Python爬虫入门:爬取招聘网的招聘数据
Python爬虫入门:爬取招聘网的招聘数据
爬取智联招聘数据并分析
毕业将近,大部分学生面临找工作的压力,如何快速的找到自己心仪的岗位并且及时投递简历成为同学们关心的问题。本学期初学python,就想尝试着爬取招聘网站的招聘信息并进行分析。
本来只想爬取数据在控制台显示并分析的,但是数据是爬取下来了,我又觉得控制台太单调了,不喜欢在控制台输入输出,于是为爬虫写了一个很low的界面,写了界面之后发现要考虑的细节更多了,比如你不想让他随随便便就停止运行,出现异常,你想爬取多次而不是启动一次程序只能爬一次数据,这都是要考虑的问题。
在爬取智联招聘网之前我爬的是中华英才网,我在写好爬虫之后两天多的时间没管它,然后上课的时候我运行发现爬到的数据就很少了,之后还会莫名其妙的报错,我也懒得找原因了,就换个网站爬数据。还好之前界面已经写好,所以进度很快
源代码和图片文件:
链接:https://pan.baidu.com/s/1w3wdYRNynxo2mgQ9HXFPag
提取码:adpb
- 环境配置
- 爬取数据
- 搭建GUI界面
- 分析数据
环境配置
搭建环境
windows
python3.7
用到的库,包括python3.7内置库和pip工具安装的第三方库
python内置库:
urllib :主要用来将字典编码,拼接url
random :生成随机数
tkinter :绘制用户界面用到的库,也是程序中出现最多的库
webbrowser :用来打开系统默认浏览器,(很鸡肋的功能)
os :用来执行系统命令
datetime :用来获取系统的当前时间
threading :多线程的简单应用
time :延时用到 time.sleep()
winreg :用来操作注册表,获得应用程序的安装路径
第三方库:
requests :发送请求获取数据
lxml :python解析库,解析html,支持xpath解析方式
bs4 :解析和处理html、xml,
retrying :用@retry修饰函数,设定请求网页的最大次数
xlsxwriter :操作excel文件
mysql.connector :操作MySql数据库
PIL :图形库,cmd安装命令 pip3 install pillow
下面是对这些库的引用:
from urllib.parse import urlencode,urlparse #将字典编码,拼接url
import random
import tkinter #python自带GUI库
from tkinter import ttk
from tkinter.filedialog import askdirectory
import tkinter.messagebox #弹框
import webbrowser
import os
from datetime import*
import threading
import time
import winreg
#第三方库
import bs4
import requests
import lxml.html
from retrying import retry
import xlsxwriter
import mysql.connector
from PIL import Image,ImageTk
爬取数据
由于智联招聘网有反爬虫机制,职位信息不在网页源代码里面而是保存在json文件里,我们直接下载json,使用字典读取数据。
- 通过ajax接口,模拟ajax请求获取json数据
分析网页ajax接口:打开chrome开发者工具点击XHR过滤出ajax请求(如果没有数据按下F5刷新)

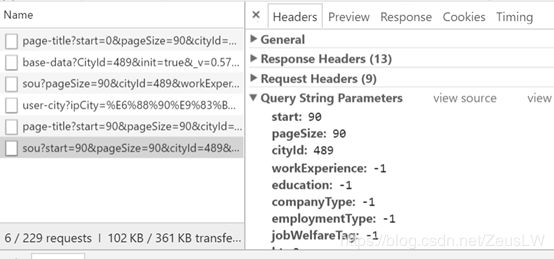
请求第一页和第二页,可以看到一页有长度为90,可以显示90个工作,start为页面显示的数据从第几条开始。
构造请求头:
headers={
"Host":"fe-api.zhaopin.com",
"Origin":"https://sou.zhaopin.com",
"Referer":"https://sou.zhaopin.com/?jl=489",
"User-Agent":"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.84 Safari/537.36"
}
构造地址请求网页并返回json数据:
#构造地址并返回json数据
def get_page(start, page,emptype="-1",):
city=region.get() if region.get()!="" else "489"
experience="-1" if exp.get()=="" or exp.get() not in list(expDict.keys()) else expDict[exp.get()]
education="-1" if edu.get()=="" or edu.get() not in list(eduDict.keys()) else eduDict[edu.get()]
comp= "-1" if company.get() not in list(companyDict.keys()) or company.get()=="" else companyDict[company.get()]
keywords = post.get() if company.get() in list(companyDict.keys()) or company.get()=="" else company.get()
if keywords=="":
keywords="-1"
params = {
"start":str(start),
"pageSize":"90",
"cityId":city,
"workExperience":experience,
"education":education,
"companyType":comp,
"employmentType":emptype,
"jobWelfareTag":"-1",
"kw":keywords,
"kt":"3",
"lastUrlQuery":{"p":str(page),"pageSize":"90","jl":city,"kw":keywords,"kt":"3"}
}
if salary.get() != "不限":
params["salary"] = salaryDict[salary.get()]
url = "https://fe-api.zhaopin.com/c/i/sou?"+urlencode(params)
result_json=download_retry(url)
return result_json
请求网页并返回json数据
lastPagejob=""
lastPagecompany=""
@retry(stop_max_attempt_number=4) #设定最大的尝试次数,可尝试下载4次
def download_retry(url):
global lastPagejob
global lastPagecompany
try:
response = requests.get(url,headers=headers,timeout=40)
print(response.status_code)
response.raise_for_status()
response.encoding = "utf-8"
js=response.json()
if js.get("data")==None:
return None
jb = js.get("data").get("results")[0].get("jobName")
co = js.get("data").get("results")[0].get("company").get("name")
if lastPagejob==jb and lastPagecompany==co:
return None
else:
lastPagejob=jb
lastPagecompany=co
return js # 转化为json数据
except:
return None
其中@retry(stop_max_attempt_number=4) 修饰download_retry()函数设置最大尝试请求网页的次数,我发现智联招聘我没有办法获取最总页数(可能是我没找对方法),而且在达到一定的页数之后即使你再增加页数,获得的网页内容都是一样的。为了避免请求重复的数据,我检验每一页第一个工作,公司是否是一样的,可能会有点影响效率,但我没有其他方法。
分析获得的网页内容并返回一个迭代器
def get_content(json):
global getingjob
global totalSalary
if json is not None:
result_items = json.get("data").get("results")
for item in result_items:
getingjob +=1
showJobNum.set("已获取 {} 个职位,为你展示热门职位".format(getingjob))
job_title = item.get("jobName").replace('\"',"")
#print(job_title)
job_city = item.get("city").get("display")
if '-' in job_city:
job_city=job_city.split('-')[0]
job_salary = item.get("salary")
aver_salary=0
if '-' in job_salary:
jobList=job_salary.replace("K","").split("-")
totalSalary+=eval(jobList[0])+eval(jobList[1])
aver_salary=(eval(jobList[0])+eval(jobList[1]))/2*1000
job_edu = item.get("eduLevel").get("name")
job_exp = item['workingExp']['name']
job_type = item['jobType']['display']
job_emlp = item['emplType']
job_fare = item['welfare']
if job_fare=="[]":
job_fare="无"
job_createDate=item["createDate"]
job_updateDate=item['updateDate']
job_endDate=item['endDate']
job_company = item.get("company").get("name")
job_url = item.get("positionURL")
job_company_url=item['company']['url']
yield{
"number":"{:0>5}".format(getingjob),
"job_title": job_title,
"job_city": job_city,
"job_salary": job_salary,
"aver_salary":str(aver_salary),
"job_edu": job_edu,
"job_company": job_company,
"job_exp":job_exp,
"job_type":job_type,
"job_emlp":job_emlp,
"job_fare":job_fare,
"job_createDate":job_createDate,
"job_updateDate":job_updateDate,
"job_endDate":job_endDate,
"job_url": job_url,
"job_company_url":job_company_url,
} #返回一个迭代器
这个函数主要分析获得的json数据并返回一个迭代器
yield: yield是一个迭代生成器
启动爬取网页的整个过程的函数main():
#启动爬取数据过程的主函数
dbName="智联招聘" #数据库名
tableName="" #表名,根据搜索条件来命名
averSalary=0 #平均工资
lslistbox=[] #界面列表框要显示的值
def main():
global getingjob
global lastPagejob,lastPagecompany
global totalSalary,averSalary
global tableName,dbName
totalSalary=0
flag = True
getingjob = 0 #总职位数重置为0
lslistbox.clear() #将上一次的列表框显示的值清空
showlistbox=0
listbox.delete(0,'end') #清空列表框
showJobNum.set("已获取 0 个职位") #更新实时显示爬取工作数的标签
#格式化字符串函数
def getFormat(str, length=60): #得到字符串宽度
w = get_total_width(str)
return str.ljust(length - w)
#建立数据库连接并建表
mydb = mysql.connector.connect(host="localhost", user="root", passwd="") #建立连接
mycursor = mydb.cursor()
mycursor.execute("create database if not exists {}".format(dbName)) # 创建数据库
tableName = post.get() + '_' + region.get() + '_' + salary.get().replace('-', '_') + '_' + \
edu.get().replace('/','_') + "_" + exp.get().replace('-', "_") #表名
mycursor.execute("use " + "{}".format(dbName)) #进入到数据库
mycursor.execute("drop table if exists {}".format(tableName))
sql_createTable="create table {}(序号 varchar(10),职位 varchar(60),薪资 varchar(30), " \
"平均月薪 varchar(20),城市 varchar(30),学历 varchar(30),经验 varchar(30)," \
"公司 varchar(60), 职位类型 varchar(30), 职位亮点 varchar(100), " \
"更新时间 varchar(30), 结束时间 varchar(30)," \
"职位url varchar(200),公司url varchar(200)" \
") charset utf8".format(tableName)
mycursor.execute(sql_createTable)#创建表
for i in range(1,200):#由于无法获取到总页数,设置最大页数200
result = get_page(start=i*90, page=i-1)
if result is None: #
break
for content in get_content(result): #对返回的迭代遍历
#写入到数据库
inssql = """insert into {}(序号,职位,薪资,平均月薪,城市,学历,经验,公司,职位类型,职位亮点,更新时间,结束时间,职位url,公司url) values("{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}","{}")""".format(
tableName,
content["number"],content["job_title"], content["job_salary"], content['aver_salary'],content["job_city"],
content["job_edu"], content["job_exp"], content["job_company"],
content["job_type"],content["job_fare"],content["job_updateDate"],
content["job_endDate"],content["job_url"],content["job_company_url"])
#print(inssql)
try:
mycursor.execute(inssql)
except:
print(inssql)
continue
#写入到列表框
if showlistbox <300:
listbox.insert('end', "{:0>3}".format(content['number'])+"、"+
getFormat(content['job_title'])+" "
+getFormat(content["job_city"],20)
+getFormat(content['job_salary'],18)
+getFormat(content['job_edu'],15)
+getFormat(content["job_exp"],15)
+getFormat(content['job_company']))
showlistbox+=1
lslistbox.append(content)
def msgwin(): #弹出窗口提示爬取数据完成并使窗口变淡消失
win = tkinter.Toplevel(root)
win.geometry('200x100')
win.resizable(0, 0)
win.attributes("-toolwindow", 1)
tkinter.Label(win, text="爬取数据完成").place(x=20, y=20)
time.sleep(1)
for i in range(100):
time.sleep(0.02)
win.attributes("-alpha", 1 - i * 0.01)
win.destroy()
msgth = threading.Thread(target=msgwin)
msgth.setDaemon(True)
msgth.start()
lastPagejob=""
lastPagecompany=""
mydb.commit() #
mydb.close() #关闭数据库连接
averSalary=totalSalary/getingjob/2*1000
print(lslistbox)
print("平均工资为{}".format(averSalary))
main()函数开头要重置一些全局变量,将总工作数重设为0,清空列表框等,使得程序能够正常运行。我觉得最有意思的是函数里面还能定义函数,这是我偶然间发现的,后来上网证实,python函数里面能还能定义函数。用了一个for循环对返回的迭代遍历,将数据写入数据库,表名根据搜索条件命名。将前三百个热门职位显示在界面的列表框里,
当for循环结束,爬取数据结束,用子线程,弹出一个窗口提示爬取数据结束。python中,简单的用format打印出来的字符串排列效果差强人意,显得很乱,原因是各种字符实际显示的宽度都不一样,如果要显示特定的长度,有一个方法是计算出字符串所占宽度,用总长度减去字符串宽度再用空格去填充,以下是我借鉴的网上的计算字符串显示宽度的代码,能勉强对齐。
widths = [
(126, 1), (159, 0), (687, 1), (710, 0), (711, 1),
(727, 0), (733, 1), (879, 0), (1154, 1), (1161, 0),
(4347, 1), (4447, 2), (7467, 1), (7521, 0), (8369, 1),
(8426, 0), (9000, 1), (9002, 2), (11021, 1), (12350, 2),
(12351, 1), (12438, 2), (12442, 0), (19893, 2), (19967, 1),
(55203, 2), (63743, 1), (64106, 2), (65039, 1), (65059, 0),
(65131, 2), (65279, 1), (65376, 2), (65500, 1), (65510, 2),
(120831, 1), (262141, 2), (1114109, 1),
]
def get_width( o ):
global widths
if o == 0xe or o == 0xf:
return 0
for num, wid in widths:
if o <= num:
return wid
return 1
def get_total_width(str):
width = 0
for c in str:
width+=get_width(ord(c))
return width
GUI布局
PythonGUI库有Tkinter、wxPython、PyQt等,我使用tkinter编写界面,编写简单的界面不需要太复杂的用法,tkinter简单易学,我学习tkinter花了半天。tkinter功能并不强大。这里附上视频教程和PDF教程 :链接:https://pan.baidu.com/s/1-DLw_DRrialEMZjb3c2LwQ 提取码:0hig
主要用到了以下的一些控件,用绝对定位布局
#主窗口
root = tkinter.Tk()
root.title("智联招聘") #标题
root.geometry("800x550") #设置大小
root.resizable(0, 0) # 阻止Python GUI的大小调整
给主窗口设置背景图片:tkinter不能直接设置背景图片需要用画布 Canvas 的方式加载背景图片。
# 画布
canvas = tkinter.Canvas(root,width=900,height=600,bg='#CDC9A5')#画布颜色
image=Image.open("bg4.png")#加载图片
im=ImageTk.PhotoImage(image)
canvas.create_image(450,300,image=im)
canvas.create_text(75,23,font=('Arial', 11),text="按条件爬取工作:")
canvas.create_text(27,53,font=('Arial', 11),text="城市")
canvas.create_text(27,93,font=('Arial', 11),text="职业")
canvas.create_text(240,53,font=('Arial', 11),text="薪资")
canvas.create_text(240,93,font=('Arial', 11),text="经验")
canvas.create_text(430,53,font=('Arial', 11),text="企业")
canvas.create_text(430,93,font=('Arial', 11),text="学历")
canvas.place(x=-2,y=-2)
设置一个输入框:
# 城市
region = tkinter.StringVar() #tkinter中的类型
region.set("成都") #设置初值
entryRegion = tkinter.Entry(root,textvariable=region).place(x=50, y=40)
StringVar是tkinter里面的类型,Entry是一个输入框控件,将region与Entry关联可以改变输入框中显示的值,也可以通过region.get()获取输入的值。
设置一个下拉框:
salary = tkinter.StringVar()
salaryCombobox = ttk.Combobox(root, width=14,textvariable=salary,state='readonly')
salaryCombobox['values'] = ("不限","1K以下" , "2K-4K", "4K-6K", "6K-8K","8K-10K","10K-15K",
"15K-25K","25K-35K","35K-50K","50K-70K","70K-100K","100K以上") # 设置下拉列表的值
salaryCombobox.place(x=265, y=40)
salaryCombobox.current(0)# 设置下拉列表默认显示的值,0为 numberChosen['values'] 的下标值
ttk.Combobox是下拉框控件,current(0)设置默认显示的值,
state=‘readonly’设置不可编辑状态
设置一个标签:
showJobNum = tkinter.StringVar()
showJobNum.set("点击开始爬取")
label = tkinter.Label(root,textvariable=showJobNum,bg = "white",font=('Arial', 11), height=1)
label.place(x=130,y=160)
tkinter.Label()是标签控件,textvariable参数将StringVar类型与标签关联,可以修改标签显示的值。
设置一个button按钮:
# 点击开始爬取
queryButton = tkinter.Button(root, width=110, text="开始爬取",bg = "white", command=query)
queryButton.place(x=10, y=120)
按钮控件tkinter.Button(),command参数传递的是一个函数,表示当按钮按下时执行的函数。
添加一个列表框:
#列表框
frame = tkinter.Frame(root)
frame.place(x=10, y=195)
data = tkinter.StringVar()
y = tkinter.Scrollbar(frame) #垂直滚动条
y.pack(side='right', fill=tkinter.Y)
x = tkinter.Scrollbar(frame,orient="horizontal")#水平滚动条
x.pack(side='bottom',fill=tkinter.X)
listbox = tkinter.Listbox(frame, listvariable=data, width=108, height=17, yscrollcommand=y.set,xscrollcommand=x.set) #heigjt=18
listbox.pack(side='left')
x.config(command=listbox.xview)
y.config(command=listbox.yview)
tkinter.frame是tkinter中的容器,先为主窗口添加一个容器frame,然后将列表框放在容器里面,再为列表框添加垂直滚动条和水平滚动条。
listbox.bind("’’, com)
为列表框绑定点击事件,点击执行函数com()
分析数据
def openexcel():
path_=askdirectory() #打开文件夹选择对话框
global filedir
def createexcel(): #Python函数内部可以定义函数
global filedir
mydb = mysql.connector.connect(host="localhost",
user="root",passwd="",database="{}".format(dbName))
mycursor = mydb.cursor()
mycursor.execute("SELECT * FROM {}".format(tableName))
myresult = mycursor.fetchall() # fetchall() 获取所有记录
fileName="智联招聘.xlsx"
filedir=path_+'/'+filename #拼接绝对地址
workbook = xlsxwriter.Workbook(filedir) # 写入excel,命名
worksheet = workbook.add_worksheet() # 创建表单worksheet
imgws=workbook.add_worksheet()
worksheet.set_column("A:A", 8) #调整excel格式
worksheet.set_column("B:B", 26)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("H:H", 30)
worksheet.set_column("I:I", 30)
title = ["序号", "职位", "薪资", "平均月薪", "城市",
"学历", "经验", "企业", "工作类型", "福利", "更新时间",
"结束时间", "工作url", "城市url"] # excel文件标题
row, col = 0, 0
for t in title:
worksheet.write(row, col, t)
col += 1
row +=1
col=0
#计算学历和经验对应平均工资的字典
edu_salary={}
edu_num={}
exp_salary={}
exp_num={}
for x in myresult:
edu_salary[x[5]]=edu_salary.get(x[5],0)+eval(x[3])
edu_num[x[5]]=edu_num.get(x[5],0)+1
exp_salary[x[6]]=exp_salary.get(x[6],0)+eval(x[3])
exp_num[x[6]] = exp_num.get(x[6], 0) + 1
for i in x:
worksheet.write(row, col, i)
col+=1
row+=1
col=0
# print(edu_salary)
# print(edu_num)
totalrow=row
keys=list(edu_salary.keys())
for k in keys:
edu_salary[k]=edu_salary[k]/edu_num[k]
avSalary=list(edu_salary.values()) #计算
keys1 = list(exp_salary.keys())
for k in keys1:
exp_salary[k] = exp_salary[k] / exp_num[k]
avSalary1 = list(exp_salary.values())
worksheet.write(row, 0, "学历-平均月薪分布")
worksheet.write(row, 2, "经验-平均月薪分布")
row+=1
for i in range(len(keys)):
worksheet.write(row+i, 0, keys[i])
worksheet.write(row+i, 1, round(avSalary[i]))
for i in range(len(keys1)):
worksheet.write(row + i, 2, keys1[i])
worksheet.write(row + i, 3, round(avSalary1[i]))
#分析数据
chart1 = workbook.add_chart({'type': 'column'})
chart1.add_series({
'name': ['Sheet1',totalrow,0],
'categories': ['Sheet1',row,0,row+len(keys),0],
'values': ['Sheet1',row,1,row+len(keys),1],
})
chart1.set_title({'name': '学历-平均月薪分布'})
chart1.set_x_axis({'name': '学历'})
chart1.set_y_axis({'name': '平均月薪'})
chart1.set_style(11)
# 在D2单元格插入图表(带偏移)
worksheet.insert_chart('D5', chart1, {'x_offset': 25, 'y_offset': 10})
#经验平均月薪分布
chart2 = workbook.add_chart({'type': 'column'})
chart2.add_series({
'name': ['Sheet1', totalrow, 2],
'categories': ['Sheet1', row, 2, row + len(keys1), 2],
'values': ['Sheet1', row, 3, row + len(keys1), 3],
})
chart2.set_title({'name': '经验-平均月薪分布'})
chart2.set_x_axis({'name': '经验'})
chart2.set_y_axis({'name': '平均月薪'})
chart2.set_style(11)
# 在D2单元格插入图表(带偏移)
worksheet.insert_chart('D20', chart2, {'x_offset': 25, 'y_offset': 10})
workbook.close()
mydb.close()
os.startfile(filedir)
t = threading.Thread(target=createexcel)
t.setDaemon(True)
t.start() # 创建线程,启动线程
path_=askdirectory():
该行语句执行打开文件夹选择对话框选则文件夹并将路径返回。在函数内部定义函数createexcel(),用一个子线程执行从数据库读取数据写入excel文件并分析的过程。操作excel文件用第三方库xlsxwriter,xlsxwriter关于xlsxwriter的简单使用可以点击查看博客。
os.startfile(filedir):该语句用于打开指定路径上的文件,相当于鼠标双击。
点击退出,执行函数:
def qu():
global tableName,dbName
qui=tkinter.messagebox.askquestion(title="Thank you!",message="是否清空所有数据?")
if qui=="yes":
mydb = mysql.connector.connect(host="localhost", user="root", passwd="") # 建立连接
mycursor = mydb.cursor()
mycursor.execute("drop database if exists {}".format(dbName))
root.destroy()
else:
root.destroy()
点击退出,弹出窗口询问是否清除数据,之后通过root.destroy()销毁窗口,结束程序
点击列表框执行的函数:
def com(event):
global tableName,dbName
detail = tkinter.Toplevel(root) # 弹出窗口
detail.geometry('700x500')
detail.resizable(0, 0) # 阻止GUI的大小调整
canvas = tkinter.Canvas(detail, width=800, height=600, bg='#7CFC00')
canvas.place(x=-2,y=-2)
key = listbox.curselection()[0]
result = lslistbox[key]
jobsoup=getDetail(result['job_url']) #获取beautifulsoup对象
jobmsgs=download_detail(result['job_url'])
pay=result["job_fare"]
tkinter.Label(detail,bg='#7CFC00',text="招收人数: "+jobsoup.find("div",
{"class":"info-three l"}).find_all("span")[3].string).place(x=5,y=2)
tkinter.Label(detail,bg='#7CFC00', text="待遇: "+" ".join(pay)).place(x=5, y=20)
tkinter.Label(detail, bg='#7CFC00',text="上班地址: "+
jobsoup.find("p",{"class":"add-txt"}).text
).place(x=5, y=40)
tkinter.Label(detail, bg='#7CFC00',text="职位信息: ").place(x=5, y=60)
jobText = tkinter.Text(detail,bg='#7CFC00', width=98, height=13)
jobText.place(x=5, y=80)
for msg in jobmsgs:
jobText.insert('end', msg + "\n")
def applyjob():
webbrowser.open(result["job_url"])
tkinter.Button(detail,bg='#7CFC00',text="申请职位",command=applyjob).place(x=600,y=40)
tkinter.Label(detail,bg='#7CFC00', text="公司介绍:").place(x=5, y=260)
compText = tkinter.Text(detail, bg='#7CFC00',width=98, height=13)
compText.place(x=5, y=290)
companysoup=getDetail(result['job_company_url'])
companymsgs=jobsoup.find("div",{"class":"jjtxt"}).text
compText.insert('end',companymsgs)
tkinter.Button(detail,bg='#7CFC00', text="查看该公司所有招聘职位").place(x=300, y=257)
点击列表框中的数据,产生点击事件,执行函数。
弹出一个子窗口detail,显示与职位有关的信息,包括公司信息。key = listbox.curselection()[0]:该语句获得被点击的数据在列表框中的序号。
download_detail(result[‘job_url’]):
该函数发起请求获取与职位有关的的详细信息
def download_detail(url):
throttle.wait_url(url)#限速器,参照网上代码
response=requests.get(url,headers={"User-Agent":random.choice(User_Agent)},timeout=5)
html = lxml.html.fromstring(response.text)
detail = html.xpath('//div[@class="pos-ul"]/descendant::*//text()')
return detail
这里简单的用到了xpath的语法,//div[@class=“pos-ul”]/descendant://text(),它的含义就是选择div中class属性为post-ul的div的所有子标签的所有文本内容
最后是有关时间显示的代码:
def clock():
while True:
t = datetime.now()
dText = canvas.create_text(680, 93, font=('Arial', 11), text="{}".format(t.date()))
tText = canvas.create_text(760, 93, font=('Arial', 11), text="{:0>2}:{:0>2}:{:0>2}".format(t.hour,t.minute,t.second))
time.sleep(1)
canvas.delete(dText)
canvas.delete(tText) #刷新
thclock=threading.Thread(target=clock)
thclock.setDaemon(True)
thclock.start()# 创建线程,启动线程
为时间的显示开一个子线程,实现每隔一秒就刷新
最后:
在代码中变量的命名不是很规范,起不到见名知意的效果,附上完整源代码。代码中会用到一张图片,用于主窗口的背景。将它命名为bg4.png并放到与代码py文件同级目录下即可。
链接:https://pan.baidu.com/s/1w3wdYRNynxo2mgQ9HXFPag
提取码:adpb
复制这段内容后打开百度网盘手机App,操作更方便哦
学习了tkinter之后我,我就自己写了一个自动关机的小程序,让电脑自动关机,因为我自己经常开着电脑睡觉。当然自动关机也可以通过系统命令的方式实现。以下是源代码:将它打包成exe文件添加到任务计划当中去就可以了:
from datetime import *
import tkinter.messagebox
import time
import threading
import os
root = tkinter.Tk()
root.title('定时关机')
root.geometry('280x140') #
root.resizable(False, False)
var = tkinter.StringVar()
tkinter.Label(root, textvariable=var, font=('Arial', 12),
height=1).place(x=44, y=30)
def yes():
os.system('shutdown -s -f -t 1')
def no():
root.destroy()
tkinter.Button(root, text="立即关机", font=('Arial', 12),
command=yes).place(x=40, y=80)
tkinter.Button(root, text="取消关机", font=('Arial', 12),
command=no).place(x=150, y=80)
def autoClose():
for i in range(60, -1, -1):
var.set("还有{}关机,是否取消关机".format(i))
time.sleep(1)
os.system('shutdown -s -f -t 1')
t = threading.Thread(target=autoClose)
t.start()
root.mainloop()
第一次写博客哦