kaggle比赛集成指南
介绍
集成模型是一种能在各种的机器学习任务上提高准确率的强有力技术。在这篇文章中,我会分享我在Kaggle比赛中的集成方法。
在第一部分中,我们会讨论从提交文件中建立集成。主要包括:
- 投票集成
- 平均
- 排名平均
第二部分我们会讨论 通过 generalization/blending等方法来创建集成。
我会在后续回答为什么集成能够减少泛化误差。最后我会展示不同的集成方法,包括它们的结果以及代码以供你自己去尝试。
怎样赢得机器学习比赛:你拿别人的结果和你自己的结果与做集成。 —— Vitaly Kuznetsov NIPS2014。
对提交文件进行集成
最简单方便的办法就是对Kaggle提交的csv文件直接进行集成。你只需要模型在测试集上的预测结果,而不需要重新训练一个模型。它简单快速,只需使用已有模型的预测结果,是拼队的理想选择。
投票集成(预测结果为类别时)
我们先看一下简单的投票集成方法。来看看为什么集成模型能够减少错误率,和为什么它能在模型间相关度较低时能取得更好的结果。
纠错码
在航天任务中,所有的信号都被正确的传达是非常重要的。
如果我们有一个二进制字符串形式的信号,如:
1110110011101111011111011011如果信号在传输过程中有一位发生了翻转(第二位),变成了
1010110011101111011111011011那这可能是致命的。
在纠错码中有一个编码 解决方案。在最简单的情况下,即纠错码是重复码时:以同样大小的数据块多次传递信号,并进行投票(以少数服从多数原则)。
Original signal:
1110110011
Encoded:
10,3 101011001111101100111110110011
Decoding:
1010110011
1110110011
1110110011
Majority vote:
1110110011信号失真很少发生且通常在局部发生,因此,多次投票依然出错的可能性就更小了。
只要信号失真不是完全不可预测的(有50%的几率发生),信号就能被修复。
一个机器学习的例子
假设我们的测试集有10个样本,正确的情况应该都是1:
1111111111我们有3个正确率为70%的二分类器记为A,B,C。你可以将这些分类器视为伪随机数产生器,以70%的概率产生”1”,30%的概率产生”0”。
下面我们会展示这些伪分类器通过投票集成的方法得到78%的正确率。
涉及到一点数学
All three are correct
0.7 * 0.7 * 0.7
= 0.3429
Two are correct
0.7 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.7
= 0.4409
Two are wrong
0.3 * 0.3 * 0.7
+ 0.3 * 0.7 * 0.3
+ 0.7 * 0.3 * 0.3
= 0.189
All three are wrong
0.3 * 0.3 * 0.3
= 0.027我们看到有44%的概率投票可以校正大部分错误。大部分投票集成会使最终的准确率变成78%左右(0.3429 + 0.4409 = 0.7838)。
投票个数
跟重复码相似,随着编码重复次数的增加对错误的校正能力也会增加,因此集成通常可以通过提高集成成员的个数来提升准确率。
同样利用上面数学的数学公式:对5个有70%准确率的伪随机分类器进行投票集成会得到83%的准确率。在大约66%的情况下投票可以校正1或2个错误编码。(0.36015 + 0.3087)
相关性
在我第一次组队参加2014年KDD杯比赛时,Marios Michailidis (KazAnova)提出了一些奇特的东西,他对我们所有的提交文件计算 皮尔逊相关系数,并且挑选出一些性能较好且相关系数较低的模型。
从这些挑选出来的文件中创建平均集成模型,给我们在排行榜上带来了巨大的提升,50名的飞跃。不相关的预测结果的集成明显比相关的集成结果要好,这是为什么?
为了说明这一点,我们再举3个简单的模型。正确的情况仍然是全是1:
1111111100 = 80% accuracy
1111111100 = 80% accuracy
1011111100 = 70% accuracy.这些模型的预测是高度相关的,当我们进行投票时,可以看到准确率没有提高:
1111111100 = 80% accuracy下面我们比较3个性能相对较差,但是高度不相关的模型:
1111111100 = 80% accuracy
0111011101 = 70% accuracy
1000101111 = 60% accuracy但我们做集成进行投票得到结果:
1111111101 = 90% accuracy结果得到了提升:集成低相关性的模型结果似乎会增加纠错能力。
Kaggle案例:森林植被类型预测

当评价指标需要有力的预测时,比如多分类问题的准确率,少数服从多数投票法具有重要意义。
森林植被类型预测 比赛使用 UCI Forest CoverType 数据集。这个数据集有54个属性,6种分类类型。
我们建立一个有500棵树的随机森林模型作为 起始模型,然后我们再建立更多的模型,并挑选出最好的一个。在这个问题中,我们选择的一个ExtraTreesClassifier 模型表现得最好。
加权
接下来,我们讨论加权投票。为什么要加权?通常我们希望模型越好,其权重就越高。所以,在这里,我们将表现最好的模型的投票看作3票,其它的4个模型只看作1票。
原因是:当表现较差的模型需要否决表现最好的模型时,唯一的办法是它们集体同意另一种选择。我们期望这样的集成能够对表现最好的模型进行一些修正,带来一些小的提高。
表一是5个模型训练出来的结果,包括结果得分以及加权的得分。
| MODEL | PUBLIC ACCURACY SCORE |
|---|---|
| GradientBoostingMachine | 0.65057 |
| RandomForest Gini | 0.75107 |
| RandomForest Entropy | 0.75222 |
| ExtraTrees Entropy | 0.75524 |
| ExtraTrees Gini (Best) | 0.75571 |
| Voting Ensemble (Democracy) | 0.75337 |
| Voting Ensemble (3*Best vs. Rest) | 0.75667 |
Kaggle案例:CIFAR-10 图像检测
CIFAR-10是另一个用准确率衡量的多分类kaggle比赛。
这个比赛中,我们队的队长Phil Culliton,从dr. Graham那复制了一个好的模型,并第一个发现最好的参数设置。
然后他对大约30个提交文件使用了投票集成的方法(所有的准确率得分在90%以上)。在集成模型中最好的单模型的得分为 0.93170.
对30个模型的投票集成得分为0.94120.大约降低了0.01错误率的,使得其识别结果超过人类 estimated human classification accuracy.
代码
我们有一个简单的投票脚本 在 MLWave Github repo中找到. 它在kaggle的提交目录中运行,并负责创建一个新的提交文件。更新:Armando Segnini 已经加上了加权部分的代码。
Ensembling.训练10个神经网络并平均它们的预测结果,这是一个相当简单的技术,却有相当大的性能改进。
这里可能会有疑惑:为什么平均会有如此大的帮助?这有一个对于平均有效的简单的原因。假设我们有2个错误率70%的分类器,当2者结果一样时,那就是这个结果;当2者发生分歧时,那么如果其中一个分类器总是正确的,那么平均预测结果就会设置更多的权重在那个经常正确的答案上。
这个作用会特别强,whenever the network is confident when it’s right and unconfident when it’s wrong.——Ilya Sutskever在深度学习的简单概述中说道。
平均
平均可以很好的解决一系列问题(二分类与回归问题)与指标(AUC,误差平方或对数损失)。
与其说平均,不如说采用了多个个体模型预测值的平均。一个在Kaggle中经常听到的词是“bagging submissions”。
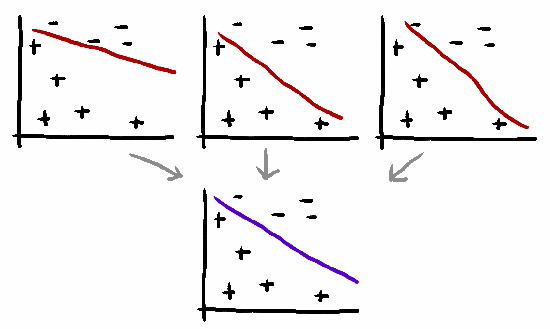
平均预测常常会降低过拟合。在类与类间,你想要理想的平滑的将其分离,而单一模型的预测在边界间可能会有一些粗糙。

上面这幅图片来自这个kaggle比赛:不要过拟合!图中黑线比绿线有更好的分割,绿色线已经从数据点中学习了一些噪声。但不用担心,平均多个不同的绿线应该使我们更接近黑线。
记住,我们的目标不仅是去记住这些训练数据(这里有比在随机森林里更加有效的方法来存储数据),而且还要去对我们没有看到的数据进行良好的泛化。
Kaggle案例: Bag of Words Meets Bags of Popcorn

这是一个电影情感分析竞赛,在以前的文章中,我们使用 在线感知机脚本 得到了0.952的AUC.
这个感知机是一个线性分类器,在数据线性可分的情况下一定能找到一个分隔。这是一个受人喜欢的性质,但是你要意识到一旦达到这种分隔,分类器就会停止学习。它不一定会是新数据的最好的分隔。
那当我们随机初始化5个感知机的权重,并通过平均来组合预测会发生什么?结果是我们在测试集上的结果得到了提升,但这是为什么呢?
| MODEL | PUBLIC AUC SCORE |
|---|---|
| Perceptron | 0.95288 |
| Random Perceptron | 0.95092 |
| Random Perceptron | 0.95128 |
| Random Perceptron | 0.95118 |
| Random Perceptron | 0.95072 |
| Bagged Perceptrons | 0.95427 |
以上结果还能说明,集成能(暂时)使您不必了解特定机器学习算法的更精细的细节与内部工作原理。如果集成起作用,那很好,如果没起作用,那并无大碍。
就算你平均10个相同的线性回归的结果也没事。Bagging一个糟糕的交叉验证与过拟合的提交有可能会增加多样性从而给你带来一点提高。
代码
我们已经在Github上发布了一个 平均脚本,它以.csv文件作为输入并得到一个平均的提交结果。更新:Dat Le已经添加了一个 几何平均的脚本。几何平均能比普通平均表现的更好。
排名平均
当平均多个来自不同模型的输出时,会出现一些问题。并不是所有的预测器的结果是完美 校准的, 它们可能会产生过高或过低的预测概率,或者预测在一定的范围里非常混乱。
在极端情况下,你可能会有一个这样一个提交:
Id,Prediction
1,0.35000056
2,0.35000002
3,0.35000098
4,0.35000111当评估指标是ranking或者像AUC一样的阈值时,这些预测结果可能会在排行榜上表现的较好。但是当与类似下面这个模型进行平均时:
Id,Prediction
1,0.57
2,0.04
3,0.96
4,0.99集成不会改变什么。
我们的解决方案是:首先将预测结果进行一个排名,然后去平均这个排名。
Id,Rank,Prediction
1,1,0.35000056
2,0,0.35000002
3,2,0.35000098
4,3,0.35000111在标准化平均排名在0到1之间后,你肯定会得到一个均匀分布预测。排名平均结果:
Id,Prediction
1,0.33
2,0.0
3,0.66
4,1.0历史排名
排名需要一个测试集,所以当你要预测一个新样本时,你该怎么办?你可以与老的测试集一起,重新计算排名,但这会增加你的解决方案的复杂性。
一个解决方案是使用历史排名。存储旧的测试集预测及其排名,现在当你预测一个新的测试样例如“0.35000110”,你去找到最接近的历史预测并取其历史排名(在这里最接近的历史预测是“0.35000111”其历史排名为“3”)。
Kaggle使用案例:获得有价值的顾客挑战赛
排名平均在基于排名和基于阈值的指标(如AUC)和搜索引擎质量指标(如k平均精度)上表现良好。
这个 挑战赛的目标 是对一个购物者成为一个重复顾客的概率进行排名。
我们队首先将多个Vowpal Wabbit中的模型与一个R语言的GLMNet模型进行取平均,然后我们使用排名平均来提高完全相同的集成的情况。
| MODEL | PUBLIC | PRIVATE |
|---|---|---|
| Vowpal Wabbit A | 0.60764 | 0.59962 |
| Vowpal Wabbit B | 0.60737 | 0.59957 |
| Vowpal Wabbit C | 0.60757 | 0.59954 |
| GLMNet | 0.60433 | 0.59665 |
| Average Bag | 0.60795 | 0.60031 |
| Rank average Bag | 0.61027 | 0.60187 |
我已经在 Avito挑战赛中写过排名平均给了我们大幅的提升 。
finnally, when weighted rank averaging the bagged perceptrons from the previous chapter (1x) with the new bag-of-words tutorial (3x) on fastML.com we improve that model’s performance from 0.96328 AUC to 0.96461 AUC.
代码
排名平均脚本 已被添加到了MLWave Github repos上。
比赛是一种有效的方式,因为有无数的技术可以在建模问题上使用,但我们不能提前知道哪些将是最有效的。Anthony Goldbloom 在 Data Prediction Competitions — Far More than Just a Bit of Fun上说。
Stacked Generalization & Blending
对预测文件进行平均既简单又好用,但这并不是顶级kaggle选手使用的唯一方法。stacking与blending也能让你颇受收益。做好心理准备,接来下将要给你介绍屠龙技。
Netflix
Netdlix公司曾组织并普及了第一次数据科学比赛,在电影推荐挑战赛中,参赛者们将集成发展成为了一门艺术,可能是太极端了以至于Netfilx公司决定不将获胜方案应用到产品中。 因为这实施起来太复杂了。
不过,这个比赛涌现了很多论文与新颖的方法:
- Feature-Weighted Linear Stacking
- Combining Predictions for Accurate Recommender Systems
- The BigChaos Solution to the Netflix Prize
这些论文都比较有趣且可以阅读的,当你想要提高你在Kaggle比赛中的成绩时,可以点进去阅读一下。

这是我工作这么多年以来,最令人印象深刻的集成和看到的最好的成果,它融合了上百个预测模型来得到最终结果。我们在线下使用了一些新方法重新评估了一番,但是我们测试认为该模型对准确率提升效果似乎并不值得将它引入到生产环境——-Netflix 的工程师说。
Stacked generalization
Wolpert在1992的论文中对stacked generalization进行了介绍,比Breiman的论文 “Bagging Predictors“早了2年。Wolpert的另一成名的机器学习理论是:“没有免费午餐定理”
stacked generalization背后的基本思想是使用大量基分类器,然后使用另一种分类器来融合它们的预测,旨在降低泛化误差。
下面来说下2折stacking:
- 将训练集分成2部分: train_a 与 train_b
- 用train_a来拟合一个初级学习器对train_b进行预测
- 用train_b来拟合同类型的学习器对train_a进行预测
- 最后用整个训练集拟合模型,并对测试集进行预测
基于初级学习器的概率输出,来训练次级学习器
一个stacker模型通过使用第一阶段的预测作为特征,比相互独立的训练模型能够得到更多的信息。
我们通常希望在第0层泛化器是全类型的,而不仅仅是彼此的简单变化(比如我们想要 surface-fitters, Turing-machine builders, statistical extrapolators等等.)这样,所有可能学习到训练集规律的方法都会被使用到, 这就是所谓的初级学习器应该“跨越空间”意思的一部分.
[…]stacked generalization是将非线性泛化器组合从而形成新的泛化器的手段,是为了尝试最好的集成每个初级泛化器。每个学习器信息越多(在其他学习器上没有重复),stacked generalization的结果就越好
Wolpert (1992) Stacked Generalization
Blending
Blending 一词是Netflix的获胜者们引入的。它与stacked generalization非常像,但更简单并且信息泄露风险更小。一些研究者们交换着使用“stacked ensembling”与“blending”这2个词。
通过Blinding,不需要对训练集创建折外预测(out-of-fold predictions ),你只需创建一个小的留出集,比如10%的训练集做为留出。stacker模型只在留出集里面进行训练。
Blending的优势:
- 比stacking更加简单
- 能够防止信息泄露:generalizers和stackers使用不同的数据
- 你不需要跟你的队友设定一个相同的随机种子来进行相同的分折 谁都可以将模型放入“blender”中,由blender来决定是否保留这个模型。
缺点:
- 只使用了整体中数据一部分
- 最终的模型有可能对留出集过拟合
- stacking使用交叉验证比使用单一留出集更加稳健 (在更多的折上进行计算)。
至于性能,两种技术的得到的结果差不多,取决于你的个人喜好以及你更倾向于哪种技能。就我自己而言,我更喜欢stacking。
如果你不能做选择的话,你可以同时选择这2种,使用stacked泛化器创建stacked集成和折外预测。然后使用留出集在第三层进一步结合这些stacked模型。
Stacking with logistic regression
使用逻辑斯谛回归做融合是一个非常经典的stacking方法。我找到一个脚本很好的帮助我理解了这一方法。
当创建一个用于预测的测试集时,你可以一次性完成该操作,或者利用折外估计的模型(out-of-fold predictors)完成。当然为了减少模型和代码的复杂性,我更倾向于一次性完成。
kaggle案例:“Papirusy z Edhellond”
在这个比赛中,我使用上面的blend.py脚本,结合了8个模型(不同评价指标的ET RF GMB),然后使用逻辑斯谛回归给了我第2名的成绩。
Kaggle案例: KDD-cup 2014
使用这个脚本,我将Yan XU的AUC评分从0.605提高到了0.625。
Stacking with non-linear algorithms
目前流行用于Stacking的非线性算法有GBM,KNN,NN,RF和ET。
非线性的Stacking在多分类任务中,使用原始特征就能产生令人惊讶的提升。显然,在第一阶段中的预测提供了非常丰富的信息并得到了最高的特征重要性。非线性算法有效地找到了原始特征与元模型特征之间的关系。
Kaggle案例: TUT Headpose Estimation Challenge
在TUT Headpose Estimation比赛中,可以当做是一个多分类,多标签的问题。
对于每一个标签,将分别训练一个独立的集成模型。
接下来的表格显示了每个独立模型的得分表现,以及当他们使用extremely randomized trees来做stacking时提高的得分。
| MODEL | PUBLIC MAE | PRIVATE MAE |
|---|---|---|
| Random Forests 500 estimators | 6.156 | 6.546 |
| Extremely Randomized Trees 500 estimators | 6.317 | 6.666 |
| KNN-Classifier with 5 neighbors | 6.828 | 7.460 |
| Logistic Regression | 6.694 | 6.949 |
| Stacking with Extremely Randomized Trees | 4.772 | 4.718 |
我们看到使用了stack后,误差减少了将近30%
有兴趣的可以在Computer Vision for Head Pose Estimation: Review of a Competition看到这一结果的论文。
代码
你可以在 out-of-fold probability predictions的MLWave Github repo中找到一个函数去使用out-of-fold probability predictions。你也可以使用numpy horizontal stacking (hstack)去创建融合数据。
Feature weighted linear stacking
t线性加权stacking就是,先将提取后的特征用各个模型进行预测,然后使用一个线性的模型去学习出哪个个模型对于某些样本来说是最优的,通过将各个模型的预测结果加权求和完成。使用线性的算法可以非常简单快捷地去验证你的模型,因为你可以清楚地看到每个模型所分配的权重。

Vowpal Wabbit对于线性加权stacking提出了一种创新性的用法。比如我们有以下训练集,它有两个特征空间,一个是f,一个是s:
1 |f f_1:0.55 f_2:0.78 f_3:7.9 |s RF:0.95 ET:0.97 GBM:0.92
我们可以通过-q fs来构造二次方的特征,它是 s-特征空间和f-特征空间的交互项。在f-特征空间中的特征可以是原始的特征,也可以是例子中的元特征。
Quadratic linear stacking of models
这方法并没有名字,所以我给他造了一个。这方法跟线性stacking非常像,但它在线性的基础上,额外构造了一系列模型之间预测结果的组合。这一方法在许多次实验中都对评分有很大的提高。最值得提到的是在DrivenData上的比赛: Modeling Women’s Healthcare Decision competition
我们同样使用之前提到的VW训练集:
1 |f f_1:0.55 f_2:0.78 f_3:7.9 |s RF:0.95 ET:0.97 GBM:0.92我们可以使用-q ss 训练从而创建出s-特征空间中模型预测之间的二阶特征交互项(如RF*GBM)。
它与线性加权stacking可以非常简单地结合起来,比如说先算f和s的交互项,再加上s和s的交互项:-q fs -q ss
So now you have a case where many base models should be created. You don’t know apriori which of these models are going to be helpful in the final meta model. In the case of two stage models, it is highly likely weak base models are preferred.
So why tune these base models very much at all? Perhaps tuning here is just obtaining model diversity. But at the end of the day you don’t know which base models will be helpful. And the final stage will likely be linear (which requires no tuning, or perhaps a single parameter to give some sparsity). Mike KimTuning doesn’t matter. Why are you doing it?
Stacking 分类和回归
Stacking可以允许你使用分类器来完成回归问题,反之亦然。比如说,在一个二分类问题中,有人可能会尝试使用线性分位回归 来完成分类任务。一个好的stacker应该可以从预测中提取出你想要的信息,尽管回归通常并不是一个好的分类器。
而使用一个分类器做回归就有点棘手。你先离散化:将y均匀地分为几个的类别。那么一个要求你预测工资的回归问题就可以转换为这样的一个多分类的问题:
- 所有低于20k的为类别1
- 所有20k到40k之间的为类别2
- 所有大于40k的为类别3
使用分类器预测出来的概率可以帮助回归函数取得更好的预测效果。
Stacking无监督特征学习
没有任何人说过我们使用stacking的时候一定要是有监督的。事实上你可以使用stacking技术来处理无监督学习的问题。
k-means聚类是最为流行的无监督算法。Sofia-ML实现了一个快速的在线k-means算法适用于这里。
其他有意思的方法是 t-SNE:通过把数据降维2到3维,然后将它放到非性融合器来融合。使用留出集的方法感觉上是最安全的选择。可以看看由 Mike Kim提出的解决方案,他使用了t-SNE向量,然后结合了xgboost: 0.41599 via t-SNE meta-bagging

Piotr给出的 t-SNE在分类任务中的可视化表现
Online Stacking
我花了大量时间去研究一个叫online stacking的想法:首先从一个哈希二值映射中创建一个小型的随机树。如果树预测正确则增加其收益,反之减少其收益。然后我们将收益最大的树,和收益最小树的预测作为特征。
它确实有效,然而只限于人造的数据,它确实可以把异或问题(XOR-problem)学习出来。但是它没有在任何真实数据集上成功过,相信我,我已经试过了。所以,从此之后,对于只使用人造数据去验证它们的新算法的论文,我都会持怀疑的态度。
一个相似的想法在一篇论文中是有效的: random bit regression。在这里,从特征中构造了多个随机的线性函数,最好的函数是由很强的正则项中产生的。这个方法我曾经在一些数据集上成功过。这会是我将来发表的主题。
一个(半)online stacking更加具体的例子是广告点击预测问题。模型会在用户近期行为的数据中预测更准,也就是当数据集具有时间效应的时候,你可以使用Vowpal Wabbit去训练整个数据集,并使用一个更加复杂的工具比如说xgboost去训练最后几天的数据。你只需将xgboost的结果与样本进行堆叠(stack),并让Vowpal Wabbit尽其所能:优化损失函数。
The natural world is complex, so it figures that ensembling different models can capture more of this complexity. Ben Hamner ‘Machine learning best practices we’ve learned from hundreds of competitions’ (video)
一切皆为超参数(hyper-parameter)
当我们使用stacking/blending/meta-modeling时,一个良好的想法就是所有的行为都是融合模型的参数。
比如说:
- 不标准化数据
- 使用z标准化
- 使用0-1标准化
这些都是可以去调从而提高集成的效果。同样的,使用多少个基模型的数量也是可以去调整优化的。特征选择(前70%)或数据填补(缺失填补)也是一系列的参数。
使用随机网格搜索就是一个比较好的调参方法,它在调整这些参数的时候确实是有起到作用的。
模型选择
你还可以通过组合多个集成模型来继续优化你评分。
- 这有一个特别的方法:使用平均,投票,或秩平均等方法来手动选择表现好的集成模型。
- 贪婪前向模型选择 (Caruana et al.)。先使用一个或几个好的模型作为基集成模型。然后不断地增加使得评分提升最大的模型。当然你也可以在期间允许把模型放回去,这样的话一个模型可能会被选择很多次。
- 使用遗传算法来做选择,用交叉验证得分作为适应度评分函数。可以看 inversion‘s solution 的解决方案:‘Strategy for top 25 position‘.
- 受Caruana的启发,我使用一个完全随机的方法:通过随机选择集成(无放回),创建一个100或其他个数的集成。然后选择其中评分最高的模型。
自动化操作
当我在 Otto product classification比赛中,使用了stacking策略,我很快的得到了前十的成绩。我通过不断的添加越来越多的基分类器,和bagging多个stack集成我的分数得到不断的提高。
当我达到了7个基模型,用了6个stacker,一阵恐惧和忧郁的感觉向我袭来。我是否能够把所有这些都重现?这些复杂而又笨重的模型让我偏离了快速而又简单的机器学习的初衷。
我在后续的比赛中,都将时间花在了建造一个自动化stacking的方法。我们去训练那些具有纯随机参数的纯随机算法的基模型。我们写了一个与Scikit-learn的Api协同工作的封装器去负责训练分类模型VW, Sofia-ML, RGF, MLP and XGBoost。
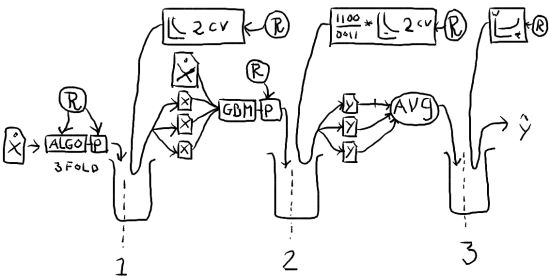
并行自动stacker的草稿
使用自动化stacking可以让你轻松的打败那些对该问题设计特定算法的领域专家,各个模型的训练都是可以分布式和并行化的。
你也可以在这里看到自动化融合的代码:MLWave Github repo: “Hodor-autoML“.
在Otto product 分类比赛中,第1名和第2名融合了超过1000个不同的模型 可以在这里看到更多: first place 和 second place。
我们为什么要使用如此复杂的集成方法?
使用stacking,组合1000多个模型,计算几十个小时这也太疯狂了吧。这..确实是的。但是,这些怪物般的集成方法同样有着它的用处:
- 它可以使你赢得kaggle比赛
- 它可以帮你打败当前学术界性能最好的算法
- You can then compare your new-and-improved benchmark with the performance of a simpler, more production-friendly model
- 总有一天,虽然现在的计算机和云端还是很弱。你将做好准备
- 我们有可能将集成的知识迁移到到简单的分类器上(Hinton’s Dark Knowledge, Caruana’sModel Compression)
- 不是所有基模型都要按时完成的。因为在集成方法中,即使损失一两个模型也是可以接受的。
- 自动化的大型集成策略可以通过添加正则项有效的对抗过拟合,而且并不需要太多的调参和特征选择。所以从原则上讲,stacking非常适合于那些“懒人”
- 这是目前提升机器学习效果最好的方法,或者说是最效率的方法human ensemble learning
- 每1%精度的提升,或许就可以使得你的投资减少大量的损失。更严肃的说:在医疗行业中,每1%的提升,你就能多拯救几个生命。
这一论文的代码在:https://github.com/MLWave/Kaggle-Ensemble-Guide上
阅读扩展:
- “More is always better – The power of Simple Ensembles” by Carter Sibley
- “Tradeshift Benchmark Tutorial with two-stage SKLearn models” by Dmitry Dryomov
- “Stacking, Blending and Stacked Generalization” by Eric Chio
- Ensemble Learning: The wisdom of the crowds (of machines) by Lior Rokach,
- “Deep Support Vector Machines” by Marco Wiering
The natural world is complex, so it figures that ensembling different models can capture more of this complexity. Ben Hamner ‘Machine learning best practices we’ve learned from hundreds of competitions’ (video)
原文链接:http://mlwave.com/kaggle-ensembling-guide/
译者:乔杰、胡涛
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者a358463121专栏:http://blog.csdn.net/a358463121,如果涉及源代码请注明GitHub地址:https://github.com/358463121/。商业使用请联系作者。