XGBoost+LR融合方案
XGBoost+LR融合方案
这是14年,facebook提出的一种融合方法。他的核心思想是将boosting看作是一个将样本进行非线性变换的方法。那么我们处理特征变换的一般方法有:
- 对于连续的特征:一个简单的非线性变化就是将特征划分到不同的区域(bin),然后再将这些区域的编号看作一个离散的特征来进行训练。这也就是俗称的连续变量离散化方法,这有非常多的方法可以完成这项事情。
- 对于离散的特征:我们可以直接对离散特征做一个笛卡尔积从而得到一系列特征的组合,当然有些组合是没用的,那些没用的组合可以删掉。
而这里我们要介绍的是另一种特征变换的方法,利用boosting来对样本进行离散化的方法。
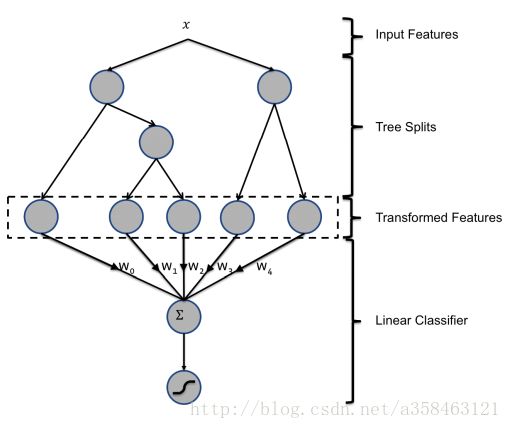
我们知道对每一个样本,都对应着每颗树上的一个叶子结点,比如说如上图,我们一共训练了2颗树,一共有5个叶子结点,那么我们可以将这5个叶子结点进行编号,然后用1-k ont hot来表示他们的取值,如果x样本在第一颗树中经过映射到达第2个叶子结点,在第二颗树上到达第二棵树上的第一个叶子结点,那么我们就可以得到样本经过变化后的向量为 [0,1,0,1,0] ,这5个数就表示叶子结点的,1对应的就是将样本是否落在了这个叶子结点上。直观来看,我们将一个样本向量,经过变换成了一个0,1的向量。最后我们使用经过变换后的特征再放进任意一个训练器中训练,比如说LR。
xgboost中的例子
data(agaricus.train, package='xgboost')
data(agaricus.test, package='xgboost')
dtrain <- xgb.DMatrix(data = agaricus.train$data, label = agaricus.train$label)
dtest <- xgb.DMatrix(data = agaricus.test$data, label = agaricus.test$label)
param <- list(max_depth=2, eta=1, silent=1, objective='binary:logistic')
nround = 4
bst = xgb.train(params = param, data = dtrain, nrounds = nround, nthread = 2)
# Model accuracy without new features
accuracy.before <- sum((predict(bst, agaricus.test$data) >= 0.5) == agaricus.test$label) /
length(agaricus.test$label)
# Convert previous features to one hot encoding
new.features.train <- xgb.create.features(model = bst, agaricus.train$data)
new.features.test <- xgb.create.features(model = bst, agaricus.test$data)
# learning with new features
new.dtrain <- xgb.DMatrix(data = new.features.train, label = agaricus.train$label)
new.dtest <- xgb.DMatrix(data = new.features.test, label = agaricus.test$label)
watchlist <- list(train = new.dtrain)
bst <- xgb.train(params = param, data = new.dtrain, nrounds = nround, nthread = 2)
# Model accuracy with new features
accuracy.after <- sum((predict(bst, new.dtest) >= 0.5) == agaricus.test$label) /
length(agaricus.test$label)
# Here the accuracy was already good and is now perfect.
cat(paste("The accuracy was", accuracy.before, "before adding leaf features and it is now",
accuracy.after, "!\n"))里面的函数xgb.create.features就是对样本进行变换的函数。这里面的例子没有用到LR,而是XGB+XGB了,你也可以用LR来做第二次训练。
LightGBM也可以实现类似的效果,我们只要利用predict(X, pred_leaf=True)这个函数就可以,
或者lgb也可以直接用以下这个函数来代替xgb.create.features:
library(xgboost)
library(Matrix)
lgb.create.features<-function (model, data)
{
pred_with_leaf <- predict(model, data, predleaf = TRUE)
cols <- lapply(as.data.frame(pred_with_leaf), factor)
cBind(data, sparse.model.matrix(~. - 1, cols))
}github上有一个实现lgb+lr的代码:https://github.com/neal668/LightGBM-GBDT-LR/blob/master/GBFT%2BLR_simple.py
参考资料
He, Xinran, et al. “Practical lessons from predicting clicks on ads at facebook.” Proceedings of the Eighth International Workshop on Data Mining for Online Advertising. ACM, 2014.
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者a358463121专栏:http://blog.csdn.net/a358463121,如果涉及源代码请注明GitHub地址:https://github.com/358463121/。商业使用请联系作者。