DL笔记:PascalVOC 数据集介绍+数据集标注工具!
| PascalVOC 数据集介绍+数据集标注工具! |
文章目录
- 一、Challenge
- 1.1、数据集的主要任务
- 1.2、VOC2012文件夹
- 1.3、Annotations
- 1.4、ImageSets
- 1.5、JPEGImages
- 二、数据集标注软件:labelImg
- 2.1、labelmg软件简单介绍
- 2.2、解决Imagesets里的文件
Pascal VOC challenge 是一个非常流行的数据集,用于构建和评估图像分类、对象检测和分割的算法。官网数据集镜像:数据集下载链接
一、Challenge
Pascal VOC challenge 的目标就是从存在于现实场景中的许多可视对象类别中识别出对象(即不预先分割的对象)。全部有二十个类:
person, bird, cat, cow, dog, horse, sheep, aeroplane, bicycle, boat, bus, car,
motorbike, train, bottle, chair, dining table, potted plant, sofa, tv / monitor
由于我们是将数据用于检测,因此,我们只关注Annotation、ImageSets、JPEGImages这三个文件夹。下面我们逐个分析每一个文件夹下面的内容:
- ImageSets/Main/ 保存了具体数据集的索引;
- Annotations 保存了标签数据;
- JPEGImages 保存了图片内容。
1.1、数据集的主要任务
有五个主要任务:
- 1、分类: 对于每一个类,在一张测试图片中预测该类至少一个对象是否存在。
- 2、检测: 对于每一个类,在一张测试图片中预测该类的每一个对象的边界框(bounding box)。
- 3、分割: 对于测试图片每一个像素,如果像素不属于20个指定类中的一个,则预测包含该像素或“背景”的对象的类。
- 4、动作分类: 对于每个动作类别,预测测试图片中的指定的人(由其边界框指示)是否正在执行相应的动作。其中有 10 个动作类别:
jumping; phoning; playing a musical instrument; reading; riding a bicycle or motorcycle; riding a horse; running; taking a photograph;using a computer; walking - 5、大尺度识别: 这个任务又 ImageNet 组织者执行。更多可查看其官网。
1.2、VOC2012文件夹
里面有一个 VOC2007 ,另一个是 VOC2012 。进去里面有 5 个文件夹;
- VOC2012
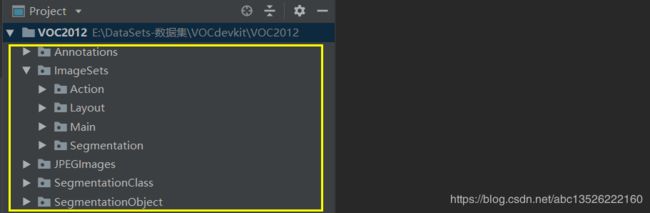
- Annotations:存放 xml 文件,每个文件对应 JPEGImage 里面的一张图片;
- JPEGImage:存放图片,每张图片都有对应的编号;
- SegmentationClass:存放分割图片,按类分,相同的类用同一个颜色表示;
- SegmentationObject:存放分割图片,按物体分, 不同的物体用不同的颜色表示;
1.3、Annotations
- xml 是可扩展标记语言,文件里面内容大概如下:
VOC2012
2007_000027.jpg
The VOC2007 Database
PASCAL VOC2007
flickr
486
500
3
0
- 其中里面指定了文件夹,文件名字,图片的长宽和深度,还有边界框(bounding box)及物体类别。;
1.4、ImageSets
- ImageSets/Main/ 文件夹里面文件以 class_trainval.txt、class_val.txt 的格式命名。 train.txt val.txt 例外。
aeroplane_train.txt
aeroplane_trainval.txt
aeroplane_val.txt
bicycle_train.txt
bicycle_trainval.txt
bicycle_val.txt
bird_train.txt
bird_trainval.txt
bird_val.txt
boat_train.txt
boat_trainval.txt
boat_val.txt
bottle_train.txt
bottle_trainval.txt
bottle_val.txt
bus_train.txt
bus_trainval.txt
bus_val.txt
car_train.txt
car_trainval.txt
car_val.txt
cat_train.txt
cat_trainval.txt
cat_val.txt
chair_train.txt
chair_trainval.txt
chair_val.txt
cow_train.txt
cow_trainval.txt
cow_val.txt
diningtable_train.txt
diningtable_trainval.txt
diningtable_val.txt
dog_train.txt
dog_trainval.txt
dog_val.txt
horse_train.txt
horse_trainval.txt
horse_val.txt
motorbike_train.txt
motorbike_trainval.txt
motorbike_val.txt
person_train.txt
person_trainval.txt
person_val.txt
pottedplant_train.txt
pottedplant_trainval.txt
pottedplant_val.txt
sheep_train.txt
sheep_trainval.txt
sheep_val.txt
sofa_train.txt
sofa_trainval.txt
sofa_val.txt
train.txt
train_train.txt
train_trainval.txt
train_val.txt
trainval.txt
tvmonitor_train.txt
tvmonitor_trainval.txt
tvmonitor_val.txt
val.txt
其中如下:
- {class}_train.txt 保存类别为 class 的训练集的所有索引,每一个 class 的 train 数据都有 5717 个。
- {class}_val.txt 保存类别为 class 的验证集的所有索引,每一个 class 的val数据都有 5823 个
- {class}_trainval.txt 保存类别为 class 的训练验证集的所有索引,每一个 class 的val数据都有11540 个
每个文件包含内容为:
2011_003194 -1
2011_003216 -1
2011_003223 -1
2011_003230 1
2011_003236 1
2011_003238 1
2011_003246 1
2011_003247 0
2011_003253 -1
2011_003255 1
2011_003259 1
2011_003274 -1
2011_003276 -1
注:1代表正样本,-1代表负样本。
-
VOC2012 / ImageSets / Main / train.txt保存了所有训练集的文件名 ,从 VOC2012/JPEGImages/ 找到文件名对应的图片文件。VOC2012/Annotations/ 找到文件名对应的标签文件;
-
VOC2012/ImageSets/Main/val.txt 保存了所有验证集的文件名,从 VOC2012/JPEGImages/ 找到文件名对应的图片文件。VOC2012/Annotations/ 找到文件名对应的标签文件
-
读取 JPEGImages 和 Annotation 文件转换为 tf 的 Example 对象,写入 {train|test}{index}_of{num_shard} 文件。每个文件写的 Example 的数量为 total_size/num_shard。(不同数据集可以适当调节 num_shard 来控制每个输出文件的大小)
1.5、JPEGImages
- 这个文件夹主要放置数据的原始图片,图片的文件名用00001.jpg进行命名。
二、数据集标注软件:labelImg
LabelImg 是一个可视化的图像标定工具。使用该工具前需配置环境python + lxml。Faster R-CNN,YOLO,SSD等目标检测网络所需要的数据集,均需要借此工具标定图像中的目标。生成的 XML 文件是遵循 PASCAL VOC 的格式的。适用于图像检测任务的数据集制作。它来自下面的项目:https://github.com/tzutalin/labelImg
-
软件在github上下载地址:https://tzutalin.github.io/labelImg/ ;或者使用下面的百度云链接。
-
解决Annotation文件;使用标注软件对数据手动标注,软件会自动生成图片信息的xml文件。
软件下载链接,提取码:l53r
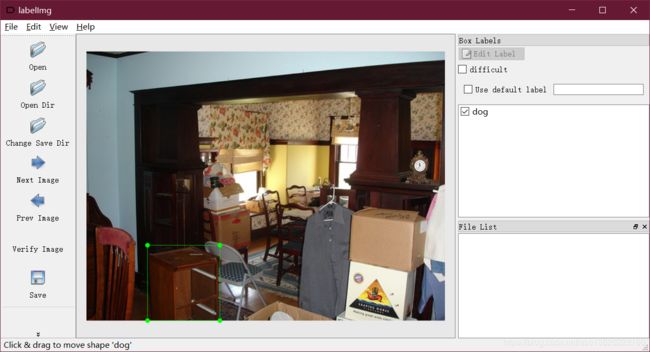
2.1、labelmg软件简单介绍
- 导入图片
- 点击左侧的create Rect 创建标注框
- 可以创建新的Label
- 最后点击verifyImage进行确认,导出XML文件
- 生成的XML文件内容如下:
Desktop
000005.jpg
C:/Users/Devinzhang/Desktop/000005.jpg
Unknown
500
375
3
0
2.2、解决Imagesets里的文件
- 先抄别人一份代码,然后自己修改
import os
import random
trainval_percent = 0.66
train_percent = 0.5
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
参考了以下作者:
- https://blog.csdn.net/weixin_39679367/article/details/80932532
- https://blog.csdn.net/wenxueliu/article/details/80327316
- https://blog.csdn.net/qq_33297776/article/details/79758342