深入浅出Python机器学习6——决策树与随机森林
| 决策树 |
- 决策树的基本原理
决策树是一种在分类与回归中都有非常广泛应用的算法,它的原理是通过对一系列问题进行 ifelse 的推导,最终实现决策。
- 决策树的构建
使用酒的数据集演示一下。

注意:此处为了方便演示,我们只取了数据集中样本的前两个特征。
实际中,问题的数量越多,就代表决策树的深度越深,此处我们用的最大深度为 1,所以 max_depth = 1。
进一步看看分类器的表现如何。

显然,最大深度为 1 时只分了两类,效果不是很好。接下来将最大深度设置为 3,并绘图。


此时,分类器能够进行3个分类的识别,而且大部分数据都进入了正确的分类。继续增加 max_depth 到 5。

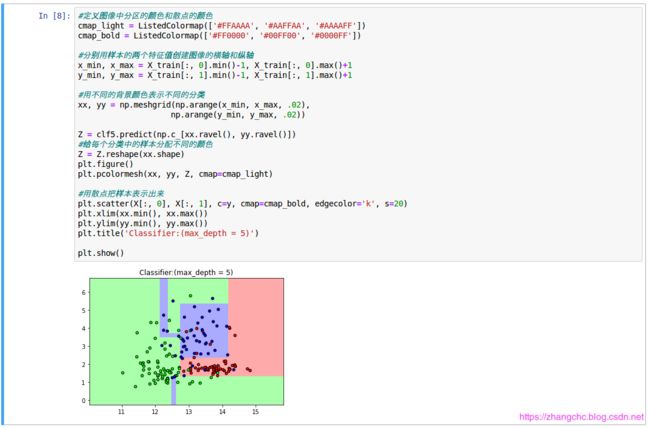
可以看出,分类器的表现进一步提升了。
补充:为了演示决策树在每一层的工作内容,可以用 graphviz 库来进行演示。
首先,我们得安装这个库
pip install graphviz

为了方便截图,所以设置 max_depth = 1 ,可以调整 max_depth 的大小来观看,效果会更好。
- 决策树的优势和不足
相比于其它算法,决策树有一个非常大的优势,就是可以很容易地将模型进行可视化。由于决策树算法对每个样本特征进行单独处理,因此并不需要对数据进行转换。
决策树也有不足之处,即便我们在建模的时候可以使用类似 max_depth 或者 max_leaf_nodes 等参数来对决策树进行预剪枝处理,但是它还是不可避免会出现过拟合的问题,也就让模型的泛化性能大打折扣了。
为了避免过拟合的问题,可以使用集合学习的方法,也就是接下来的随机森林。
| 随机森林 |
- 随机森林的概念
随机森林有的时候也被称为是随机决策森林,是一种集合学习方法,既可以用于分类,也可以用于回归。而所谓的集合学习算法,其实就是把多个机器学习算法综合在一起,制造出一个更加大模型的意思。
在机器学习领域,存在很多种集合算法,目前应用比较广泛的就包括随机森林(Random Forests)和梯度上升决策(Gradient Boosted Decision Trees, GBDT)。
由于随机森林是把不同的几棵决策树打包到一起,每棵树的参数都不相同,然后我们把每棵树预测的结果取平均值,这样既可以保留决策树的工作成效,又可以降低过拟合的风险。感兴趣的读者可以尝试着用数学方法推导。
- 决策森林的构建
继续用酒的数据集来构建。

随机森林向我们返回了包含其自身全部参数的信息。如bootstrap参数,代表的是bootstrap sample,就是是 ‘ 有放回抽样 ’ 的意思。
模型会基于新数据建立一颗决策树,在随机森林当中,算法不会让每棵决策树都生成最佳节点,而是会在每个节点上随机地选择一些样本特征,然后让其中之一有最好的拟合表现。如此例中,用max_features这个参数来控制所选择的特征数量最大值的,在不进行指定的情况下,随机森林默认自动选择最大特征数量。
关于max_features 参数的设置,还是有些讲究的。如果把max_features 设置为样本的全部的特征数 n_features 就意味着模型会在全部特征中进行筛选,这样在特征选职责这一步,就没有随机性可言了。如果把max_features 设置为 1,就意味着模型在数据特征上完全没有选择的余地,只能去寻找这 1 个被随机选出来的特征向量的阈值了。所以说 max_features 的取值越高,随机森林里的每一棵决策树就会长的越相似,他们因为有更多的不同特征可以选择,也就会更容易拟合数据;反之,如果 max_features 取值越低,就会迫使每棵树的样子更加不同,而且因为特征太少,决策树们不得不制造更多节点来拟合数据。
参数n_estimators是控制的随机森林中决策树的数量。在随机森林构建完成之后,每棵决策树都会单独进行预测。如果是用来进行回归分析的话,随机森林会把所有决策树预测的值取平均数;如果是用来进行分类的话,在森林内部会进行 “ 投票 ” 每棵决策树预测出数据类别的概率,比如其中一棵树判断这瓶酒80%属于class_1,另一棵树判断这瓶酒60%属于class_2,随机森林会把这些概率取平均值,然后把样本放入概率高的分类当中。
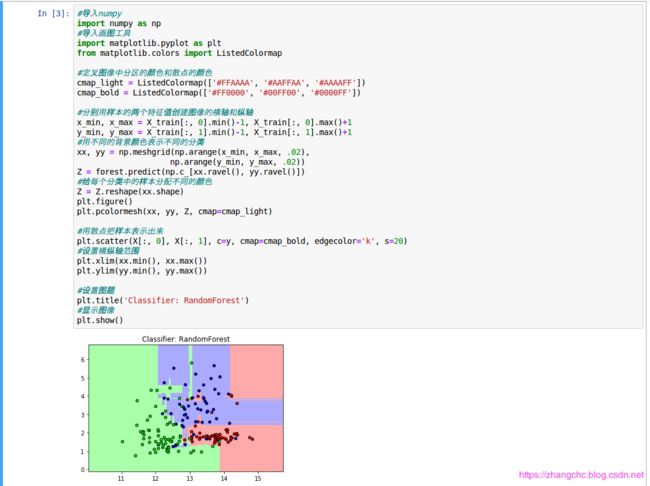
发现随机森林分类要比之前的更加细腻,对训练数据集的拟合更好。可以尝试着改变n_estimator和random——state参数,看看效果如何。
- 随机森林的优势和不足
优势上,随机森林继承了决策树的所有优点,而且可以弥补决策树的不足。但是也不是说决策树算法就被抛弃了。从便于展示决策过程的角度来说,决策树依旧表现强悍。尤其是随机森林中每棵树的层级要比单独的树更深,所以如果需要向非专业人士展示模型工作过程的话,还是需要用到决策树的。
此外,随机森林算法支持并行处理。对于超大规模数据集来说,随机森林会比较耗时(树多),不过我们可以用多进程并行处理方式来解决这个问题。实现方式是调节随机森林的 n_jobs 参数,记得把 n_jobs 参数设置为和CPU内核数一致,比如你的CPU内核数时 2,那么 n_jobs 设置成 3 或者更大就没什么意义。如果不清楚内核数有多少,可以设置 n_jobs = -1,这样随机森林会使用CPU的全部内核,速度就会得到提升。
需要注意的是,因为随机森林生成每棵树的方法是随机的,那么不同的 random_state 参数会导致模型完全不同,所以如果不希望建模的结果太过于不稳定,一定要固化 random_state 这个参数的数值。
不过,随机森林虽然有诸多优点,尤其是并行处理功能在处理超大数据集时能提供良好的性能表现。但它也有不足,例如,对于高维数据集、稀疏数据集等来说,随机森林有点捉襟见肘,在这种情况下,线性模型要比随机森林的表现更好一些。还有,随机森林相对更消耗内存,速度也比线性模型更慢,所以如果程序希望更节省内存和时间的话,建议还是选择线性模型。
| 随机森林实例 |
- 数据集的准备
先下载数据集
http://archive.ics.uci.edu/ml/machine-learning-databases/adult/
这个数据集中样本特征包括年龄、工作单位性质、统计权重、学历、受教育时长、婚姻状况、职业、家庭情况、种族、性别、资产所得、资产损失、每周工作时长、原籍、收入(大于 5 万或者小于等于 5 万)。查看数据集我们需要将 .data 格式文件转换为 .csv 格式。
为了方便演示,只选取了年龄、单位性质、学历、性别、周工作时长、职业和收入等特征

- 用get-dummies处理数据
首先我们需要用 pandas 中的 get_dummies 将字符特征改为整型特征,它可以在现有的数据集上添加虚拟变量,让数据集变成可以用的格式。

可以看出,get_dummies 把字符串类型的特征拆分开,把单位性质分为 “ 单位性质_ Feaeral-gov ” “ 单位性质_ Local-gov ” 等,如果样本人群的工作单位是联邦政府,那么 “ 单位性质_ Feaeral-gov ” 这个特征的值就是 1,而其他的工作单位性质特征值就会是 0,这样就把字符串巧妙的转换成了 0 和 1 这两个整型数值。可以看看前 5 行数据发生的变化:
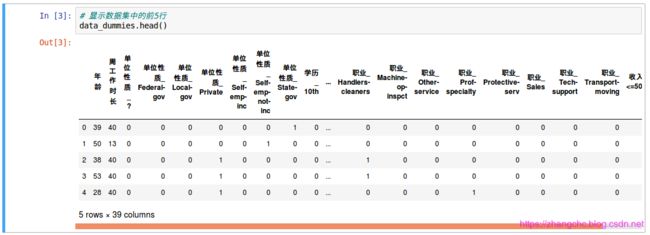
新的数据集已经扩充到了 39 列,原因就是 get_dummies 把原数据集的特征拆分成了很多列。现在我们把格列分配给特征向量 X 和分类标签 y,如下:

可以看到,让特征为“ 年龄 ” 这一列到 “ 职业_Transportation0-moving ” 这一列,而标签 y 为 “ 收入_>50K ”这一列,如果大于 50k,则 y=1,反之 y=0。
- 用决策树建模并做出预测
可以看到这里共有 100 个样本,每条数据有 39 个特征。将数据集拆分并训练:

结果表明,基于训练数据集训练的模型在测试集得到了 0.8 的评分,也就是说模型的准确率在 80%。
我们得知 Mr_Z 的年龄是 37 岁,在省机关工作,学历是硕士,性别男,每周工作 40 小时,职业是文员,将 Mr_Z 的数据输入测试:

结果显示,不满足要求。
上述用到的 adult 数据集是从美国1994年人口普查数据库抽取而来的,而且其中收入指的是年收入,并非月收入。我们只用这个数据集来演示决策树的用法,其结论对我们的真是生活场景的参考意义不大。
小编机器学习学的一般,只是日常做做比记加深一下印象,望读者不吝赐教,谢谢!