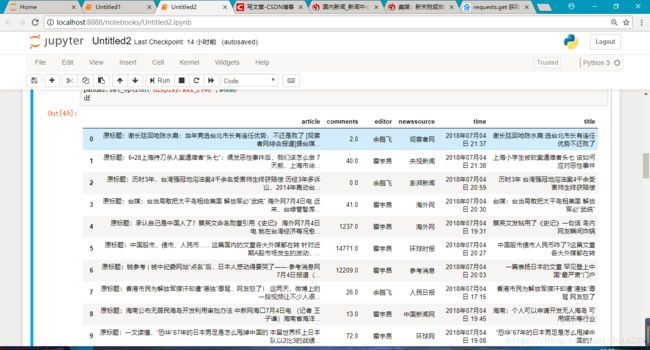
存入数据库,我的数据库选择的是mysql,没有用老师的sqlite
from sqlalchemy import create_engine
import pymysql
import pandas as pd
engine = create_engine("mysql+pymysql://root:wasd1234@localhost:3306/sina?charset=utf8")
df.to_sql(name = 'news',con = engine,if_exists = 'append',index = False,index_label = False)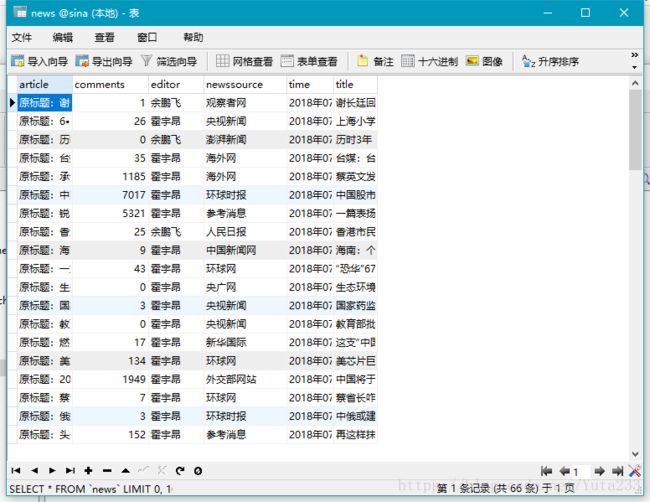
显示数据库信息
conn = pymysql.connect(host="localhost",user="root",passwd="wasd1234",db='sina',port = 3306,charset="utf8")
sql = "select * from news "
df = pd.read_sql(sql,conn)
pandas.set_option('display.max_rows',None)
df