Kafka之Producer API使用【java版本】
前段时间需要配合kylin的流式计算,所以用java写了一个producer的程序,每秒向topic中产生数据,kylin则作为Topic的Consumer。主要的功能就是随机产生一些数据,这个程序里面主要的点个人认为是:时间戳的随机生成,发送JSON数据格式。直接上点干货,任何问题都可以在下方评论,小厨尽全力解决。
package com.bigdata.kylin;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import net.sf.json.JSONObject;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import kafka.serializer.StringEncoder;
//模拟产生网站点击数据:包括day,regionIdArray等
//2019-07-12|GBSHD87JD6HDKI98|G03|G0302|810|Mac OS|2
public class CreateData extends Thread{
private String topic;
public CreateData(String topic) {
super();
this.topic = topic;
}
@Override
public void run() {
//创建一个producer对象
Producer producer = createProduce();
//度量指标Cookieid
String cookieIdArray[] = {"0","1","2","3","4","5","6","7","8","9",
"A","B","C","D","E","F","G","H","I","J","K","L","M",
"N","O","P","Q","R","S","T","U","V","W","X","Y","Z"};
String regionIdArray[] = {"G01", "G02", "G03", "G04", "G05"};
String osIdArray[] = {"Android 7.0", "Mac OS", "Apple Kernel", "Windows","kylin OS","chrome"};
String cookieId = "";
String regionId = "" ;
String cityId = "" ;
String site = "";
String os = "";
String pv = "";
int i = 0;
//创建流数据,希望不停止的产生
while(true) {
//创建Json对象
JSONObject jsonObject = new JSONObject();
//定义时间即tempDate
Date date = randomDate("2013-01-01","2019-01-01");
//转换成时间戳
long access_time = date.getTime();
//转出时间格式的输出
String newDate = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date);
//定义一个18位的cookieId
for(int j=0; j<18; j++) {
int tmp = (int) (Math.random() * 35);
cookieId += cookieIdArray[tmp];
}
//定义一个记录省的字段G03
int k = (int) (Math.random() *4);
regionId = regionIdArray[k];
//记录省对应下面城市的字段G0302
int l = (int) (Math.random() * 2 )+1;
cityId = regionId + "0" +l;
//定义花费的流量
Random random = new Random();
int m = (int) Math.floor((random.nextDouble()*10000.0));
site = "" +m;
//记录操作系统的名称
int n = (int) (Math.random() * 2);
os = osIdArray[n];
//记录pv的值 1 到 10
int h = (int) (Math.random() * 9) +1;
pv = ""+h;
jsonObject.put("access_time", access_time);
jsonObject.put("cookieId", cookieId);
jsonObject.put("regionId", regionId);
jsonObject.put("cityId", cityId);
jsonObject.put("site", site);
jsonObject.put("os", os);
jsonObject.put("pv", pv);
System.out.println("Json object :"+jsonObject);
String json = newDate + "|" + cookieId + "|" + regionId + "|" + cityId + "|" + site + "|" +
os + "|" + pv + "\n";
System.out.println("发送第"+i+"条json数据:"+json);
cookieId = "";
i++;
producer.send(new KeyedMessage(topic,jsonObject.toString()));
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
private Producer createProduce() {
Properties properties = new Properties();
// 声明kafka broker
String brokerList = "192.168.1.203:9092,192.168.1.204:9093,192.168.1.205:9094";
properties.put("zookeeper.connect", "192.168.1.203:2181,192.168.1.204:2181,192.168.1.205:2181");//声明zk
properties.put("serializer.class", StringEncoder .class.getName());
properties.put("metadata.broker.list", brokerList);
return new Producer(new ProducerConfig(properties));
}
public static void main(String[] args) {
new CreateData("web_pvuv_kylin_streaming_topic").start();// 使用kafka集群中创建好的主题 emsSampleItems
}
/**
* 获取随机日期
* @param beginDate 起始日期,格式为:yyyy-MM-dd
* @param endDate 结束日期,格式为:yyyy-MM-dd
* @return
*/
private static Date randomDate(String beginDate,String endDate){
try {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
Date start = format.parse(beginDate);
Date end = format.parse(endDate);
if(start.getTime() >= end.getTime()){
return null;
}
long date = random(start.getTime(),end.getTime());
return new Date(date);
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
private static long random(long begin,long end){
long rtn = begin + (long)(Math.random() * (end - begin));
if(rtn == begin || rtn == end){
return random(begin,end);
}
return rtn;
}
}
注意:
问题描述:我们初次在java端发送数据到topic中时,可能会报以下错误:Failed to send messages after 3 tries
解决方法:在server.properties中修改以下的内容,很有可能是配置时没有指定具体的hostname,如下图。kafka默认是localhost,所以会报错。
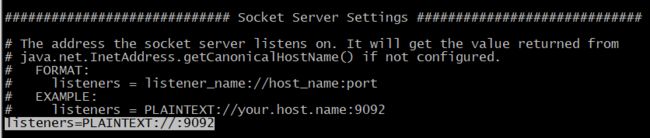
因此需要指定具体的主机名和端口号,如下:而且如果你是集群形式kafka配置的话,都要安装主机名的ip来配置下面内容。
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
listeners=PLAINTEXT://192.168.1.203:9092
#advertised.listeners=PLAINTEXT://your.host.name:9092
advertised.listeners=PLAINTEXT://192.168.1.203:9092最后:再来看一看Producer的内部实现
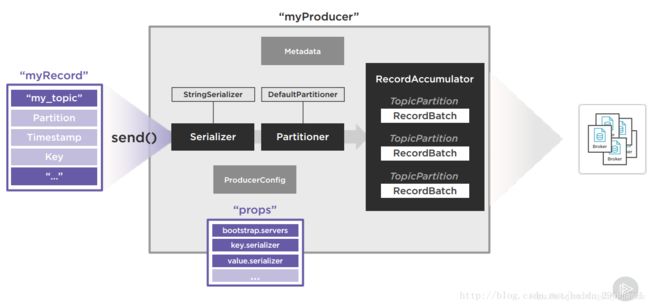
1、客户端写程序,通过props中写的属性来连接broker集群,连接zookeeper集群,获取metadata信息,调用send()方法。
2、ProducerRecord对象携带者topic,partition,message等信息,在Serializer中被序列化。
3、序列化过后的ProducerRecord对象进入Partitioner“中,按照Partitioning 策略决定这个消息将被分配到哪个Partition中。
4、确定partition的ProducerRecord进入一个缓冲区,通过减少IO来提升性能,在这个“车间”,消息被按照TopicPartition信息进行归类整理,相同Topic且相同parition的ProducerRecord被放在同一个RecordBatch中,等待被发送。什么时候发送?都在Producer的props中被指定了,有默认值,显然我们可以自己指定。
(1) batch.size:设置每个RecordBatch可以缓存的最大字节数
(2) buffer.memory:设置所有RecordBatch的总共最大字节数
(3) linger.ms设置每个RecordBatch的最长延迟发送时间
(4) max.block.ms 设置每个RecordBatch的最长阻塞时间
一旦,当单个RecordBatch的linger.ms延迟到达或者batch.size达到上限,这个 RecordBatch会被立即发送。另外,如果所有RecordBatch作为一个整体,达到了buffer.memroy或者max.block.ms上限,所有的RecordBatch都会被发送。
5、ProducerRecord消息按照分配好的Partition发送到具体的broker中,broker接收保存消息,更新Metadata信息,同步给Zookeeper