Hadoop高可用集群搭建——7台虚拟机
第一步:虚拟机安装
使用CentOS6.9,最小化安装,安装完成之后,克隆出另外6台虚拟机。克隆完成之后需要对网卡进行修改,步骤如下:
1. 修改hostname vi /etc/sysconfig/network
2. 修改网卡配置,把eth0的信息删掉,eth1的name改成eth0。vi /etc/udev/rules.d/70-persistent-net.rules
3. 修改eth0的配置信息,vi /etc/sysconfig/network-scripts/ifcfg-eth0 将其uuid删除,更改MAC地址为rules中的原有的eth1的MAC信息,增加GATEWAY(网关),NETMASK(子网掩码),IPADDR(IP)
4.配置完成后,reboot即可。重启后,ping baidu.com 无问题,说明成功。

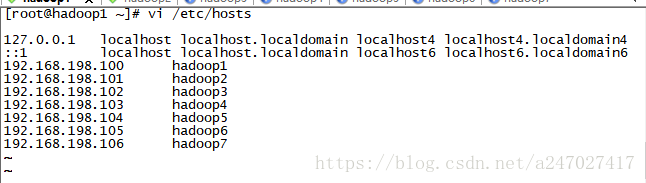
5.配置hosts
vi /etc/hosts
6.配置普通用户

7.添加sudo权限,vi /etc/sudoers

添加这一句,使用wq!强制保存退出。
7.创建压缩包存储文件夹和解压文件夹
第二步:软件安装

安装ssh,配置免密登陆
1. yum install openssh-clients -y 安装SSH服务
2. 在每台机器上生成ssh-keygen ,命令为 ssh-keygen -t rsa,然后一直回车,使用securetRT可以很方便的把命令行输入到各个terminal中
3.将各个生成的密钥复制到每个虚拟机中。ssh-copy-id hadoop1, ssh-copy-id hadoop2 .....
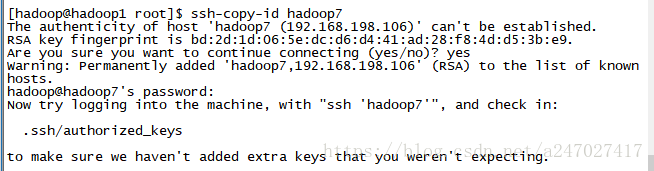
4.测试免密登陆是否完成
![]()
安装JDK
1. 使用rz命令上传java的压缩包
2. tar -zvxf jdk.***.tar.gz -C apps,解压之后改名,方便以后更换java版本,mv jdkXXX jdk
3.vi /etc/profile : JAVA_HOME=/home/hadoop/apps/jdk PATH=$JAVA_HOME/bin:$PATH
4.scp -r /home/hadoop/apps/jdk hadoop2:/home/hadoop/apps
scp -r /home/hadoop/apps/jdk hadoop3:/home/hadoop/apps .....(传到所有的机器上)
5. scp /etc/profile hadoop2:/etc/profile
scp /etc/profile hadoop3:/etc/profile ....(传到所有的机器上)
6.source /etc/profile (发送到所有页面上,securetRT的功能)
7. 使用java -version检查java环境是否配置完成

安装Zookeeper
官网下载的zookepper的压缩包,zookeeper下载
1.rz上传压缩包
2.tar -zvxf zookeeper3.4.12.tar.gz -C /home/hadoop/apps 解压缩,并且更名 mv zookeeper3.4.12 zookeeper
3.修改配置文件
cd /home/hadoop/apps/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
将其中的dataDir改成dataDir=/home/hadoop/app/zookeeper/tmp
在配置文件的最后添加
server.1=hadoop5:2888:3888
server.2=hadoop6:2888:3888
server.3=hadoop7:2888:3888
:wq,保存退出。
4. 建立新的文件夹tmp
mkdir /home/hadoop/apps/zookeeper/tmp
echo 1 > /home/hadoop/apps/zookeeper/tmp/myid 在tmp中myid中输入id。
5. 使用scp将zookeeper复制到hadoop6,hadoop7中
scp -r /home/hadoop/apps/zookeeper/ hadoop6:/home/hadoop/apps/
scp -r /home/hadoop/apps/zookeeper/ hadoop7:/home/hadoop/apps/
6. 在hadoop6中输入2作为其myid,在hadoop7中输入3作为其myid
echo 2 > /home/hadoop/apps/zookeeper/tmp/myid
echo 3 > /home/hadoop/apps/zookeeper/tmp/myid
安装Hadoop
1. 上传hadoop压缩包
2. 解压到/home/hadoop/apps下:
tar -zxvf hadoop-2.9.1.tar.gz -C /home/hadoop/apps
3. 配置文件
cd /home/hadoop/apps/hadoop/etc/hadoop
3.1 配置core-site.xml
fs.defaultFS
hdfs://pawn/
hadoop.tmp.dir
/home/hadoop/apps/hdpdata/
ha.zookeeper.quorum
hadoop5:2181,hadoop6:2181,hadoop7:2181
3.2 配置hdfs-site.xml
dfs.nameservices
pawn
dfs.ha.namenodes.pawn
pawn1,pawn2
dfs.namenode.rpc-address.pawn.pawn1
hadoop1:9000
dfs.namenode.http-address.pawn.pawn1
hadoop1:50070
dfs.namenode.rpc-address.pawn.pawn2
hadoop2:9000
dfs.namenode.http-address.pawn.pawn2
hadoop2:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop5:8485;hadoop6:8485;hadoop7:8485/pawn
dfs.journalnode.edits.dir
/home/hadoop/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.bi
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
3.3 配置mapred-site.xml
mapreduce.framework.name
yarn
3.4 配置yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
mini3
yarn.resourcemanager.hostname.rm2
mini4
yarn.resourcemanager.zk-address
mini5:2181,mini6:2181,mini7:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
更改了上述配置后,进行检查,检查core-site中的defaultFS是否和hdfs-site中的一致,根据配置的tmp.dir文件在相应的位置新建文件夹。
4. 使用scp 将hadoop复制到各台机器上。
5. 配置/etc/profile
export HADOOP_HOME=/home/hadoop/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binsource /etc/profile
启动HA
1.首先启动hadoop5,hadoop6,hadoop7上的zookeeper因为ZKFC的格式化和启动依赖zookeeper。
2.格式化hadoop1上的namenode
hdfs namenode -format3.格式化完之后,启动hadoop1的namenode,并且格式化namenode(standby),hadoop2的namenode(standby)的初始化需要与hadoop1沟通。
hadoop-daemon.sh start namenode (hadoop1上)
hdfs namenode -bootstrapStandby (hadoop2上)4.格式化ZKFC(在hadoop1上执行一次便可)
hdfs zkfc -formatZK5.启动HDFS,在hadoop1上执行便可
start-dfs.sh6.在hadoop3执行yarn
start-yarn.sh
验证完成
1. 检查各虚拟机的进程,jps
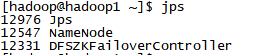
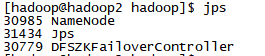
![]()
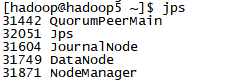

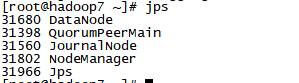
2.查看hadoop1:50070和Hadoop2:50070
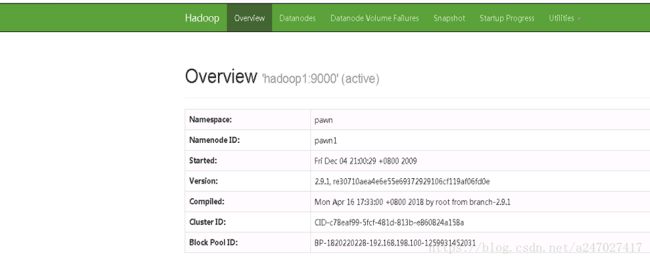
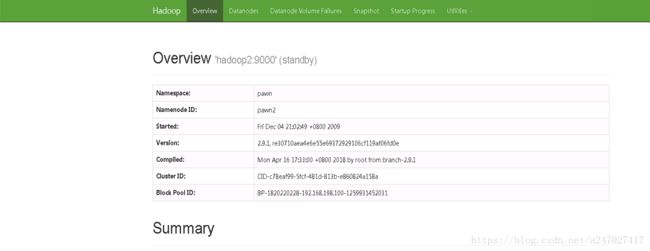
到此,对于hadoop-HA的配置已经完成了