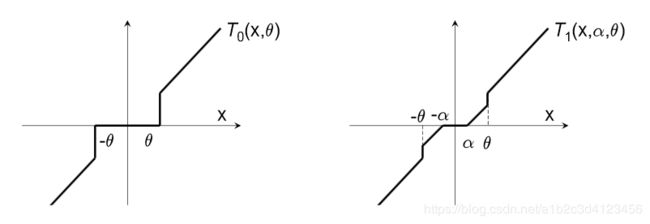Truncated Gradient --截断梯度
Truncated Gradient --截断梯度
- 简介
- 简单截断法
- L1正则化法
- 截断梯度法(Truncated Gradient)
简介
最近接触了大规模机器学习,在进行模型训练的时候采用的是广义线性模型,由于超高维度(十亿级别)导致训练的模型最后超级大,为了上线模型服务,最后的模型不能太大,需要进行模型的剪枝,于是就涉及到了梯度截断,用以减少模型的最终的权重的数量。同时梯度截断也可以减少不重要特征,凸显重要的特征在模型的影响,此外稀疏化的模型在参数更新过程中更具优势。
简单截断法
简单粗暴的方法,设置一个固定的阈值,当某个w小于阈值的时候,直接赋值为0。
这里有一个窗口的概念,参数k为窗口,表示采用截断的最小步长,也就是说截断不是每次都会触发。训练过程中每个batch用参数i表示,(每个可能包含多个样本,也可能包含一个,在线学习时候batchsize一般为1,但是受限于性能,实际应用中batchsize一般大于1)。
当i/k不是整数时候,不触发截断,梯度更新方式和如下:
W ( t + 1 ) = W ( t ) − η ( t ) G ( t ) W _ { ( t + 1 ) } = W _ { ( t ) } - \eta ^ { ( t ) } G ^ { ( t ) } W(t+1)=W(t)−η(t)G(t)
其中, G ( t ) G ^ { ( t ) } G(t)为第t次更新中损失函数的梯度, η ( t ) \eta ^ { ( t ) } η(t)为学习率。
当i/k为整数时候,梯度更新方式和如下:
W ( t + 1 ) = T 0 ( W ( t ) − η ( t ) G ( t ) , θ ) W ^ { ( t + 1 ) } = T _ { 0 } \left( W ^ { ( t ) } - \eta ^ { ( t ) } G ^ { ( t ) } , \theta \right) W(t+1)=T0(W(t)−η(t)G(t),θ)
其中, T 0 ( v i , θ ) T _ { 0 } \left( v _ { i } , \theta \right) T0(vi,θ)为分段函数,
T 0 ( v i , θ ) = 0 T _ { 0 } \left( v _ { i } , \theta \right) = 0 T0(vi,θ)=0 if ∣ v i ∣ ≤ θ \left| v _ { i } \right| \leq \theta ∣vi∣≤θ
T 0 ( v i , θ ) = v i T _ { 0 } \left( v _ { i } , \theta \right) = v _ { i } T0(vi,θ)=vi otherwise
一般情况下, θ ≥ 0 \theta \geq 0 θ≥0,是一个实数。
简单截断的主要缺点是对于值得选择是很难解决的问题,其次简单截断太暴力。
L1正则化法
由于L1正则在0处不可导,更新出过差中采用梯度计算L1正则的梯度,这样就避免了非凸优化的情况,梯度更新方式如下:
W ( t + 1 ) = W ( t ) − η ( t ) G ( t ) − η ( t ) λ sgn ( W t ) W _ { ( t + 1 ) } = W _ { ( t ) } - \eta ^ { ( t ) } G ^ { ( t ) } - \eta ^ { ( t ) } \lambda \operatorname { sgn } \left( W ^ { t } \right) W(t+1)=W(t)−η(t)G(t)−η(t)λsgn(Wt)
sgn为符号函数,
sgn ( x ) = 2 π ∫ 0 + ∞ sin x t t d t \operatorname { sgn } ( x ) = \frac { 2 } { \pi } \int _ { 0 } ^ { + \infty } \frac { \sin x t } { t } \mathrm { d } t sgn(x)=π2∫0+∞tsinxtdt
形状如下:

λ ∈ R \lambda \in \mathbb { R } λ∈R是一个标量,并且>=0。
L1正则化方法,主要缺点是产生稀疏解情况较少,因为前后两部分做加减法能够等于0的概率很小。
截断梯度法(Truncated Gradient)
截断梯度方法的更新方法比之前的稍微复杂一些,更新方式如下:
W ( t + 1 ) = T 1 ( W ( t ) − η ( t ) G ( t ) , η ( t ) λ ( t ) , θ ) W ^ { ( t + 1 ) } = T _ { 1 } \left( W ^ { ( t ) } - \eta ^ { ( t ) } G ^ { ( t ) } , \eta ^ { ( t ) } \lambda ^ { ( t ) } , \theta \right) W(t+1)=T1(W(t)−η(t)G(t),η(t)λ(t),θ)
其中的分段函数为:
T 1 ( v i , α , θ ) = { max ( 0 , v i − α ) if v i ∈ [ 0 , θ ] min ( 0 , v i + α ) else if v i ∈ [ − θ , 0 ) v i otherwise T _ { 1 } \left( v _ { i } , \alpha , \theta \right)= \begin{cases} \max \left( 0 , v _ { i } - \alpha \right) \text { if } v _ { i } \in [ 0 , \theta ]\\ \min \left( 0 , v _ { i } + \alpha \right) \text { else if } v _ { i } \in [ - \theta , 0 )\\ v _ { i } \text { otherwise } \end{cases} T1(vi,α,θ)=⎩⎪⎨⎪⎧max(0,vi−α) if vi∈[0,θ]min(0,vi+α) else if vi∈[−θ,0)vi otherwise
v i v _ { i } vi代表正常的梯度更新,根据该值与 α \alpha α的比较进行不同的取值。阶段梯度法仍然是有窗口k进行触发的, λ ( t ) = k λ \lambda ^ { ( t ) } = k \lambda λ(t)=kλ,该值和 θ \theta θ决定了稀疏度,这两个值都很大,模型就会很稀疏(这两个参数可以相等)。
简单截断法和梯度截断法的区别如下: