码农翻身讲网络3:从Socket编程到HTTP服务器
小白科普:从输入网址到最后浏览器呈现页面内容,中间发生了什么?(HTTP请求)
1前言
这篇文章是应网友之邀所写,主要描述一下我们访问网站时, 从输入网址到最后浏览器呈现内容,中间发生了什么。
之前写过两篇文章《我是一个网卡》,《我是一个路由器》描述了一个电脑如何通过DHCP、ARP、NAT等上式获取IP、然后访问网络的过程,主要专注在传输层和网络层。
今天的文章主要专注于应用层,我拿了一个很简单的网络结构来讲。假定本机已经获取了IP地址,各种网络基础设施已经准备好了。
由于知识点太多,我肯定会漏掉部分内容,欢迎在留言中补充, 以后我会根据大家建议再写文章扩展。
2准备
当你在浏览器中输入网址(例如www.coder.com)并且敲了回车以后, 浏览器首先要做的事情就是获得coder.com的IP地址,具体的做法就是发送一个UDP的包给DNS服务器,DNS服务器会返回coder.com的IP, 这时候浏览器通常会把IP地址给缓存起来,这样下次访问就会加快。
比如Chrome, 你可以通过chrome://net-internals/#dns来查看。
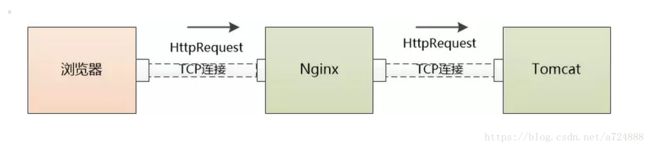
有了服务器的IP, 浏览器就要可以发起HTTP请求了,但是HTTP Request/Response必须在TCP这个“虚拟的连接”上来发送和接收。
想要建立“虚拟的”TCP连接,TCP邮差需要知道4个东西:(本机IP, 本机端口,服务器IP, 服务器端口),现在只知道了本机IP,服务器IP, 两个端口怎么办?
本机端口很简单,操作系统可以给浏览器随机分配一个, 服务器端口更简单,用的是一个“众所周知”的端口,HTTP服务就是80, 我们直接告诉TCP邮差就行。
经过三次握手以后,客户端和服务器端的TCP连接就建立起来了! 终于可以发送HTTP请求了。
之所以把TCP连接画成虚线,是因为这个连接是虚拟的, 详情可参见之前的文章《TCP/IP之大明邮差》,《张大胖的Socket》
3Web服务器
一个HTTP GET请求经过千山万水,历经多个路由器的转发,终于到达服务器端(HTTP数据包可能被下层进行分片传输,略去不表)。
Web服务器需要着手处理了,它有三种方式来处理:
(1) 可以用一个线程来处理所有请求,同一时刻只能处理一个,这种结构易于实现,但是这样会造成严重的性能问题。
(2) 可以为每个请求分配一个进程/线程,但是当连接太多的时候,服务器端的进程/线程会耗费大量内存资源,进程/线程的切换也会让CPU不堪重负。
(3) 复用I/O的方式,很多Web服务器都采用了复用结构,例如通过epoll的方式监视所有的连接,当连接的状态发生变化(如有数据可读), 才用一个进程/线程对那个连接进行处理,处理完以后继续监视,等待下次状态变化。 用这种方式可以用少量的进程/线程应对成千上万的连接请求。
(码农翻身注:详情参见《Http Server:一个差生的逆袭》)
我们使用Nginx这个非常流行的Web服务器来继续下面的故事。
对于HTTP GET请求,Nginx利用epoll的方式给读取了出来, Nginx接下来要判断,这是个静态的请求还是个动态的请求啊?
如果是静态的请求(HTML文件,JavaScript文件,CSS文件,图片等),也许自己就能搞定了(当然依赖于Nginx配置,可能转发到别的缓存服务器去),读取本机硬盘上的相关文件,直接返回。
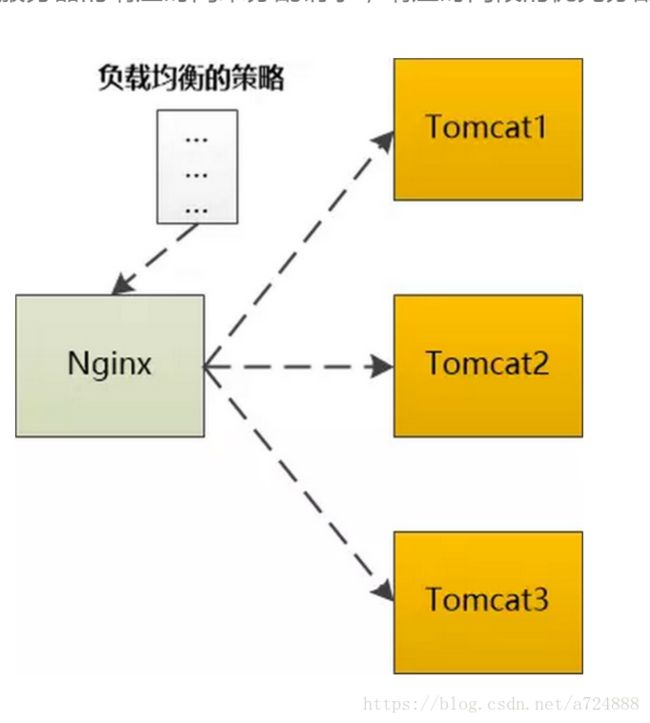
如果是动态的请求,需要后端服务器(如Tomcat)处理以后才能返回,那就需要向Tomcat转发,如果后端的Tomcat还不止一个,那就需要按照某种策略选取一个。
例如Ngnix支持这么几种:
轮询:按照次序挨个向后端服务器转发
权重:给每个后端服务器指定一个权重,相当于向后端服务器转发的几率。
ip_hash: 根据ip做一个hash操作,然后找个服务器转发,这样的话同一个客户端ip总是会转发到同一个后端服务器。
fair:根据后端服务器的响应时间来分配请求,响应时间段的优先分配。
不管用哪种算法,某个后端服务器最终被选中,然后Nginx需要把HTTP Request转发给后端的Tomcat,并且把Tomcat输出的HttpResponse再转发给浏览器。
由此可见,Nginx在这种场景下,是一个代理人的角色。
5应用服务器
Http Request终于来到了Tomcat,这是一个由Java写的、可以处理Servlet/JSP的容器,我们的代码就运行在这个容器之中。
如同Web服务器一样, Tomcat也可能为每个请求分配一个线程去处理,即通常所说的BIO模式(Blocking I/O 模式)。
也可能使用I/O多路复用技术,仅仅使用若干线程来处理所有请求,即NIO模式。
不管用哪种方式,Http Request 都会被交给某个Servlet处理,这个Servlet又会把Http Request做转换,变成框架所使用的参数格式,然后分发给某个Controller(如果你是在用Spring)或者Action(如果你是在Struts)。
剩下的故事就比较简单了(不,对码农来说,其实是最复杂的部分),就是执行码农经常写的增删改查逻辑,在这个过程中很有可能和缓存、数据库等后端组件打交道,最终返回HTTP Response,由于细节依赖业务逻辑,略去不表。
根据我们的例子,这个HTTP Response应该是一个HTML页面。
6归途
Tomcat很高兴地把Http Response发给了Ngnix 。
Ngnix也很高兴地把Http Response 发给了浏览器。

发完以后TCP连接能关闭吗?
如果使用的是HTTP1.1, 这个连接默认是keep-alive,也就是说不能关闭;
如果是HTTP1.0,要看看之前的HTTP Request Header中有没有Connetion:keep-alive,如果有,那也不能关闭。
7浏览器再次工作
浏览器收到了Http Response,从其中读取了HTML页面,开始准备显示这个页面。
但是这个HTML页面中可能引用了大量其他资源,例如js文件,CSS文件,图片等,这些资源也位于服务器端,并且可能位于另外一个域名下面,例如static.coder.com。
浏览器没有办法,只好一个个地下载,从使用DNS获取IP开始,之前做过的事情还要再来一遍。不同之处在于不会再有应用服务器如Tomcat的介入了。
如果需要下载的外部资源太多,浏览器会创建多个TCP连接,并行地去下载。
但是同一时间对同一域名下的请求数量也不能太多,要不然服务器访问量太大,受不了。所以浏览器要限制一下, 例如Chrome在Http1.1下只能并行地下载6个资源。
当服务器给浏览器发送JS,CSS这些文件时,会告诉浏览器这些文件什么时候过期(使用Cache-Control或者Expire),浏览器可以把文件缓存到本地,当第二次请求同样的文件时,如果不过期,直接从本地取就可以了。
如果过期了,浏览器就可以询问服务器端,文件有没有修改过?(依据是上一次服务器发送的Last-Modified和ETag),如果没有修改过(304 Not Modified),还可以使用缓存。否则的话服务器就会被最新的文件发回到浏览器。
当然如果你按了Ctrl+F5,会强制地发出GET请求,完全无视缓存。
注:在Chrome下,可以通过 chrome://view-http-cache/ 命令来查看缓存。
现在浏览器得到了三个重要的东西:
1.HTML ,浏览器把它变成DOM Tree
2. CSS, 浏览器把它变成CSS Rule Tree
3. JavaScript, 它可以修改DOM Tree
浏览器会通过DOM Tree和CSS Rule Tree生成所谓“Render Tree”,计算每个元素的位置/大小,进行布局,然后调用操作系统的API进行绘制,这是一个非常复杂的过程,略去不表。
到目前为止,我们终于在浏览器中看到了www.coder.com的内容。
张大胖的socket
他终于明白了所谓IP层就是把数据分组从一个主机跨越千山万水搬运到另外一主机, 并且这搬运服务一点都不可靠, 丢包、重复、失序可以说是家常便饭, 怪不得说是“尽力而为”, 基本上无所作为。
脏活累活只好让TCP来做了, 在两个主机的应用(进程)之间通过失败重传来实现可靠性的传输。
张大胖经常感慨:这建立一个TCP连接可是相当的复杂, 我的程序得先和远端的服务器打个招呼, 然后它再给我打个招呼确认, 我还得再给它确认下。 这还不算完, 我们的招呼中还得各自带上各自的序号, 这将来传输真正的数据时用到。
具体的传输就更麻烦了, 什么滑动窗口,什么累积确认、分组缓存、流量控制, 简直不是人做的事情。
到了断开连接的时候, 还得考虑友好分手!
张大胖掂量了下自己, 觉得肯定搞不定, 于是赶紧向自己的好基友,编程大神Bill求救, Bill 在电话里说: “这很简单啊,你去看看TCP/IP协议的RFC, 然后用C语言编程实现不就行了吗。”
张大胖心想这等于啥也没说, 继续“跪求” 。 Bill 终于说:“等着吧, 我下周给你”
Socket周一, Bill果然带着7、8张软盘来找张大胖了, 把软盘的程序分别Copy到了两个电脑里, 一个模拟客户端, 一个模拟服务器。 很快程序运行起来了, 两个电脑可以通过TCP通信了。
张大胖说: “大神, 你是怎么做到的?”
Bill说:“TCP协议的确很复杂, 我们不能要求每个程序员都去实现建立连接的3次握手, 累积确认,分组缓存, 这些应该是属于操作系统内核的部分, 没必要重复开发, 但是对于应用程序来讲, 操作系统需要抽象出一个概念, 让上层应用去编程。 “
“什么概念?”
“socket”
”为啥叫socket? “
"一个比喻而已, 就像插座一样, 一个插头插进插座, 建立了连接。 不过我设计这个socket 可以理解为 (客户端IP, 客户端Port, 服务器端IP, 服务器端Port), 对了, Port就是端口, 通俗点讲就是一个数字而已"
“好像不用port就可以吧, 因为我们这是两个机器之间的通信, IP是不是就够了?”
Bill 说:“看来你忘了, TCP是两个进程之间的通信, 客户端上可以有很多进程同时访问多个服务器, 服务器上也有多个进程对外提供服务, 肯定要区分开啊”
张大胖不好意思的说: “原来端口号就是用来区分进程的, 这样IP层发过来的数据包, 到达TCP层以后就可以分发给各个应用程序了。 ”
“对的, 这叫多路复用。 一般来说, 服务器端都是被动访问的, 所以大家需要知道它提供服务的端口号, 要不然怎么连接? 例如80, 443等, 就是所谓知名端口号; 而客户端访问服务器的时候,自己的端口号可以随机生成一个, 只要不和别的应用冲突即可。”

Socket编程张大胖问道: “那具体怎么使用你的Socket来编程? ”
“这要分为客户端和服务器端,两者不一样, 对客户端来讲很简单, 你需要创建一个socket, 然后向服务器发起连接, 连接上以后就可以发送,接收数据了, 你看看这段伪代码“

"恩, 抽象以后果然是不一样, 那些烦人的细节都被隐藏了, 只剩下一些概念性的东西, 用起来很清爽, 这个clientfd 我猜就是一个像文件描述符那样的东西吧? 打开文件就会有一个"
“对的, 很好的类比, 注意,在上面的伪码中,没有出现客户端的ip和端口, 系统可以自动获得IP, 也可以自动分配端口。 还有, 看到那个connect 函数没有, 其实就是在和服务器发起三次握手呢。 ”
“那服务器怎么响应?”
“服务器端要复杂一些, 你想想看, 第一, 服务器是被动的, 所以它启动以后, 需要监听客户端发起的连接, 第二, 服务器要应付很多的客户端发起连接, 所以它一定得各个socket给区分开了, 要不就乱了套了, 伪代码是这个样子的:”

张大胖说: “果然是复杂多了, listenfd ,从名称看就是为了要监听而创建的socket描述符吧, bind 是干嘛? 嗯, 我猜是为了声明说我要占用这个端口了啊, 你们都别用了, listen函数才是真正开始监听了。
慢着,我赛, 接下来是个死循环啊, 啊对对,服务器端一直提供服务, 永不停歇。 可是这个accept是干嘛, 为什么使用了listenfd , 然后返回了一个新的connfd ???”
Bill满意的说: “不错,思考就有进步, 可是你忘了我刚说的东西了, 服务器要区分开各个客户端, 怎么区分呢? 那只有用一个新的socket来表示喽, 你看后面的操作都是基于connfd 来做的。 还有 这个accept 相当于和客户端的connect 一起完成了TCP的三次握手 ! 至于之前的listenfd , 它只起到一个大门的作用了, 意思是说,欢迎敲门, 进门之后我将为你生成一个独一无二的socket描述符! ”

“有道理, 大神果然是大神, 考虑的非常全面啊, 不过似乎有个漏洞,你一开始说socket指的是 (IP, Port), 现在你已经有了一个listenfd 的socket, 端口是80 然后每次客户端发起连接还要创建新的connfd, 因为80端口已经被占用,难道服务器端会为每个连接都创建新的端口吗?”
"这是个好问题啊" Bill 说 “其实新创建的connfd 并没有使用新的端口号,也是用的80, 可以这么理解,这个socket描述符指向一个数据结构, 例如 listenfd 指向的结构是这样的:”

“而一旦accept 新的连接, 新的connfd 就会生成, 像下面的表格, 就生成了两个connfd , 它们俩服务器端的ip和port都是想同的, 但是客户端的IP和Port是不同的, 自然就可以区分开来了”
 张大胖说:“唉, 这底层做了这么多工作啊, 看来socket 必须得通过
(客户端IP, 客户端Port, 服务器端IP, 服务器端Port) 来确定”
张大胖说:“唉, 这底层做了这么多工作啊, 看来socket 必须得通过
(客户端IP, 客户端Port, 服务器端IP, 服务器端Port) 来确定”
“其实这个四元组还不太准确, 因为咱们说了半天,都是TCP协议的socket, 因为你们领导只要你实现这一个, 你看过UDP没有? 就是那个无连接的运输层协议, 也有socket, 所以更准确的定义的话,还得加上协议这一项, 变成五元组 (协议, 客户端IP, 客户端Port, 服务器端IP, 服务器端Port) ”
“大神,咱们什么时候讲讲UDP的socket ? ”
"下次再说吧!"
题外话: 文中提到的Bill 是向 Bill Joy致敬, 这是一个天才程序员,主要工作包括BSD Unix操作系统, 实现TCP/IP协议栈, vi 编辑器,c shell , NFC, SPARC处理器,jini等。
当年DARPA(美国国防部先进研究项目局)和一个叫做BBN的公司签署了一个合同,要把TCP/IP协议加入到Berkeley Unix当中, 当研究生Bill Joy 看到BBN写的TCP/IP实现时, 觉得非常差劲,拒绝把它加入内核, 后来干脆卷起袖子自己实现了一个高性能的TCP/IP栈, 这个协议栈至今是互联网的基石。
别人问他是怎么实现这么复杂的软件的, 这位大神说: “很简单啊, 你只需要看看协议, 然后把代码写出来就行了”
两个程序的爱情故事(进程通信)
好感
在这个忙碌的城市里, 我虽然没和她见过面, 但我们已经聊过很多次了。
与其说是聊天,倒不如说是通信, 每次我想给她说话时, 我就把消息放到一块共享内存里边, 然后就离开运行车间, 让她或者别人去使用CPU。 等我再次进来的时候,她回复的消息就已经在那个共享内存中了。
有无数次,我离开的时候都想偷偷的看一眼, 希望接下来运行的是她,可是这个城市严格的规则让我的希望只是奢望。
操作系统把我们这些进程严格的隔离, 他通过虚拟内存的机制,让每个进程都有一块虚拟的、独立的地址空间, 从而成功的制造了一个假象 : 让大家以为内存中只有一个程序在运行。
当我在就绪队列中等待的时候,也被严格禁止和别人交谈, 我经常环顾四周,希望能够看到她的身影, 可是这个系统的进程成千上万, 究竟哪个是她?
也许我见过她,但是根本认不出来。
我和她越聊越多, 对她的好感就越深, 有一次我给她发的消息等了100毫秒都没有回复,把我都快急疯了。
她很喜欢听我讲故事,尤其是那个编号为0x3704 的线程,每次她都会说: 唉,那些线程可真可怜。 我就吓唬她说: 有一天我们的机器也会重启的, 到时候估计你也认不出我来了。 她说没事的, 只要我能通过共享内存给你发消息,我就知道你就在这个城市里。
(码农翻身注: 0x3704的故事在《我是一个线程》里)
分离
这样的日子过了一天又一天, 我想见到她的愿望越来越迫切了。
我悄悄给了CPU很多好处, 希望CPU能描述下她的样子,方便我去找她, 可是CPU运算速度太快, 阅人无数,但就是没有记忆力。
CPU说: 你还是去问操作系统老大吧, 看看你喜欢的女孩到底什么样。
问操作系统? 还是算了吧, 互相隔离是我们城市的铁规, 弄不好他会把我kill掉。
圣诞节前的平安夜, 我打算正式向她表白, 像往常一样 , 我从共享内存里收到了她的信, 急切的拆开信封, 看到了里边的第一句话: 我要走了,以后不能和你通信了......
刹那间,我第一次感觉到了什么叫做五雷轰顶,灵魂出鞘, 我脑子一片空白, 张大了嘴巴呆呆站在那里, 时间长达20毫秒。
CPU看到了我的异常, 因为这么长时间的指令都是NOP, 什么都不做, 这是非常罕见的。
CPU好心的提醒我: 嗨,老兄,你怎么了? 你的时间片快用完了啊!
我的灵魂慢慢归位,意识到信还没有读完, 赶紧接着往下看: “ 我马上要搬到另外一个城市去了,你要想找我的话,切记下面的IP地址和端口号,用socket和我通信”
我明白了,到另外一个城市那就意味者要搬离我们现在的电脑了, 也许是这个城市太拥挤, CPU/内存/硬盘已经不堪重负, 有一批程序需要被搬离到另外一个电脑中。
虽然我和她一直没机会见面, 但我知道我们就住在一个城市, 有时候也许只是擦肩而过, 她就在我的身边, 这好歹给我一点点安慰。
现在,连这一点点的安慰都没有了, 对了,她说的这个socket 是什么东西。
CPU说: “那是网络编程, 你看人家对你还是有情意的, 临走了还给你留下联系方式, 快去学学怎么用Socket吧”
当晚我就失眠了,半夜爬起来翻看一页页和她的通信记录 (很庆幸我把通信记录都保存到了文件中),脑海里回想着这么多天以来幸福的日子,一直到天亮。
网络
为了早日和她联系, 我奋发图强学习网络编程, 理解TCP/IP, 把我自己逐渐的加上对Socket的支持。
一个CPU月以后, 我这个程序终于完成了从共享内存到Socket的改造,激动人心的时刻到来了。
作为一个客户端, 我颤抖着双手向她发起了Socket请求, TCP携带着数据包慢吞吞的走向她所在的城市, 等了好久TCP才完成了三次握手, 这网络可是真慢啊。
我赶紧发送第一个消息: 你好,好久不“见”。
等了足足有1000毫秒, 对我来说仿佛是一个世纪, 才收到让我激动无比的回信 : “啊, 你终于来了 。我在这里等了你好久了,你怎么现在才联系我 ?”
我不好意思的说: “我很笨, 学习socket 太慢了”
又过了一个世纪,我才收到回复, 这网络真是慢的令人抓狂啊。
不管如何, 终于和她联系上了, 这让我开心无比。
原来我们一天能通信上千次, 现在可好, 有10次就不错了, 再也不能像原来那样痛快的讲故事了, 既来之则安之, 反正网络很慢, 现在每次我都会写一封巨长无比的信, 把我的思念之情全部倾诉在其中, 漫长的等待以后再去读她的长长的回复。
原来我们通过内存来中转消息的时候, 是通过操作系统来做同步操作的, 这能防止读写的冲突。
可是通过网络通信就完全乱掉了, 经常会出现我说我的, 她说她的, 闹的很不愉快。
后来我和她只好协商了一个协议, 约定好消息的次序和格式, 这才算解决了问题。
(码农翻身注: 这其实就是基于socket的应用层协议)
Web
我明白我和她已经不可能在一起了, 每天的socket通信已经让我满足。
可是有一天当我照例发起socket的请求的时候, TCP的连接竟然告诉我 "超时" 了, 这是从来没有发生的事情,难道这一次要彻底失去她了吗?
我冒着风险,马上把异常报给了操作系统老大, 老大尝试了一下说: “我ping了一下, 网络是通的, 估计是你那从未见面的小女朋友不想理你了, 悄悄的换了一个你不知道的端口吧。”
我斩钉截铁的说: 那绝对不可能, 她不是这样的人。
可是迟迟没有消息, 我每天都会试图连接一下, 每次都是超时, 没有她的日子生活都是灰色的, 不断的煎熬让我快要绝望了。
终于有一天, 有一个U盘从她的城市来到我们这里, 告诉了我们一个惊人的消息,她所在的城市安装了防火墙,现在除了几个特定的端口(例如80,443...) 之外, 都不允许访问了。
我一下子松了口气, 怪不得, 她告诉我的端口不是80和443, 被封掉了, 我自然连接不上了。
我问U盘: “那我想和女朋友通信, 该怎么办?”
U盘说: 很简单啊, 你和你女朋友都可以包装成Web 服务啊, 这样都是通过Http(80端口)或者Https(443端口)来访问的, 这样防火墙是允许的啊。
好吧, 为了和她联系上, 马上抛弃socket, 开始向Web服务进化。
一个Web服务首先要有一个endpoint , 其实就是就是一个URL , 描述了这个Web服务的地址。
其次确定Web服务的描述方式和数据传输方式, 我先是选了WSDL 和 SOAP , 研究了一下才发现这哥俩太繁琐了,都是XML, 很多冗余的数据标签, 我想这将会极大的影响我和她的通信效率, 还是换成简单的HTTP GET/POST + JSON吧, 很简洁,能充分的表达我的相思之情。
我把我这个Web服务的地址和格式协议告诉U盘, 恳请U盘带到那个城市,再把女朋友的Web服务描述带回来。
我欣喜的发现,我和她不约而同的选择了轻量级的HTTP+ JSON, 看来虽然隔着千山万水,我们的心意还是相通的。
这样的准备工作足足干了6个CPU月, 但我并不觉得累, 因为希望一直在前边召唤。
这是一个晴朗的日子,一切工作准备就绪,马上就要联系了, 这一次我的心情反而平静了下来, 因为我坚信她肯定在那边等着我。
我通过HTTP向她发出了呼叫, HTTP的报文被打包在TCP报文段中, 又被放到IP层数据报中, 最后形成链路层的帧, 通过网卡发了出去。
在意料之中的漫长等待以后, 我看到了期待已久地回复: 我们终于又“见”面了 !
我回答:“是啊, 真是太不容易了”
“不知道将来我们会不会再分开?” 她担忧的说。
“未来会如何? 我也不知道,还是牢牢地把握住现在吧! 我相信我们的心会一直在一起,什么都无法阻止! ”
(完)
两个程序的爱情故事(续)
我这个进程和她不在一个机器上, 虽然相距243毫秒,但是这并不是阻碍我们交往的理由, 我每天都通过socket 和她来通信,诉说相思之情。
不要惊讶我用时间来表示距离,人类好像也是用光年来表示宇宙间的距离吧? 在我们计算机世界, 距离不是有意义的标识,时间才是! 你看我和纽约相距1万多公里, 我和那里的机器沟通只需要花费466毫秒, 但是和北京的另外一个机器沟通竟然需要743毫秒! 可见距离近是不管用的!
最近黑客猖獗, 我和她通信的时候总是有一种被偷看的感觉, 实际上确实是这样, 那些只有我们才可以知道的悄悄话被别人偷窥,甚至曝光了。
我和她商量着要保护隐私,要对我们来往的信件加密, 可我听说加密需要密钥, 这个密钥必须双方都得事先知道才行, 我用密钥加密,她用同样的密钥解密。

那问题就来了: 加密解密算法是公开的, 但是密钥是私有的,当我们俩通过网络协商密钥时, 黑客可能就把密钥也给偷看了, 那加密就毫无用处。
这可真是伤脑筋, 我说:“要不我到你那儿去一趟? 正好看看你, 你可以面对面的把密钥告诉我。”
她说: “你晕头了吧, 你一个进程怎么可能从一个机器来到另外一个机器?”
我自知失言,马上补救: “ 这样吧, 我们机器上有个U盘, 要不我把密钥写到那里, 这样将来可以Copy到你的机器上”
“那更不行了, Copy到U盘上更容易泄露,速度还慢! ”
我是没辙了,长时间的沉默。
她突然说:“我想起来了,我们机器有个进行数学计算的进程,知识渊博,我去问问他”
我焦急地等待,不知过了多少毫秒, 女朋友终于兴冲冲的回来了: “那个数学进程小帅哥真是厉害,我简直佩服死了, 他告诉我了一个非常简单的办法 , 能解决我们的密钥生成问题”
我心里略微不爽,但还是耐着性子,一边听她说,一边写了下来,这个算法确实很简单, 举个例子来说是这样的:
1. 首先我和她先协定一个质数 p=17以及另外一个数字g=3, 这两个数字是公开的, 黑客拿去也没有问题
2. 我选择一个随机的秘密数字x = 15, 计算a = g15 mod p并发送给她。
a = 315 mod 17 = 6.
这个a=6也是公开的
3. 她选择一个随机的秘密数字y=13, 计算b = g13 mod p并发送给我。
b = 313 mod 17 = 12.
这个b=12也是公开的
4. 我拿到她发给我的b = 12 , 计算s = b x mod p ->1215 mod 17 = 10
5. 她拿到我发给她的a = 6, 计算s = a y mod p -> 613 mod 17 = 10
(注:例子来源于wikipedia, 红色表示数字一定要保密, 绿色表示数字可以公开)
最后神奇的魔法发生了, 我们两个得到了同样的值 s = 10!
这个s 的值只有我们两个才知道, 其实就是密钥了, 可以用来做加密解密了( 当然,这只是一个例子,实际的密钥不会这么短), 我们俩的通讯从此就安全了。
“可是为什么会这样呢” 我问道。
“数学家小帅哥说了, 原因很简单,(gx mod p)y mod p 和 (gy mod p)x mod p 是相等的! ”
“那黑客不能从公开传输的 p = 17, g = 3, a = 6 , b = 12 推算出s = 10 吗?” 我问道。
“当然不能, 不过前提是需要使用非常大的p , x, y, 这样以来,即使黑客动用地球上所有的计算资源, 也推算不出来。 ”
我虽然心里不爽, 但还是暗自佩服那个数学家, 他竟然能想到把一些数字给公布出去,不怕黑客窃取, 还不泄露最终的密钥。解决了在一个不安全的通信环境下,生成密钥进行加密和解密的问题。
好吧,就用这个方法来加密通信吧。
后记:文中描述的算法叫做Diffie-Hellman Key Exchange算法, 发明人是 Whitfield Diffie 和 Martin Hellman ,他们于2015年获得了计算机科学领域的最高奖:图灵奖,以表彰他们对密码学和当今互联网安全的巨大贡献。因为他们的创造,引发了对一个新的密码学领域,即非对称密钥算法的探索,而非对称密钥算法可以看作现代密码学的基础。
推荐阅读:《两个程序的爱情故事》
Http 历险记(上)
从浏览器村出发的时候, 老IE就告诉过我, 找到这个大厦, 走安全通道进去, 自然有人接待。
(码农翻身注: 关于老IE 参见《 IE为什么把Chrome和火狐打伤了》)
哪个是安全通道? 我看到这两个通道都有很多人进进出出,有点犯嘀咕了, 正琢磨着呢, 里边出来一个保安, 用很鄙视的语气对我说:"还愣着干嘛, 还不赶紧进443通道""为啥啊?""你没看运你来的车吗? 上面写着HTTPS :443 端口"
奥,我确实是没有注意到, 赶紧进去吧。
进入443通道, 果然如老IE所说, 里边马上就迎过来一个人, 穿着服务员的衣服, 很热情的说:"我是4号长工, 很高兴为您服务""长工? 你们这儿还是封建社会啊?""是啊, 我们这儿还有地主呢,时不时给我们4个长工发号施令,对我们压榨的很厉害啊, 你看前面这么多人,这么多活, 就我们4个长工干"
我往前一看, 可不是, 前面的大厅熙熙攘攘, 但是穿服务员衣服的,我只看到4个人 。
"我和你们老IE的连接很早就建立了, 你怎么才来啊“ 4号长工问我。
"唉, 这一路实在是太远了, 先是坐着驴车从浏览器村出发, 然后坐汽车, 然后坐飞机, 中间还在几个路由器中转了好几次, 这才来到这里。 "
4号长工有个办公桌, 已经围了不少人, 七嘴八舌的问他:"我的那个图片取出来没有, 我都等了半边了”"我的javascript文件呢?""我的css的呢?""我的html呢?"
要是我估计头都炸了, 但是4号长工见怪不怪, 淡定的统一回复:"对不起, 再等等吧, 数据取出来了会通知我的"。
听到这句话, 我的脑子立刻亮了, 我看过《 Node.js 我只需要一个店小二》, 看来这些长工们干活的方式和Node.js一样啊, 一人应付所有客户, 都是事件驱动, 怪不得他们4个长工能服务这么多人。
4号长工对我说: "把你的保险柜给我, 我和你们老IE 建立连接的时候已经确定钥匙了, 我打开才能看其中的包裹"
(码农翻身注:保险柜和钥匙指的是加密通信, 即HTTPS, 参见《 对浏览器村的第二次采访》)
我把保险柜放到地上, 他掏出钥匙,顺利的打开了 , 里边的包裹上写着: HTTP POST login.action
"奥, 你这个包裹请求的东西我们这里处理不了, 需要你到Tomcat大厦去"
"为啥啊?"
"我们Nginx只负责静态文件比如图片,javascript, html文件等, 你这里请求的是动态页面, login.action , 由后面的Tomcat 执行应用程序才能搞定"
"Tomcat在哪儿? " 我问道"我们这儿有4个Tomcat,你等等啊, 我看看哪个Tomcat大厦人少一点 , 恩, 你去 192.168.0.102 这个Tomcat吧, 走8080通道"
我心里想着是不是还要坐驴车去, 那样就太痛苦了。
4号长工可能看出来了我的心思, 把我到了一个管道前, 对我说: “跳进去就行了,很快就到”
周围的人都幸灾乐祸的看着我, 似乎我此行一去不复返了。
我咬咬牙,跳了进去。
第二章 Tomcat这只是连接两个大厦的滑道而已, 我舒舒服服的从Nginx大厦滑到了Tomcat大厦的一个大厅里。
落地一看, 这里的人也真不少啊, 但是和Nginx大厦有个显著的不同:
那里是4个长工被所有人“围攻", 吵吵嚷嚷的, 这里每个人都有一个穿着黄色制服的服务员进行1对1贴心服务, 安静多了 。
只听见大喇叭响了: "0x6904 ,客人来了,快来招呼下"
一个小个子从旁边的屋子里跑出来, 也是黄色制服, 胸前的工牌上写着几个大字: 线程0x6904
"May I help you , sir ? " 这家伙还是个假洋鬼子, 我一听就来气。"把这个包裹给我处理喽" 我没声好气的说。
0x6904不说话, 只是伸出手来, 大拇指在食指和中指上快速的摩擦着, 很明显,这是要钱。
我更生气了: "你们这儿还收费吗?,人家Ngnix 一个长工服务那么多人都不要钱。"
"Ngnix啊, 我知道, 他们工资高啊, 你别看我们这儿有200人, 也是和Nginx他们一样, 按服务的人头付工资, 但是我们老板规定 ,这儿是1对1 VIP贴心服务, 现在淡季,我一天都不一定能接待几个, 不收点小费怎么活啊 "
我想了想也是, 就给他掏了10块钱。
0x6904这次把包裹接过来, 然后从口袋里掏出一张纸, 慢腾腾的看了半天说:"你要处理 login.action 啊 , 你看,我们的web.xml 上写的很清楚,你的包裹由Struts 的filter 老大负责处理“
所有的.action 请求都得找Struts Filter 老大, 我的包裹也不例外。
Filter老大的房间很气派, 尤其是墙上,密密麻麻的贴着各种表格, 箭头。 0x6904 走上前去询问, 我就站在那里看墙上那个struts.xml 。
我发现上面写着 login -->LoginAction.java , 难不成还得去找 LoginAction.java?
"老大, 您帮忙看看这个包裹吧" 0x6904 问道。
Filter老大忙的要死, 只是瞥了一眼, 头都不抬: " 到二楼去找LoginAction "
果然是这样! 我估计他已经处理过无数这样的包裹了, 因为墙上的图标什么的都有些泛黄, 有些时日了, 他肯定把这些东西都背下来(缓存下来)了, 所以根本不用查。
(未完待续)
Http历险记(下)-- Struts的秘密

0x6904说: "奥,我刚刚在线程池里睡觉, 刚起床,犯傻了, 我们想见LoginAction, 得经过特定的ActionProxy通道, 你等等,我去问问Filter老大,我们具体到哪个通道去。 "
(码农翻身注: 关于线程池参见《 我是一个线程》)
我在那儿无聊的等0x6904, 饶有兴趣的看着大家都是从通道的这头进去, 从另外一头出来。 有的快,有的慢。
有个贼头贼脑的家伙刚从一个通道出来, 突然凄厉的警报大声想起来: 注意, 有javascript 攻击。
一群卫兵跑过来把他给按住了, 带头的领导打开这个家伙的包裹, 仔细的检查里边的数据:
"报告Filter老大, 这个返回包裹里要把用户输入的数据送回浏览器, 但是这个用户输入的数据包含
"按规定消毒吧, 把这些‘<’ '>' 字符做转义操作, 这样发送到浏览器就只是显示,而不会执行了"
(码农翻身注: 转义指的是吧 < , > , & 等字符转成 < > & 这样的转义字符)
怪不得Filter老大这么忙, 这么细的事情都管啊。
这时候0x6904气喘吁吁的回来了: "快, 走0xa84d通道"
我说: "刚才那个警报是咋回事, 为什么要把
"这么说吧, 这些javascript 的脚本不是我们系统产生的, 可能是黑客精心构造的, 通过参数发送到我们这里, 如果我们不消毒, 直接发到用户的浏览器,这些javascript 就有可能在浏览器执行,会把用户的cookie (里边有session id ) 偷走, 然后黑客就可以假装成用户来干坏事了, 例如:把你的钱转走! "
我心里暗暗吃惊: "这么厉害啊"
"是啊, 很多网站如果不对用户的输入和输出消毒, 就可能出乱子, 这种黑客攻击叫做 XSS, 跨站点脚本攻击"第四章 拦截器沿着0xa84d通道摆放着一列柜台, 前面几个柜台上写着"拦截器",都坐着人, 中间一个柜台上写着LoginAction, 那就是我们的目的地了。
后面几个柜台上也写着“拦截器”,但没有人在那里。这到底是要干嘛呢?
我和0x6904来到第一个柜台, 他对我们说:"我是Exception 拦截器, 不过现在没啥事儿, 等会儿见"
我心里犯嘀咕:没事你一本正经的待在这儿干嘛? 第二个柜台的拦截器对我们说:
"我是I18n 拦截器, 你们从哪里来啊"
"中国北京中关村软件园", 我说
"不用那么详细, 我就记个国家和语言, 你们用zh_CN吧, 等会儿见"
第三个柜台是FileUpload 拦截器, 他看了一眼就放行了, 我这儿实在是没有任何文件上传的东西。
到了第四个柜台, 有个家伙笑着对我说:"我是Parameter 拦截器, 打劫了,把你包裹里的参数全给我 "
我心想: 我靠, 又要要钱了。
但0x6904见怪不怪: "我们这儿有 user.name 和user.password , 拿去吧”
Parameter 拦截器说 : "好的, 我会把他们放到ValueStack中, LoginAction 会用到, 等会儿见,伙计们。"
怎么都是等会儿见?
下一个柜台是Validation 拦截器。
我有些不满: "我从老IE那里出发的时候, 那里的javascript 已经验证过了,这些数据绝对没有问题"
Validation拦截器毫不示弱的教训我: "年轻人呐,javascript 验证算啥啊, 这种基于浏览器的检查很容易被绕过, 没听见刚才的警报吗,黑客不用浏览器轻轻轻松就能搞个HTTP POST,把数据发到我们这里。"
我赶紧禁声。
检查很快, 他很快就放行了: “我们这也是为了大家安全, 好了, 通过了, 等会儿见。”

(点开图片,放大看, 很多细节噢)
经过了5个拦截器, 我们终于来到了LoginAction的跟前。
他这里有个User对象, 有个setName() 和setPassword() 的方法, 很明显, 值是从我的包裹中来的。
LoginAction 干活一丝不苟: 给LoginService 打电话, 让他执行登录方法,查查数据库, 看看这个用户名和密码对不对, 最后告诉我:
"登录成功, 记住这个返回码 success ,下一个柜台会用。 还有,这是你的session id, 记着回去一定要交给老IE让他好生保管"
我问0x6904 : "我的包裹里好像有个session id 啊, 为什么又给我一个?"
"这也是安全起见, 登录成功以后, 一定要生产新的session id , 把老的session id 给废除掉, 你结合XSS攻击,想想为什么要这么做“
我想了想: XSS攻击主要就是偷用户的session , 如果有个黑客在登录之前的页面上构造了一个XSS攻击,如果有人浏览到这个界面,虽然没有登录, session id 也被偷走了。 然后黑客不停的尝试这些偷来的session id, 访问那些登录后才能访问的页面。 如果session id 对应的用户登录了网站, 那么黑客也可以登录了 - 因为session id 没有变。
我说:没想到这网络世界这么可怕, 幸亏你们这里防卫森严啊。
接下来的柜台果然问我们要那个返回码"success",然后从struts.xml这张纸上找到 LoginAction的配置, 从中找到了对应的jsp : /WEB-INF/home.jsp , 生成html 交给了我。
后面的柜台就让我大跌眼镜了, 这些人不都是刚刚见过的吗, 怪不得他们都说等会儿见。
只是次序和刚才不同: 先是Validation, 然后是Parameter, FileUpload, I18n , Exception , 和刚才进来的时候完全倒过来了!

(点开图片,放大看, 很多细节噢)
我有点明白了, 这些家伙们只是都是在LoginAction执行之前拦截我们一下, 在LoginAction 之后再拦截我们一下。
Validation,Parameter ,FileUpload, I18n 只是对我们笑了笑就放行了, 我们已经执行完了, 他们确实没啥可拦截的。
又到了Exception 拦截器, 他问我们: "有什么异常吗?"
我想了想, 整个过程确实没有异常: “一切顺利”
Exception拦截器说: "好,那我也不用再做什么事儿了, 你们可以离开这个通道了"
(码农翻身注: 实际的Struts 拦截器比这里列的要更多)
终于走了出来 , 我感慨的对0x6904说: "这个ActionProxy通道可是真麻烦啊"。
0x6904说: "其实这个通道设计的挺精致的, 你看只要走一遍, 像参数处理, 表单验证,国际化等事情都搞定了。 "
我问他: "每个Action 都有这么多拦截器吗?"
"不一定, 这是可以定制的,每个Action都可以不同 "
"那我们走了, 这个通道还会让别的人用吗"
"绝对不会, 一人一个, 用过就销毁, 垃圾回收了"
我虽然有些吃惊, 但仔细想想 ,很正常, 这个通道其实保存了我的信息 , 别人确实不能用啊。第四五 尾声正和0x6904说着, 大喇叭又响了: "0x6904,你在那儿磨叽啥, 顾客都排大队了,人手不够, 快点回来"
0x6904神色立刻就紧张了, 指着一个通道对我说: "从这里可以回到Nginx 大厦,我得赶紧接待别人去了, 再见"
回到Nginx大厦, 和Tomcat相比,这里就是另外一个世界, 人声鼎沸,04号长工还是一如既往的忙。 看到我回来, 他就说: "怎么样,Tomcat那里感觉如何? "
我感慨的说:"那里比你这里复杂多了"
04号长工帮忙把返回的包裹装进了小保险柜, 告诉我说: "好了, 我这儿的事情也处理完了,一会儿你就可以坐车回老IE那里去了"
是啊, 我出来这么长时间,确实有点想老IE了。
漫长的旅途又要开始, 带着保险柜, 跨越千山万水, 乘坐各种交通工具, 虽然累但也挺有趣, 下次再讲吧。(全文完)
特别感谢: 网友blindingdark 提供的形神具备的配图, 这可是先在纸上手绘, 然后扫描变成图片编辑,很不容易啊 :-)
Http Server : 一个差生的逆袭
我刚毕业那会儿,国家还是包分配工作的, 我的死党小明被分配到了一个叫数据库的大城市,天天都可以坐在高端大气上档次的机房里, 在那里专门执行SQL查询优化 , 工作稳定又舒适;
隔壁宿舍的小白被送到了编译器镇,在那里专门把C源文件编译成EXE程序, 虽然累,但是技术含量非常高, 工资高,假期多。
我成绩不太好,典型的差生,四级补考了两次才过, 被发配到了一个不知道什么名字的村庄,据说要处理什么HTTP请求, 这个村庄其实就是一个破旧的电脑, 令我欣慰的是可以上网,时不时能和死党们通个信什么的。
不过辅导员说了, 我们都有光明的前途。
1
Http Server 1.0
HTTP是个新鲜的事物, 能够激起我一点点工作的兴趣, 不至于沉沦下去。
一上班,操作系统老大扔给我一大堆文档: “这是HTTP协议, 两天看完!”
我这样的英文水平, 这几十页的英文HTTP协议我不吃不喝不睡两天也看不完, 死猪不怕开水烫,慢慢磨吧。
两个星期以后, 我终于大概明白了这HTTP是怎么回事: 无非是有些电脑上的浏览器向我这个破电脑发送一个预先定义好的文本(Http request), 然后我这边处理一下(通常是从硬盘上取一个后缀名是html的文件), 然后再把这个文件通过文本方式发回去(http response), 就这么简单。
唯一麻烦的实现, 我得请操作系统给我建立Http层下面的TCP连接通道, 因为所有的文本数据都得通过这些TCP通道接收和发送, 这个通道是用socket建立的。
弄明白了原理,我很快就搞出了第一版程序, 这个程序长这个样子:

(码农翻身注: 详情参加文章《张大胖的socket》)
看看, 这些socket, bind, listen , accept... 都是操作系统老大提供的接口, 我能做的也就是把他们组装起来: 先在80端口监听, 然后进入无限循环,如果有连接请求来了,就接受(accept),创建新的socket, 最后才可以通过这个socket来接收,发送http数据。
老大给我的程序起了个名称, Http Server, 版本1.0 。
这个名字听起来挺高端的, 我喜欢。
我兴冲冲的拿来实验, 程序启动了, 在80端口“蹲守”, 过了一会儿就有连接请求了, 赶紧Accept ,建立新的socket, 成功 ! 接下来就需要从socket 中读取Http Request了。
可是这个receive 调用好慢, 我足足等了100毫秒还没有响应 ! 我被阻塞(block)住了!
操作系统老大说: “别急啊, 我也在等着从网卡那里读数据,读完以后就会复制给你。 ”
我乐的清闲, 可以休息一下。
可是操作系统老大说:“别介啊, 后边还有很多浏览器要发起连接, 你不能在这儿歇着啊。”
我说不歇着怎么办? receive调用在你这里阻塞着, 我除了加入阻塞队列, 让出CPU让别人用还能干什么?
老大说: “唉, 大学里没听说过多进程吗? 你现在很明显是单进程, 一旦阻塞就完蛋了, 想办法用下多进程, 每个进程处理一个请求! ”
老大教训的是, 我忘了多进程并发编程了。
2
Http 2.0 :多进程
多进程的思路非常简单,当accept连接以后,对于这个新的socket , 不在主进程里处理, 而是新创建子进程来接管。 这样主进程就不会阻塞在receive 上, 可以继续接受新的连接了。

我改写了代码, 把Http server 升级为V2.0, 这次运行顺畅了很多, 能并发的处理很多连接了。
这个时候Web 刚刚兴起, 我这个Http Server 访问的人还不多, 每分钟也就那么几十个连接发过来,我轻松应对。
由于是新鲜事物, 我还有资本给搞数据库的小明和做编译的小白吹吹牛, 告诉他们我可是网络高手。
没过几年, Web迅速发展, 我所在的破旧机器也不行了, 换成了一个性能强悍的服务器, 也搬到了四季如春的机房里。
现在每秒中都有上百个连接请求了, 有些连接持续的时间还相当的长,所以我经常得创建成百上千的进程来处理他们,每个进程都得耗费大量的系统资源, 很明显操作系统老大已经不堪重负了。
他说: “咱们不能这么干了, 这么多进程,光是做进程切换就把我累死了。”
“要不对每个Socket连接我不用进程了, 使用线程? ”
“可能好一点, 但我还是得切换线程啊, 你想想办法限制一下数量吧。”
我怎么限制? 我只能说同一时刻,我只能支持x个连接, 其他的连接只能排队等待了。
这肯定不是一个好的办法。
3
Http Server 3.0 : Select模型
老大说: “我们仔细合计合计, 对我来说,一个Socket连接就是一个所谓的文件描述符(File Descriptor ,简称 fd , 是个整数) , 这个fd 背后是一个简单的数据结构, 但是我们用了一个非常重量级的东西-- 进程 --来表示对它的读写操作, 有点浪费啊。”
我说: “要不咱们还切换回单进程模型? 但是又会回到老路上去, 一个receive 的阻塞就什么事都干不了了”
“单进程也不是不可以, 但是我们要改变一下工作方式。”
“改成什么?” 我想不透老大在卖什么关子。
“你想想你阻塞的本质原因, 还不是因为人家浏览器还没有把数据发过来, 我自然也没法给你, 而你又迫不及待的想去读, 我只好把你阻塞。 在单进程情况下, 一阻塞,别的事儿都干不了。“
“对,就是这样”
“所以你接受了客户端连接以后, 不能那么着急的去读, 咱们这么办, 你的每个socket fd 都有编号, 你把这些编号告诉我, 就可以阻塞休息了 ”
我问道:“这不和以前一样吗? 原来是调用receive 时阻塞, 现在还是阻塞”
“听我说完, 我会在后台检查这些编号的socket, 如果发现这些socket 可以读写, 我会把对应的socket 做个标记, 把你唤醒去处理这些socket 的数据, 你处理完了,再把你的那些socket fd 告诉我, 再次进入阻塞,如此循环往复。”
我有点明白了: “ 这是我们俩的一种通信方式, 我告诉你我要等待什么东西, 然后阻塞, 如果事件发生了, 你就把我唤醒, 让我做事情。”

“对, 关键点是你等我的通知, 我把你从阻塞状态唤醒后, 你一定要去遍历一遍所有的socket fd,看看谁有标记, 有标记的做相应处理。 我把这种方式叫做 select ”
我用select的方式改写了Http server, 抛弃了一个socket请求对于一个进程的模式, 现在我用一个进程就可以处理所有的socket了。
4
Http Server4.0 : epoll
这种称为select的方式运行了一段时间, 效果还不错, 我只管把socket fd 告诉老大, 然后等着他通知我就行了。
有一次我无意中问老大:“我每次最多可以告诉你多少个socket fd?”
“1024个”
“那就是说我一个进程最多只能监控1024个socket了? ”
"是的, 你可以考虑多用几个进程啊"
这倒是一个办法, 不过"select"的方式用的多了, 我就发现了弊端, 最大的问题就是我从阻塞中恢复以后,需要遍历这1000多个socket fd, 看看有没有标志位需要处理。
实际的情况是, 很多socket 并不活跃, 在一段时间内浏览器并没有数据发过来, 这1000多个socket 可能只有那么几十个需要真正的处理, 但是我不得不查看所有的socket fd, 这挺烦人的。
难道老大不能把那些发生了变化的socket 告诉我吗?
我把这个想法给老大说了下, 他说:“嗯, 现在访问量越来越大, select 方式已经不满足要求, 我们需要与时俱进了, 我想了一个新的方式,叫做epoll”

“看到没有, 使用epoll和select 其实类似“ 老大接着说 : ” 不同的地方是第3步和第4步, 我只会告诉你那些可以读写的socket , 你呢只需要处理这些'ready' 的socket 就可以了“
“看来老大想的很周全, 这种方式对我来说就简单的多了。 ”
我用epoll 把Http Server 再次升级, 由于不需要遍历全部集合, 只需要处理哪些有变化的, 活跃的socket 文件描述符, 系统的处理能力有了飞跃的提升。
我的Http Server 受到了广泛的欢迎, 全世界有无数人在使用, 最后死党数据库小明也知道了, 他问我:“ 大家都说你能轻松的支持好几万的并发连接, 真是这样吗? ”
我谦虚的说: “过奖, 其实还得做系统的优化啦。”
他说:“厉害啊,你小子走了狗屎运了啊。”
我回答: “毕业那会儿辅导员不是说过吗, 每个人都有光明的前途。”
(完)
小白科普:从输入网址到最后浏览器呈现页面内容,中间发生了什么?(HTTP请求)
1前言
这篇文章是应网友之邀所写,主要描述一下我们访问网站时, 从输入网址到最后浏览器呈现内容,中间发生了什么。
之前写过两篇文章《我是一个网卡》,《我是一个路由器》描述了一个电脑如何通过DHCP、ARP、NAT等上式获取IP、然后访问网络的过程,主要专注在传输层和网络层。
今天的文章主要专注于应用层,我拿了一个很简单的网络结构来讲。假定本机已经获取了IP地址,各种网络基础设施已经准备好了。
由于知识点太多,我肯定会漏掉部分内容,欢迎在留言中补充, 以后我会根据大家建议再写文章扩展。
2准备
当你在浏览器中输入网址(例如www.coder.com)并且敲了回车以后, 浏览器首先要做的事情就是获得coder.com的IP地址,具体的做法就是发送一个UDP的包给DNS服务器,DNS服务器会返回coder.com的IP, 这时候浏览器通常会把IP地址给缓存起来,这样下次访问就会加快。
比如Chrome, 你可以通过chrome://net-internals/#dns来查看。
有了服务器的IP, 浏览器就要可以发起HTTP请求了,但是HTTP Request/Response必须在TCP这个“虚拟的连接”上来发送和接收。
想要建立“虚拟的”TCP连接,TCP邮差需要知道4个东西:(本机IP, 本机端口,服务器IP, 服务器端口),现在只知道了本机IP,服务器IP, 两个端口怎么办?
本机端口很简单,操作系统可以给浏览器随机分配一个, 服务器端口更简单,用的是一个“众所周知”的端口,HTTP服务就是80, 我们直接告诉TCP邮差就行。
经过三次握手以后,客户端和服务器端的TCP连接就建立起来了! 终于可以发送HTTP请求了。
之所以把TCP连接画成虚线,是因为这个连接是虚拟的, 详情可参见之前的文章《TCP/IP之大明邮差》,《张大胖的Socket》
3Web服务器
一个HTTP GET请求经过千山万水,历经多个路由器的转发,终于到达服务器端(HTTP数据包可能被下层进行分片传输,略去不表)。
Web服务器需要着手处理了,它有三种方式来处理:
(1) 可以用一个线程来处理所有请求,同一时刻只能处理一个,这种结构易于实现,但是这样会造成严重的性能问题。
(2) 可以为每个请求分配一个进程/线程,但是当连接太多的时候,服务器端的进程/线程会耗费大量内存资源,进程/线程的切换也会让CPU不堪重负。
(3) 复用I/O的方式,很多Web服务器都采用了复用结构,例如通过epoll的方式监视所有的连接,当连接的状态发生变化(如有数据可读), 才用一个进程/线程对那个连接进行处理,处理完以后继续监视,等待下次状态变化。 用这种方式可以用少量的进程/线程应对成千上万的连接请求。
(码农翻身注:详情参见《Http Server:一个差生的逆袭》)
我们使用Nginx这个非常流行的Web服务器来继续下面的故事。
对于HTTP GET请求,Nginx利用epoll的方式给读取了出来, Nginx接下来要判断,这是个静态的请求还是个动态的请求啊?
如果是静态的请求(HTML文件,JavaScript文件,CSS文件,图片等),也许自己就能搞定了(当然依赖于Nginx配置,可能转发到别的缓存服务器去),读取本机硬盘上的相关文件,直接返回。
如果是动态的请求,需要后端服务器(如Tomcat)处理以后才能返回,那就需要向Tomcat转发,如果后端的Tomcat还不止一个,那就需要按照某种策略选取一个。
例如Ngnix支持这么几种:
轮询:按照次序挨个向后端服务器转发
权重:给每个后端服务器指定一个权重,相当于向后端服务器转发的几率。
ip_hash: 根据ip做一个hash操作,然后找个服务器转发,这样的话同一个客户端ip总是会转发到同一个后端服务器。
fair:根据后端服务器的响应时间来分配请求,响应时间段的优先分配。
不管用哪种算法,某个后端服务器最终被选中,然后Nginx需要把HTTP Request转发给后端的Tomcat,并且把Tomcat输出的HttpResponse再转发给浏览器。
由此可见,Nginx在这种场景下,是一个代理人的角色。
5应用服务器
Http Request终于来到了Tomcat,这是一个由Java写的、可以处理Servlet/JSP的容器,我们的代码就运行在这个容器之中。
如同Web服务器一样, Tomcat也可能为每个请求分配一个线程去处理,即通常所说的BIO模式(Blocking I/O 模式)。
也可能使用I/O多路复用技术,仅仅使用若干线程来处理所有请求,即NIO模式。
不管用哪种方式,Http Request 都会被交给某个Servlet处理,这个Servlet又会把Http Request做转换,变成框架所使用的参数格式,然后分发给某个Controller(如果你是在用Spring)或者Action(如果你是在Struts)。
剩下的故事就比较简单了(不,对码农来说,其实是最复杂的部分),就是执行码农经常写的增删改查逻辑,在这个过程中很有可能和缓存、数据库等后端组件打交道,最终返回HTTP Response,由于细节依赖业务逻辑,略去不表。
根据我们的例子,这个HTTP Response应该是一个HTML页面。
6归途
Tomcat很高兴地把Http Response发给了Ngnix 。
Ngnix也很高兴地把Http Response 发给了浏览器。
发完以后TCP连接能关闭吗?
如果使用的是HTTP1.1, 这个连接默认是keep-alive,也就是说不能关闭;
如果是HTTP1.0,要看看之前的HTTP Request Header中有没有Connetion:keep-alive,如果有,那也不能关闭。
7浏览器再次工作
浏览器收到了Http Response,从其中读取了HTML页面,开始准备显示这个页面。
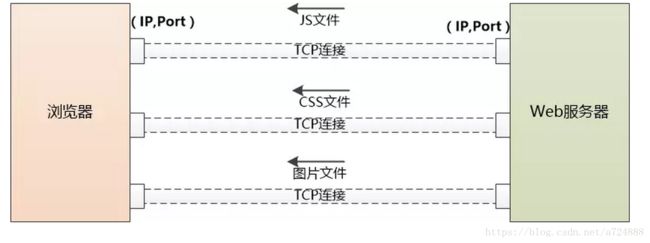
但是这个HTML页面中可能引用了大量其他资源,例如js文件,CSS文件,图片等,这些资源也位于服务器端,并且可能位于另外一个域名下面,例如static.coder.com。
浏览器没有办法,只好一个个地下载,从使用DNS获取IP开始,之前做过的事情还要再来一遍。不同之处在于不会再有应用服务器如Tomcat的介入了。
如果需要下载的外部资源太多,浏览器会创建多个TCP连接,并行地去下载。
但是同一时间对同一域名下的请求数量也不能太多,要不然服务器访问量太大,受不了。所以浏览器要限制一下, 例如Chrome在Http1.1下只能并行地下载6个资源。
当服务器给浏览器发送JS,CSS这些文件时,会告诉浏览器这些文件什么时候过期(使用Cache-Control或者Expire),浏览器可以把文件缓存到本地,当第二次请求同样的文件时,如果不过期,直接从本地取就可以了。
如果过期了,浏览器就可以询问服务器端,文件有没有修改过?(依据是上一次服务器发送的Last-Modified和ETag),如果没有修改过(304 Not Modified),还可以使用缓存。否则的话服务器就会被最新的文件发回到浏览器。
当然如果你按了Ctrl+F5,会强制地发出GET请求,完全无视缓存。
注:在Chrome下,可以通过 chrome://view-http-cache/ 命令来查看缓存。
现在浏览器得到了三个重要的东西:
1.HTML ,浏览器把它变成DOM Tree
2. CSS, 浏览器把它变成CSS Rule Tree
3. JavaScript, 它可以修改DOM Tree
浏览器会通过DOM Tree和CSS Rule Tree生成所谓“Render Tree”,计算每个元素的位置/大小,进行布局,然后调用操作系统的API进行绘制,这是一个非常复杂的过程,略去不表。
到目前为止,我们终于在浏览器中看到了www.coder.com的内容。