MySQL | 数据库基础理论、六大设计范式详解
从本篇博文开始,会陆续介绍MySQL数据库的相关内容,分为以下几个部分:
- 数据库基础理论
- 基本CURD操作(常用SQL)
- 索引及其底层实现原理
- MySQL体系结构与存储引擎
- MySQL优化之SQL和索引的优化、应用优化、MySQL Server优化
- MySQL安全之SQL注入式错误
- 事务处理
- MySQL锁机制
- MySQL面试宝典
文章目录
- MySQL基础知识
- 关系型数据库与非关系型数据库
- 从技术层面了解MySQL
- 数据库的范式设计
- 基础概念:关键码、属性与函数依赖、多值依赖
- 第一范式(1NF):每一列保持原子特性
- 第二范式(2NF):属性完全依赖于主键
- 第三范式(3NF):属性不依赖于其它非主属性
- 巴德斯科范式(BCNF):每个表中只有一个候选键
- 第四范式(4NF):互相独立的非主属性无多值
- 第五范式(5NF):处理相互依赖的多值情况
MySQL基础知识
MySQL是一个开源的关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一。
数据库分为关系型数据库和非关系型数据库。
接下来我们介绍一下关系型数据库和非关系型数据库的概念。
关系型数据库与非关系型数据库
关系型数据库:指采用了关系模型来组织数据的数据库。
关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
关系模型中常用的概念:
- 关系:一张二维表,每个关系都具有一个关系名,也就是表名
- 元组:二维表中的一行,在数据库中被称为记录
- 属性:二维表中的一列,在数据库中被称为字段
- 域:属性的取值范围,也就是数据库中某一列的取值限制
- 关键字:一组可以唯一标识元组的属性,数据库中常称为主键,由一个或多个列组成
- 关系模式:指对关系的描述。其格式为:关系名(属性1,属性2, … … ,属性N),在数据库中成为表结构
关系型数据库的优点:
- 容易理解:二维表结构是非常贴近逻辑世界的一个概念,关系模型相对网状、层次等其他模型来说更容易理解
- 使用方便:通用的SQL语言使得操作关系型数据库非常方便
- 易于维护:丰富的完整性(实体完整性、参照完整性和用户自定义完整性)大大减低了数据冗余和数据不一致的概率
数据库事务必须具备ACID特性,ACID分别是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性
当今十大主流的关系型数据库有
Oracle,Microsoft SQL Server,MySQL,PostgreSQL,DB2,Microsoft Access, SQLite,Teradata,MariaDB(MySQL的一个分支),SAP。
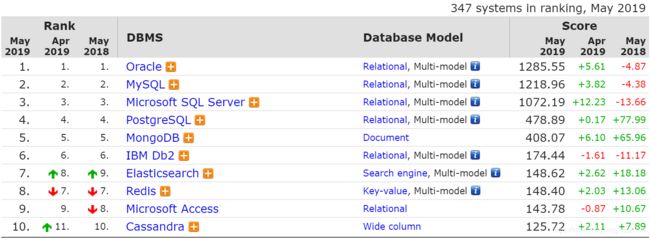
下表是2019年5月的数据库排名:
非关系型数据库我们不做详细介绍,只给出基本概念:
非关系型数据库,又被称为NoSQL(Not Only SQL ),意为不仅仅是SQL,指非关系型的,分布式的,且一般不保证遵循ACID原则的数据存储系统。
非关系型数据库以键值对
关系型与非关系型数据库的比较
- 成本:Nosql数据库简单易部署,基本都是开源软件,不需要像使用Oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
- 查询速度:Nosql数据库将数据存储于缓存之中,而且不需要经过SQL层的解析,关系型数据库将数据存储在硬盘中,自然查询速度远不及Nosql数据库。
- 存储数据的格式:Nosql的存储格式是
- 扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。Nosql基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
- 持久存储:Nosql不使用于持久存储,海量数据的持久存储还是需要关系型数据库。
- 数据一致性:非关系型数据库一般强调的是数据最终一致性,不像关系型数据库一样强调数据的强一致性,从非关系型数据库中读到的有可能还是处于一个中间态的数据,Nosql不提供对事务的处理。
从技术层面了解MySQL
MySQL在整个网络环境中使用客户端/服务器(Client/Server)架构运行。换言之,其核心程序扮演着服务器角色,而各个客户端程序连接到服务器并提出请求。
MySQL的安装涉及以下主要组件: MySQL Server、Client程序和MySQL非客户端工具。
MySQL Server或者说mysqld,实际上是一个数据库服务器程序。它管理着对磁盘数据库和内存的访问。MySQL Server进行多线程操作,它支持多个客户端连接的同时访问。为了更好地管理数据库内容,MySQL Server的特色架构模型支持多种存储引擎以处理不同类型的表(例如,它同时支持事务和非事务表)。
Client客户端程序被用于和Server进行通信以修改服务器端Server管理的数据库信息。
MySQL server进行交互所使用各种不同通信协议:
- TCP/IP协议
- Unix Socket
- 共享内存
- NT管道
总结:
- MySQL设计成C/S客户端服务器模型,应用作为MySQL Client向MySQL Server发送请求,获取响应,因此MySQL非常适用于集群环境,方便做主从复制,读写分离操作。
- 为了提高效率,MySQL Client和MySQL Server如果处在不同主机上,是通过Socket进行网络通信的;如果它们在同一台机器上,那么Client和Server之间是通过共享内存进行通信的,效率比Socket通信更高。
- MySQL的服务器模块采用的是I/O复用+可伸缩的线程池,是实现网络高并发服务器的经典模型。
数据库的范式设计
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴德斯科范式(BCNF)、第四范式(4NF)和第五范式(5NF)。
满足最低要求的范式是第一范式。在第一范式的基础上进一步满足更多要求的称为第二范式,其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
设计关系型数据库时,遵从不同的规范要求,设计出合理的关系型数据库。这些规范被称作范式。越高的范式数据库的冗余度就越低。
范式设计的优点:
- 减少数据冗余
- 消除异常(插入异常,更新异常,删除异常)
- 让数据组织的更加和谐
数据库范式绝对不是越高越好,范式越高,意味着表越多,多表联合查询的机率就越大,SQL的效率就变低。
在创建一个数据库的过程中,范化是将其转化为一些表的过程,这种方法可以使从数据库得到的结果更加明确。这样可能使数据库产生重复数据,从而导致创建多余的表。
泛化是在识别数据库中的一个数据元素、关系以及定义所需的表和各表中的项目这些初始工作之后的一个细化的过程。
基础概念:关键码、属性与函数依赖、多值依赖
关键码与属性
- 候选码和主码:表中可以唯一确定一个元组的某个属性(或者属性组)叫候选码,我们从许多个候选码中挑一个就叫主码。
- 全码:如果一个码包含了所有的属性,这个码就是全码。
- 主属性:一个属性只要在任何一个候选码中出现过,这个属性就是主属性。
- 非主属性:与上面相反,没有在任何候选码中出现过,这个属性就是非主属性。
- 外码:一个属性(或属性组),它不是码,但是它别的表的码,它就是外码。
函数依赖
设R(U)是一个属性集U上的一个关系模式,X和Y是U的子集。若对于R(U)的任意两个可能的具体关系r1、r2,若r1[x] == r2[x]则r1[y] == r2[y],或者若r1[x] != r2[x]则r1[y] != r2[y],称X决定Y,或者Y函数依赖于X,记作X→Y。就像函数一样,给一个确定的输入(属性集X),有一个确定的输出(属性集Y)。
抽象的“关系模式”和具体存在的“关系”,下文统称“关系”。
如果X→Y,但Y为X的子集, 则称X→Y是平凡函数依赖。
如:关系R(Sno, Cno),依赖关系(Sno, Cno)→Sno,(Sno, Cno)→Cno都是平凡函数依赖。
如果X→Y,但Y不为X的子集,则称X→Y是非平凡的函数依赖。
如:关系R(Sno, Cno, Grade),依赖关系(Sno, Cno)→Grade是非平凡函数依赖。
如果X→Y,存在X的真子集X1,使得X1→Y,则称Y部分依赖于X。也就是Y依赖于部分的X。
如:学生表(学号, 姓名, 性别, 班级, 年龄),(学号, 姓名)→性别,学号→性别,所以(学号, 姓名)→性别是部分函数依赖。
如果X→Y,但任何X的真子集X1都不存在X1→Y则称Y完全依赖于X。
如:成绩表(学号, 课程号, 成绩),(学号, 课程号)→成绩,学号!→成绩,课程号!→成绩,所以(学号, 课程号)→成绩是完全函数依赖。
如果X→Y,Y→Z,X⊄Y,Y!→X,(X∪Y)∩Z=∅,则称Z传递依赖于X。
如:关系S(学号, 系名, 系主任),学号→系名,系名→系主任,系名!→学号,所以学号→系主任为传递函数依赖。
完全依赖、部分依赖、传递依赖
部分函数依赖:设X,Y是关系R的两个属性集合,存在X→Y,若 X’ 是 X 的真子集,存在X’ → Y,则称Y部分函数依赖于X。
示例:学生基本信息表R中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)→(姓名),(学号)→(姓名),(身份证号)→(姓名)。所以姓名部分函数依赖于(学号,身份证号);完全函数依赖:设X,Y是关系R的两个属性集合,X’ 是 X 的真子集,存在 X → Y,但对每一个 X’ 都有 X’ !→ Y,则称Y完全函数依赖于X。
示例:学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)→(姓名),但是(学号)→(姓名)不成立,(班级)→(姓名)不成立,所以姓名完全函数依赖于(学号,班级);传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在 X →Y(Y !→X),Y→Z,则称Z传递函数依赖于X。
示例:在关系R(学号 ,宿舍, 用电量)中,(学号)→(宿舍),宿舍 != 学号,(宿舍)→( 用电量),所以符合传递函数的要求;
函数依赖与属性的关系
设R(U)是属性集U上的关系模式,X、Y是U的子集。
-
如果X和Y之间是一对一(1:1)关系,如学校和校长,则存在函数依赖X→Y和Y→X。
-
如果X和Y之间是一对多(1:n)关系,如年龄和姓名,则存在函数依赖Y→X。
-
如果X和Y之间是多对多(m:n)关系,如学生和课程,则X和Y之间不存在函数依赖。
多值依赖
多值依赖是属性之间的一对多关系,记为K→→A。
函数依赖事实上是单值依赖,所以不能表达属性值之间的一对多关系。(有人称函数依赖为多值依赖的特例)
平凡的多值依赖:全集U=K+A,一个K可以对应于多个A,即K→→A。此时整个表就是一组一对多关系。
非平凡的多值依赖:全集U=K+A+B,一个K可以对应于多个A,也可以对应于多个B,A与B互相独立,即K→→A,K→→B。整个表有多组一对多关系,且有:“一”部分是相同的属性集合,“多”部分是互相独立的属性集合。
第一范式(1NF):每一列保持原子特性
第一范式是指数据库表的每一列都是不可分割的原子数据项,不能是集合,数组,记录等非原子数据项。同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。第一范式的模式要求属性值不可再分裂成更小部分,即属性项不能是属性组合或是由一组属性构成。
简而言之,第一范式就是无重复的列,每一列保持原子特性。例如,下图由于住址列还可以再继续划分成为省、市、区等属性,因此下表设计不符合第一范式的要求:
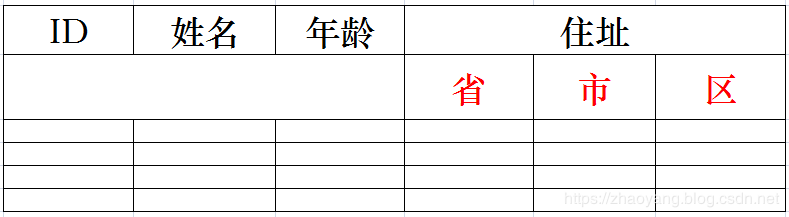
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
一般来说,第一范式是存在大量的数据冗余、插入异常、删除异常和更新异常的,因此我们有更高级别的第二范式。
第二范式(2NF):属性完全依赖于主键
第二范式建立在第一范式的基础上,即满足第二范式一定满足第一范式。
第二范式要求数据表每一个实例或者行必须被唯一标识。除满足第一范式外还有两个条件:
- 一是表必须有一个主键
- 二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。
每一行的数据只能与其中一列相关,即一行数据只做一件事。只要数据列中出现数据重复,就要把表拆分开来。
举例来说:当数据表中是联合主键,但是有的列只依赖联合主键中的一个或一部分属性组成的联合主键,此时需要拆表才能符合第二范式。
示例如下:

上表中 ( 学号,课程名称 ) 是联合主键,但是学分字段只和课程名称有关,和学号无关,相当于只依赖联合主键的其中一个字段,不符合第二范式。
会存在下述问题:
- 数据冗余,每条记录都含有相同信息
- 删除异常:删除所有学生成绩,就把课程信息全删除了;
- 插入异常:学生未选课,无法记录进数据库
- 更新异常:调整课程学分,所有行都调整
若要使其满足第二范式,那么我们应该将(课程名称,学分)两个字段单独划出一个课程信息表,将(学号, 课程名称, 成绩)划分为选课关系表。
修改为符合2NF的表如下:
学生:Student(学号, 姓名, 年龄)
课程:Course(课程名称, 学分)
选课关系:StudentCourse(学号, 课程名称, 成绩)
第三范式(3NF):属性不依赖于其它非主属性
若某一范式是第二范式,且每一个非主属性都不传递依赖于该范式的候选键,则称为第三范式。
即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
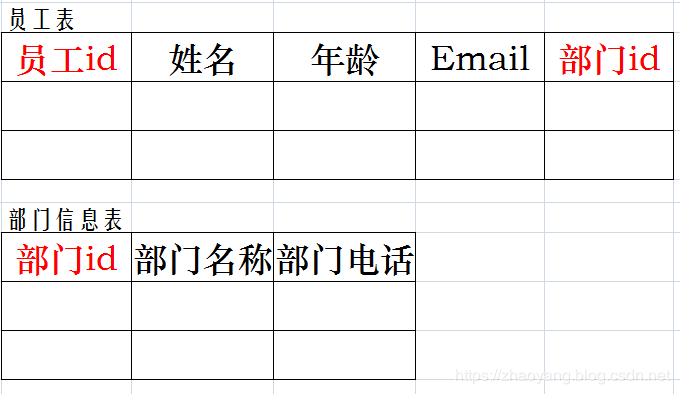
如下例:

上表中员工id能够唯一确定员工信息,但是部门名称、部门电话可由部门id唯一确定,则部门信息传递依赖于员工id,此时,该表不符合第三范式。
若要使上表满足第三范式,那么我们应该将(部门id,部门名称,部门电话)三个字段单独划出一个部门信息表,并在上表中把部门名称,部门电话删除即可。此时上表中部门id成为外键,因为在部门信息表中部门id为主键。
注意: 一般说来,数据库只需满足第三范式(3NF)就行了。
总结:
- 第一范式:列不能再分
- 第二范式:建立在第一范式基础上,消除部分依赖
- 第三范式:建立在第二范式基础上,消除传递依赖
巴德斯科范式(BCNF):每个表中只有一个候选键
BCNF是比第三范式更严格一个范式。它要求关系模型中所有的属性(包括主属性和非主属性)都不传递依赖于任何候选关键字。也就是说,当关系型表中功能上互相依赖的那些列的每一列都是一个候选关键字时候,该满足BCNF。
BCNF实际上是在第三范式的基础上,进一步消除了主属性的传递依赖。
BC范式是在第三范式的基础上的一种特殊情况,即 每个表中只有一个候选键(在一个数据库中每行的值都不相同,则可称为候选键),在上面第三范式的员工表中,可以看出,每一个员工的Email都是唯一的,那么此表中存在多个候选键(员工id、Email),即存在(员工id)→(Email),(Email)→(员工id),即存在关键字段决定关键字段的情况,所以其不符合BCNF范式。对其进行BC范式化如下:
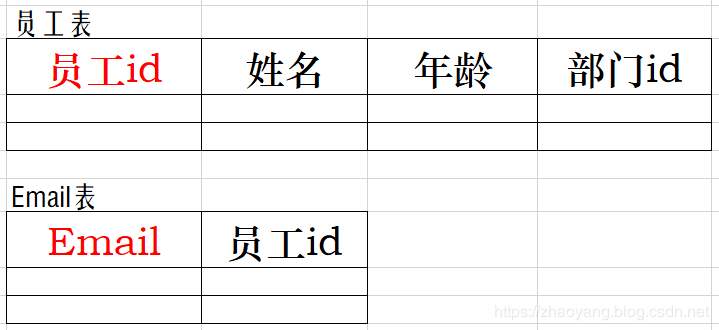
下面是一个BCNF范式的详细举例:
有这样一个配件管理表WPE(WNO,PNO,ENO,QNT),其中WNO表示仓库号,PNO表示配件号,ENO表示职工号,QNT表示数量。
有以下约束要求:
(1)一个仓库有多名职工;
(2)一个职工仅在一个仓库工作;
(3)每个仓库里一种型号的配件由专人负责,但一个人可以管理几种配件;
(4)同一种型号的配件可以分放在几个仓库中。
分析表中的函数依赖关系,可以得到:
- ENO->WNO
- (WNO,PNO) → QNT
- (WNO,PNO) → ENO
- (ENO,PNO) → QNT
可以看到,候选键有:(ENO,PNO)、(WNO,PNO)。所以,ENO、PNO、WNO均为主属性,QNT为非主属性。显然,非主属性是直接依赖于候选键的。所以此表满足第三范式。
而我们观察一下主属性:(WNO,PNO) → ENO,ENO->WNO。显然WNO对于候选键 (WNO,PNO) 存在传递依赖,所以不符合BCNF。
解决这个问题的办法是分拆为两个表:
- 管理表EP(ENO,PNO,QNT)
- 工作表EW(ENO,WNO)
但这样做会导致函数依赖(WNO,PNO) → ENO丢失。
第四范式(4NF):互相独立的非主属性无多值
第四范式需要满足以下要求:
- 必须满足第三范式
- 表中不能包含一个实体的两个或多个互相独立的多值因子
显然,第四范式也是一个比第三范式严格的范式。
第四范式的意思是:当一个表中的非主属性互相独立时(3NF),这些非主属性不应该有多值。若有多值就违反了第四范式。定义比较抽象,可以参照下面的例子理解。
有这样一个用户联系方式表TELEPHONE(CUSTOMERID,PHONE,CELL)。
CUSTOMERID为用户ID,PHONE为用户的固定电话,CELL为用户的移动电话。
本来,这是一个非常简单的第三范式表。主键为CUSTOMERID,不存在传递依赖。
但在某些情况下,这样的表还是不合理的。比如说,用户有两个固定电话,两个移动电话。这时,表的具体表示如下:

由于PHONE和mobilePhone是互相独立的,而有些用户又有两个和多个值。这时此表就违反第四范式。
在这种情况下,此表的设计就会带来很多维护上的麻烦。例如,如果用户放弃第一行的固定电话和第二行的移动电话,那么这两行会合并吗?
解决问题的方法为设计新表NEW_PHONE(CUSTOMERID,NUMBER,TYPE),TYPE表示NUMBER的类型,如TYPE=1时,NUMBER表示固定电话,TYPE=2时,NUMBER表示移动电话,这样就可以对每个用户处理不同类型的多个电话号码,而不会违反第四范式。
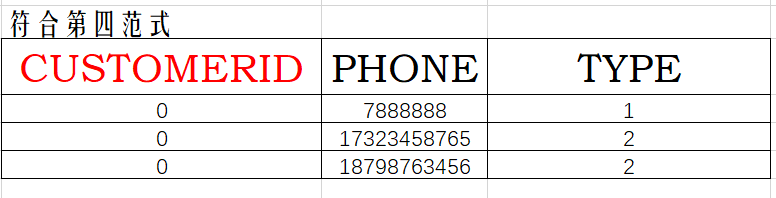
第四范式的应用范围比较小,因为只有在某些特殊情况下,要考虑将表规范到第四范式。所以在实际应用中,一般不要求表满足第四范式。
第五范式(5NF):处理相互依赖的多值情况
第五范式有以下要求:
- 必须满足第四范式
- 表必须可以分解为较小的表,除非那些表在逻辑上拥有与原始表相同的主键。
第五范式是在第四范式的基础上做的进一步规范化。消除连接依赖,并且必须保证数据完整性。
有些第四范式处理的是相互独立的多值情况,而第五范式则处理相互依赖的多值情况。
举例如下:
有一个销售信息表SALES(SALEPERSON,VENDOR,PRODUCT)。SALEPERSON代表销售人员,VENDOR代表供和商,PRODUCT则代表产品。
在某些情况下,这个表中会产生一些冗余。
可以将表分解为
- PERSON_VENDOR表(SALEPERSON,VENDOR)
- PERSON_PRODUCT表(SALEPERSON,PRODUCT)
- VENDOR_PRODICT表(VENDOR,PRODUCT)。
数据库应用的范式越高,表越多。表多会带来很多问题:
- 查询时需要连接多个表,增加了SQL查询的复杂度
- 查询时需要连接多个表,降低了数据库查询性能
因此,并不是应用的范式越高越好,要看实际情况而定。 第三范式已经很大程度上减少了数据冗余,并且基本预防了数据的插入异常,更新异常,和删除异常了。
知乎中个比较详细的帖子介绍1NF、2NF、3NF、BCNF范式:https://www.zhihu.com/question/24696366/answer/29189700