18Python爬虫---CrawlSpider自动爬取新浪新闻网页标题和链接
一、爬取新浪新闻思路
1、创建scrapy项目
2、分析新浪新闻网站静态页面代码
3、编写对应的xpath公式
4、写代码
二、项目代码
步骤1、创建scrapy项目
scrapy startproject mycwpjt步骤2、分析新浪网站静态代码
随便打开一个新浪新闻网,新闻
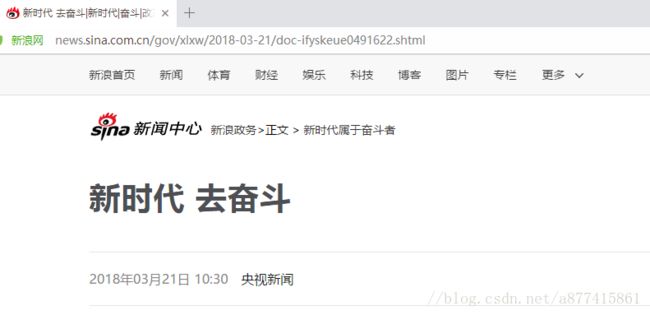
可以看到地址为
http://news.sina.com.cn/gov/xlxw/2018-03-21/doc-ifyskeue0491622.shtml
点开其他新闻也为.shtml结尾
那么我们可以考虑从新浪首页,针对性爬取后缀为.shtml的网页
步骤3、编写对应的xpath公式
在html的页面head中可以看到标题在title中
<title>新时代 去奋斗|新时代|奋斗|改革_新浪新闻title>
当前页面的链接在meta中
<meta property="og:url" content="http://news.sina.com.cn/gov/xlxw/2018-03-21/doc-ifyskeue0491622.shtml">
由此可以写出xpath为
标题:/html/head/title/text()
链接: //meta[@property='og:url']/@content步骤4、编写代码
创建爬虫文件
scrapy genspider -t crawl bangbing sina.com.cn

1、bangbing .py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from mycwpjt.items import MycwpjtItem
class BangbingSpider(CrawlSpider):
name = 'bangbing'
allowed_domains = ['sina.com.cn']
start_urls = ['http://www.sina.com.cn/']
# 只提取链接中有'*.shtml'字符串的链接
rules = (
Rule(LinkExtractor(allow='.*?/n.*?shtml'), callback='parse_item', follow=True),
)
def parse_item(self, response):
i = MycwpjtItem()
i["name"] = response.xpath("/html/head/title/text()").extract()
i["link"] = response.xpath("//meta[@property='og:url']/@content").extract()
return i
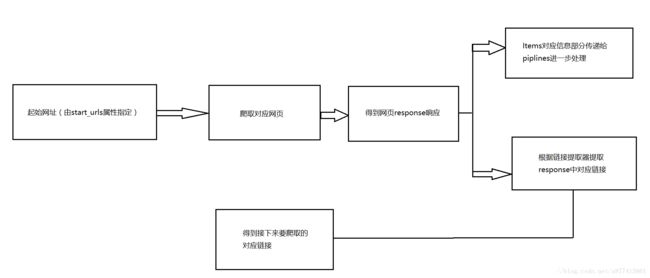
在上面代码中rules部分中的LinkExtractor为链接提取器,链接提取器主要负责将response响应中符合条件的链接提取出来,这些条件我们可以自行设置。
rules = (
Rule(LinkExtractor(allow='.*?/n.*?shtml'), callback='parse_item', follow=True),
)| 参数名 | 参数含义 |
|---|---|
| allow | 提取符合对应正则表达式的链接 |
| deny | 不提取符合对应正则表达式的链接 |
| restrict_xpaths | 使用XPath表达式与allow共同作用提取出同时符合对应XPath表达式和对应正则表达式的链接 |
| allow_domains | 允许提取的域名,比如我们想肢体去某个域名下的链接时会用到 |
| deny_domains | 禁止提取的域名,比如我们需要限制一定不提取某个域名下的链接时会用的 |
2、items.py
# -*- coding: utf-8 -*-
import scrapy
class MycwpjtItem(scrapy.Item):
name = scrapy.Field()
link = scrapy.Field()
3、pipelines.py
# -*- coding: utf-8 -*-
import codecs
class MycwpjtPipeline(object):
def __init__(self):
self.file = codecs.open("C:/Users/Administrator/Desktop/sinanew.txt", "wb", encoding="utf-8")
def process_item(self, item, spider):
# 拼接字符组成 标题:**** 链接:****
line = "标题:%s 链接:%s\n" % (item["name"][0], item["link"])
self.file.write(line)
def close_spider(self):
self.file.close()4、settings.py
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
# 取消注释
ITEM_PIPELINES = {
'mycwpjt.pipelines.MycwpjtPipeline': 300,
}4、运行命令
scrapy crawl bangbing --nolog
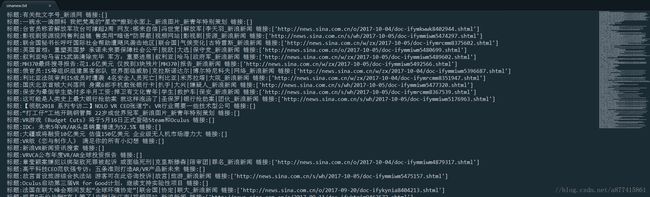
因为网页实在太多了,只运行了一部分就强制停止了,可以看桌面sinanew.txt文件,结果如下