hadoop2.0之mapReduce启动运行全流程解析
mapReduce在Hadoop2.x中各部分简介:
ResourceManager,RM :管理集群上资源使用的资源管理器:
Application Master ,AM :管理集群上运行任务声明周期的应用管理器:
应用服务器MA和资源管理器RM协商集群的计算资源:容器(Container,每个容器都有特定的内存上线),在这些容器上运行特定应用程序的进程,容器由集群节点上运行的节点管理器Node Manager监视,以确保应用程序使用的资源不会超过分配给他的资源。
NodeMagnager:管理每个节点上的资源和任务,主要有两个作用,定期向RM汇报该节点的资源使用情况和各个Container的运行状态;接收并处理AM任务的启动停止等请求。
应用的每一个MapReduce作业有一个专用的应用Master,他运行在应用的运行期间,他和MapReduce任务在任务容器(Container)中运行,这些容器由资源管理器ResourceManager分配并由节点管理器NodeManager进行管理。
MRAppMaster负责管理MapReduce作业的生命周期,包括作业管理、资源申请与再分配、Container启动与释放、作业恢复等。
作业提交:Job的submit()方法创建一个内部的JobSubmiter实例,并且调用其submitJobInternal()每秒轮询作业的进度,如果发现自从上次报告后有改变,,便把进度报告到控制台,作业完成后,如果成功就显示作业计数器,如果失败将导致作业失败的错误记录到控制台。
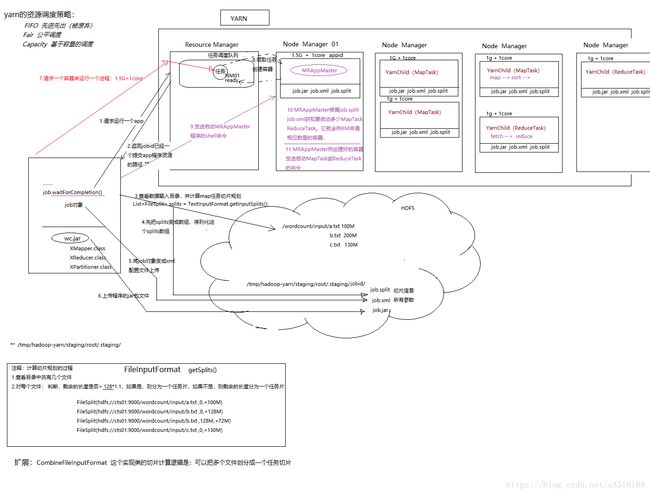
mapReduceq启动运行全流程具体如下:
第一步:
向资源管理器(ResourceManager)请求,要运行一个程序。中获取新的作业ID(jobId),以及程序资源存储路径
第二步
ResourceManager检查作业的输出说明,然后返回一个存放程序资源的路径以及jobId,这个路径在hdfs的tmp文件夹中,如果程序中没有指定输出目录或指定的输出目录已经存在,作业就不提交,错误返回给MapReduce程序
就是这个路径存放程序资源,包括切边信息,程序的jar包,job.xml配置文件等。
第三步
客户端去计算作业的输入分片,把job对象序列化为job.XML配置文件,里面全是 key,value。并把切边序列化成文件保存到hdfs的资源路径下,如果无法计算,比如因为输入路径不存在,作业就无法提交,将错误返回给Mapreduce程序
作业客户端检查作业的输出说明,在计算输入分片
第四步:
将作业资源(包括JAR、配置和分片信息)复制到HDFS,默认保存10份。
第五步:
通过调用资源管理器上的submitApplication()方法提交作业。
第六步
资源管理器收到调用它的submitApplication()消息后,如果容器不够,任务会现在等待队列中等待,之后便将请求传递给调度器(Schedule),调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动应用程序master进程也就是MRAPPMaster。
MapReduce作业的application master是一个Java应用程序,它的主类是MRAPPMaster他对作业进行初始化,通过创建多个薄记对象以保持对作业进度的跟踪,因为他将接受来自任务的进度和完成报告
第七步
MRAPPMaster根据切边信息,获知要启动多少个mapTask,向ResourceManager请求容器
第八步
一旦资源管理器的调度器为任务分配了容器,MRAPPMaster(application master) 就通过与节点管理器NodeManager通信来启动容器向已获得容器的mapTask或reduceerTask发从启动命令,也就是主类为YarnChild程序
注:有的也叫application master
具体如下:附着心跳信息的请求包括每个map任务的数据本地化信息,特别是输入片所在的主机和相应的机架信息,调度器使用这些信息来做调度决策,利用心跳的返回值与其进行通信,理想情况下,将他任务分配到数据本地化的节点,但是如果不能这样做,调度器就会相对于非本地化的分配优先使用机架本地化的分配。
任务由主类为YarnChild的java程序执行,它在运行之前,首先将任务需要的资源本地化,包括作业的配置、JAR文件、和所有来自分布式HDFS缓存的文件
最后运行map任务或reduce任务
在YARN下运行时,任务每三秒钟通过Umbilical接口向application master汇报进度和状态(包括技术器),作为作业的汇聚视图(aggregate view)。过程如图:客户端每秒钟(可以设置)查询一次application master已接收进度更新,通常会向用户显示。
mappReduce运行流程图