强化学习笔记1-Python/OpenAI/TensorFlow/ROS-基础知识
概念:
机器学习分支之一强化学习,学习通过与环境交互进行,是一种目标导向的方法。
不告知学习者应采用行为,但其行为对于奖励惩罚,从行为后果学习。
机器人避开障碍物案例:
靠近障碍物-10分,远离障碍物+10分。
智能体自己探索获取优良奖励的各自行为,包括如下步骤:
- 智能体执行行为与环境交互
- 行为执行后,智能体从一个状态转移至另一个状态
- 依据行为获得相应的奖励或惩罚
- 智能体理解正面和反面的行为效果
- 获取更多奖励,避免惩罚,调整策略进行试错学习。

需要对比,理解和掌握强化学习与其他机器学习的差异,在机器人中的应用前景。
强化学习元素:智能体,策略函数,值函数,模型等。
环境类型:确定,随机,完全可观测,部分可观测,离散,连续,情景序列,非情景序列,单智能体,多智能体。
强化学习平台:OpenAI Gym/Universe/DeepMind Lab/RL-Glue/Rroject Malmo/VizDoom等。
强化学习应用:教育!医疗!健康!制造业!管理!金融!细分行业:自然语言处理/计算机视觉等。
参考文献:
- https://www.cs.ubc.ca/~murphyk/Bayes/pomdp.html
- https://morvanzhou.github.io/
- https://github.com/sudharsan13296/Hands-On-Reinforcement-Learning-With-Python
配置:
安装配置Anaconda/Docker/OpenAI Gym/TensorFlow。
由于涉及系统环境,版本配置各不相同,自行查阅资料配置即可。
常用命令如下:
bash/conda create/source activate/apt install/docker/pip3 install gym/universe/等。
上述全部配置完成后,测试OpenAI Gym和OpenAI Universe。
*.ipynb文档查看:ipython notebook或jupyter notebook

Gym案例:
倒立摆案例:
示例代码
import gym
env = gym.make('CartPole-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())关于这个代码更多内容,参考链接:
- https://blog.csdn.net/ZhangRelay/article/details/89325679
查看gym全部支持的环境。
from gym import envs
print(envs.registry.all())赛车示例:
import gym
env = gym.make('CarRacing-v0')
env.reset()
for _ in range(1000):
env.render()
env.step(env.action_space.sample())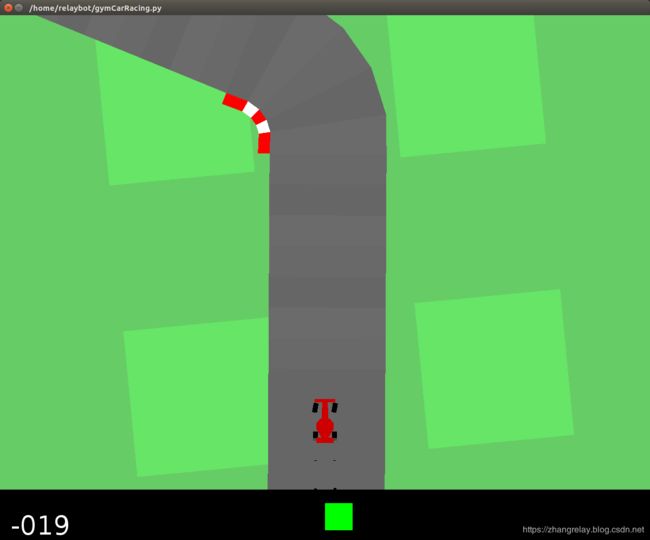
足式机器人:
import gym
env = gym.make('BipedalWalker-v2')
for episode in range(100):
observation = env.reset()
# Render the environment on each step
for i in range(10000):
env.render()
# we choose action by sampling random action from environment's action space. Every environment has
# some action space which contains the all possible valid actions and observations,
action = env.action_space.sample()
# Then for each step, we will record the observation, reward, done, info
observation, reward, done, info = env.step(action)
# When done is true, we print the time steps taken for the episode and break the current episode.
if done:
print("{} timesteps taken for the Episode".format(i+1))
break
flash游戏环境示例:
import gym
import universe
import random
env = gym.make('flashgames.NeonRace-v0')
env.configure(remotes=1)
observation_n = env.reset()
# Move left
left = [('KeyEvent', 'ArrowUp', True), ('KeyEvent', 'ArrowLeft', True),
('KeyEvent', 'ArrowRight', False)]
# Move right
right = [('KeyEvent', 'ArrowUp', True), ('KeyEvent', 'ArrowLeft', False),
('KeyEvent', 'ArrowRight', True)]
# Move forward
forward = [('KeyEvent', 'ArrowUp', True), ('KeyEvent', 'ArrowRight', False),
('KeyEvent', 'ArrowLeft', False), ('KeyEvent', 'n', True)]
# We use turn variable for deciding whether to turn or not
turn = 0
# We store all the rewards in rewards list
rewards = []
# we will use buffer as some kind of threshold
buffer_size = 100
# We set our initial action has forward i.e our car moves just forward without making any turns
action = forward
while True:
turn -= 1
# Let us say initially we take no turn and move forward.
# First, We will check the value of turn, if it is less than 0
# then there is no necessity for turning and we just move forward
if turn <= 0:
action = forward
turn = 0
action_n = [action for ob in observation_n]
# Then we use env.step() to perform an action (moving forward for now) one-time step
observation_n, reward_n, done_n, info = env.step(action_n)
# store the rewards in the rewards list
rewards += [reward_n[0]]
# We will generate some random number and if it is less than 0.5 then we will take right, else
# we will take left and we will store all the rewards obtained by performing each action and
# based on our rewards we will learn which direction is the best over several timesteps.
if len(rewards) >= buffer_size:
mean = sum(rewards)/len(rewards)
if mean == 0:
turn = 20
if random.random() < 0.5:
action = right
else:
action = left
rewards = []
env.render()
部分测试如下(多次测试):