CNN模型之SqueezeNet
作者: 叶 虎
编辑:赵一帆
01
引言
SqueezeNet是Han等提出的一种轻量且高效的CNN模型,它参数比AlexNet少50x,但模型性能(accuracy)与AlexNet接近。
在可接受的性能下,小模型相比大模型,具有很多优势:
- 更高效的分布式训练,小模型参数小,网络通信量减少;
- 便于模型更新,模型小,客户端程序容易更新;
- 利于部署在特定硬件如FPGA,因为其内存受限。因此研究小模型是很有现实意义的。
Han等将CNN模型设计的研究总结为四个方面:
- 模型压缩:对pre-trained的模型进行压缩,使其变成小模型,如采用网络剪枝和量化等手段;
- 对单个卷积层进行优化设计,如采用1x1的小卷积核,还有很多采用可分解卷积(factorized convolution)结构或者模块化的结构(blocks, modules);
- 网络架构层面上的优化设计,如网路深度(层数),还有像ResNet那样采用“短路”连接(bypass connection);
- 不同超参数、网络结构,优化器等的组合优化。
SqueezeNet也是从这四个方面来进行设计的,其设计理念可以总结为以下三点:
- 大量使用1x1卷积核替换3x3卷积核,因为参数可以降低9倍;
- 减少3x3卷积核的输入通道数(input channels),因为卷积核参数为:(number of input channels) * (number of filters) * 3 * 3.
- 延迟下采样(downsample),前面的layers可以有更大的特征图,有利于提升模型准确度。目前下采样一般采用strides>1的卷积层或者pool layer。
02
SqueezeNet网络结构
SqueezeNet网络基本单元是采用了模块化的卷积,其称为Fire module。Fire模块主要包含两层卷积操作:一是采用1x1卷积核的squeeze层;二是混合使用1x1和3x3卷积核的expand层。Fire模块的基本结构如图1所示。在squeeze层卷积核数记为s_1x1,在expand层,记1x1卷积核数为e_1x1,而3x3卷积核数为e_3x3。为了尽量降低3x3的输入通道数,这里让s_1x1的值小于e_1x1与e_3x3的和。这算是一个设计上的trick。
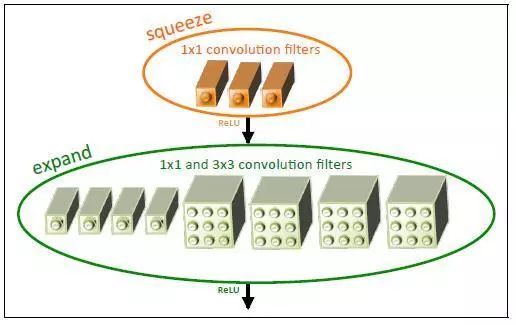
图1 Fire模块的基本结构示意图
整个SqueezeNet就是使用Fire基本模块堆积而成的,网络结构如图2所示,其中左图是标准的SqueezeNet,其开始是一个卷积层,后面是Fire模块的堆积,值得注意的是其中穿插着stride=2的maxpool层,其主要作用是下采样,并且采用延迟的策略,尽量使前面层拥有较大的feature map。中图和右图分别是引入了不同“短路”机制的SqueezeNet,这是借鉴了ResNet的结构。具体每个层采用的参数信息如表1所示。
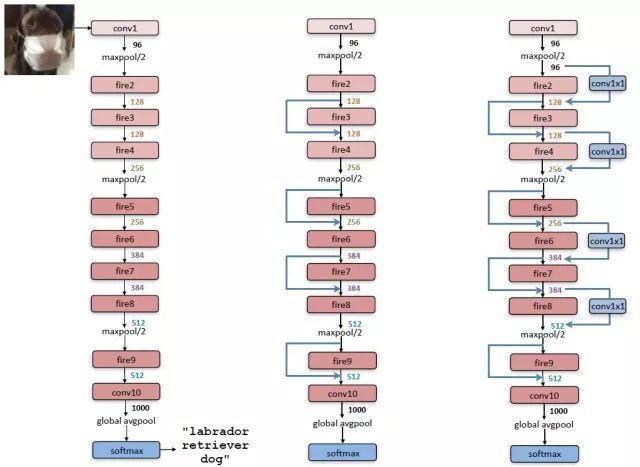
图2 SqueezeNet网络结构

表1 SqueezeNet各层参数信息
下面说一下SqueezeNet的一些具体的实现细节:
- 在Fire模块中,expand层采用了混合卷积核1x1和3x3,其stride均为1,对于1x1卷积核,其输出feature map与原始一样大小,但是由于它要和3x3得到的feature map做concat,所以3x3卷积进行了padding=1的操作,实现的话就设置padding=”same”;
- Fire模块中所有卷积层的激活函数采用ReLU;
- Fire9层后采用了dropout,其中keep_prob=0.5;
- SqueezeNet没有全连接层,而是采用了全局的avgpool层,即pool size与输入feature map大小一致;
- 训练采用线性递减的学习速率,初始学习速率为0.04。
03
SqueezeNet性能
从网络结构来看,SqueezeNet也算是设计精良了,但是最终性能还是要实验说话。论文作者将SqueezeNet与AlexNet在ImageNet上做了对比,值得注意的是,不仅对比了基础模型之间的差异,还对比了模型压缩的性能,其中模型压缩主要采用的技术有SVD,网络剪枝(network pruning)和量化(quantization)等。具体的对比结果如表2所示。
首先看一下基准模型的性能对比,SqueezeNet的Top-1优于AlexNet,Top-5性能一样,但是最重要的模型大小降低了50倍,从240MB->4.8MB,这个提升是非常有价值的,因为这个大小意味着有可能部署在移动端。作者并没有止于此,而是继续进行了模型压缩。其中SVD就是奇异值分解,而所谓的网络剪枝就是在weight中设置一个阈值,低于这个阈值就设为0,从而将weight变成系数矩阵,可以采用比较高效的稀疏存储方式,进而降低模型大小。
值得一提的Deep Compression技术,这个也是Han等提出的深度模型压缩技术,其包括网络剪枝,权重共享以及Huffman编码技术。这里简单说一下权重共享,其实就是对一个weight进行聚类,比如采用k-means分为256类,那么对这个weight只需要存储256个值就可以了,然后可以采用8 bit存储类别索引,其中用到了codebook来实现。关于Deep Compression详细技术可以参加文献[2]。
从表2中可以看到采用6 bit的压缩,SqueezeNet模型大小降到了0.47MB,这已经降低了510倍,而性能还保持不变。为了实现硬件加速,Han等还设计了特定的硬件来高效实现这种压缩后的模型,具体参加文献[3]。
顺便说过题外话就是模型压缩还可以采用量化(quantization),说白了就是对参数降低位数,比如从float32变成int8,这样是有道理,因为训练时采用高位浮点是为了梯度计算,而真正做inference时也许并不需要这么高位的浮点,TensorFlow中是提供了量化工具的,采用更低位的存储不仅降低模型大小,还可以结合特定硬件做inference加速。
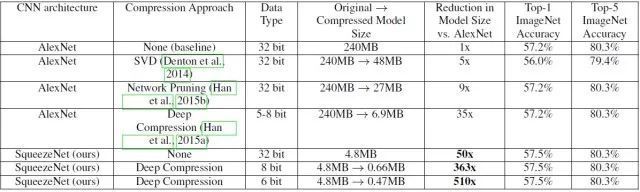
表2 SqueezeNet与AlexNet的对比结果
除了上面的工作,作者还探索了网络的设计空间,包括微观结构和宏观结构,微观结构包括各个卷积层的维度等设置,宏观结构比如引入ResNet的短路连接机制,详细内容可以参考原论文[1]。
04
SqueezeNet的TensorFlow实现
Fire模块中的expand层可以看成两个普通的卷积层,然后做concat,所以SqueezeNet很容易使用TensorFlow实现:
class SqueezeNet(object):
def __init__(self, inputs, nb_classes=1000, is_training=True):
# conv1
net = tf.layers.conv2d(inputs, 96, [7, 7], strides=[2, 2],
padding="SAME", activation=tf.nn.relu,
name="conv1") # maxpool1
net = tf.layers.max_pooling2d(net, [3, 3], strides=[2, 2],
name="maxpool1") # fire2
net = self._fire(net, 16, 64, "fire2") # fire3
net = self._fire(net, 16, 64, "fire3") # fire4
net = self._fire(net, 32, 128, "fire4") # maxpool4
net = tf.layers.max_pooling2d(net, [3, 3], strides=[2, 2],
name="maxpool4") # fire5
net = self._fire(net, 32, 128, "fire5") # fire6
net = self._fire(net, 48, 192, "fire6") # fire7
net = self._fire(net, 48, 192, "fire7") # fire8
net = self._fire(net, 64, 256, "fire8") # maxpool8
net = tf.layers.max_pooling2d(net, [3, 3], strides=[2, 2],
name="maxpool8") # fire9
net = self._fire(net, 64, 256, "fire9") # dropout
net = tf.layers.dropout(net, 0.5, training=is_training) # conv10
net = tf.layers.conv2d(net, 1000, [1, 1], strides=[1, 1],
padding="SAME", activation=tf.nn.relu,
name="conv10") # avgpool10
net = tf.layers.average_pooling2d(net, [13, 13], strides=[1, 1],
name="avgpool10") # squeeze the axis
net = tf.squeeze(net, axis=[1, 2])
self.logits = net
self.prediction = tf.nn.softmax(net) def _fire(self, inputs, squeeze_depth, expand_depth,scope):
with tf.variable_scope(scope):
squeeze =tf.layers.conv2d(inputs, squeeze_depth, [1, 1],
strides=[1, 1], padding="SAME",
activation=tf.nn.relu, name="squeeze") # squeeze
expand_1x1 = tf.layers.conv2d(squeeze, expand_depth, [1, 1],
strides=[1, 1], padding="SAME",
activation=tf.nn.relu, name="expand_1x1")
expand_3x3 =tf.layers.conv2d(squeeze, expand_depth, [3, 3],
strides=[1, 1], padding="SAME",
activation=tf.nn.relu, name="expand_3x3")
return tf.concat([expand_1x1, expand_3x3], axis=3)
05
总结
本文简单介绍了移动端CNN模型SqueezeNet,其核心是采用模块的卷积组合,当然做了一些trick,更重要的其结合深度模型压缩技术,因此SqueezeNet算是结合了小模型的两个研究方向:结构优化和模型压缩。
06
参考资料
- SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size: https://arxiv.org/abs/1602.07360.
- Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding: https://arxiv.org/abs/1510.00149.
- EIE: Efficient inference engine on compressed deep neural network: https://arxiv.org/abs/1602.01528.
原文发布于微信公众号 - 机器学习算法全栈工程师(Jeemy110)
原文发表时间:2018-01-24
本文参与腾讯云自媒体分享计划,欢迎正在阅读的你也加入,一起分享。
发表于 2018-03-06