TensorFlow2.0笔记19:GoogleNet-Iception介绍以及测试+Batch Normalization讲解!
| GoogleNet-Iception介绍以及测试+Batch Normalization讲解! |
文章目录
- 一、GoogleNet-Iception V1(2014)介绍
- 1.1、为什么提出Inception
- 1.2、Inception模块介绍
- 1.3、Inception作用
- 1.4、googLeNet-Inception V1结构
- 二、GoogleNet-Iception V2介绍
- 2.1、Batch Normalization
- 2.1.1、为了解决什么问题提出的BN
- 2.1.2、BN的来源
- 2.1.3、BN的本质
- 2.2、Inception V2结构
- 三、GoogleNet-Iception V3介绍
- 四、GoogleNet-Iception V4介绍
- 五、Tensorflow2.0实战Fashion_mnist数据集
- 5.0、补充知识点keras.layers.add()和keras.layer.conatenate()
- 5.1、构建CNN基本单元Conv+BN+Relu类模块
- 5.2、构建Inception Block模块
- 5.3、构建Res Block 模块
- 5.4、最终代码如下
- 5.5、演示结果
- 六、Batch Normalization讲解
- 6.1、直观介绍
- 6.2、简单例子
- 6.3、tensorflow中如何实现BN层
- 6.4、使用BN层好处
- 七、需要全套课程视频+PPT+代码资源可以私聊我!
- 参考文章
- 可以先参考一下我之前写过的一篇博客的介绍:第6章视觉分类任务
一、GoogleNet-Iception V1(2014)介绍
- 这篇论文之前的卷积神经网络的性能提高都是依赖于提高网络的深度和宽度,而这篇论文是从网络结构上入手,改变了网络结构,所以个人认为,这篇论文价值很大。主要贡献:提出了inception的卷积网络结构。
- 下面将从三个方面介绍为什么提出Inception,Inception模块介绍,Inception作用
1.1、为什么提出Inception
提高网络最简单粗暴的方法就是提高网络的深度和宽度,即增加隐层和以及各层神经元数目。但这种简单粗暴的方法存在一些问题:
- ① 参数太多,若训练数据集有限,容易过拟合;
- ② 网络越大计算复杂度越大,难以应用;
- ③ 网络越深,梯度越往后穿越容易消失,难以优化模型(这个时候还没有提出BN时,网络的优化极其困难)。
基于此,为了提高网络计算资源的利用率,在计算量不变的情况下,提高网络的宽度和深度。论文作者认为,解决这种困难的方法就是,把全连接改成稀疏连接,卷积层也是稀疏连接,但是不对称的稀疏数据数值计算效率低下,因为硬件全是针对密集矩阵优化的,所以,我们要找到卷积网络可以近似的最优局部稀疏结构,并且该结构下可以用现有的密度矩阵计算硬件实现,产生的结果就是Inception。
1.2、Inception模块介绍

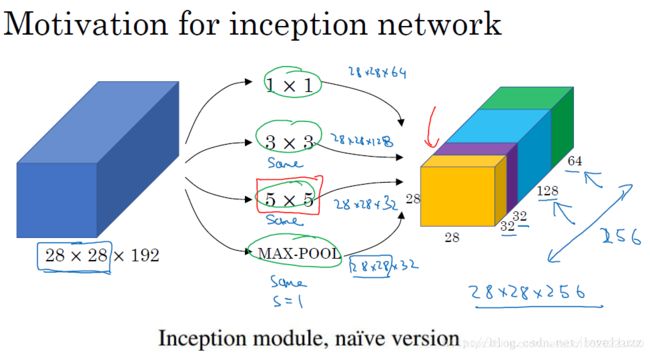
对上图做以下说明:
首先看第一个结构,有四个通道,有1×1、3×3、5×5卷积核,该结构有几个特点:
- ① 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- ② 之所以卷积核大小采用1×1、3×3、5×5主要是为了方便对齐。设定卷积步长stride=1之后,采用大小不同的卷积核,只要分别设定padding =0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
- ③ 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
- ④ 网络越到后面特征越抽象,且每个特征涉及的感受野也更大,随着层数的增加,3x3和5x5卷积的比例也要增加。
但是这个结构有个缺点,计算成本。 使用5x5的卷积核仍然会带来巨大的计算量,约需要1.2亿次的计算量。

那么作者想到了第二个结构,用1×1的卷积核进行降维,示意图如下:这个1×1的卷积核,它的作用就是:
- ① 降低维度(通道数),减少计算瓶颈。
- ② 增加网络层数,提高网络的表达能力。

在3x3和5x5的过滤器前面,max pooling后分别加上了1x1的卷积核,最后将它们全部以通道/厚度为轴拼接起来,最终输出大小为2828256,卷积的参数数量比原来减少了4倍,得到最终版本的Inception模块如下:

1.3、Inception作用
作者指出了Inception的优点:
- ① 显著增加了每一步的单元数目,计算复杂度不会不受限制,尺度较大的块卷积之前先降维。
- ② 视觉信息在不同尺度上进行处理聚合,这样下一步可以从不同尺度提取特征。
但是具体,为什么Inception会起作用,一直想不明白,作者后面实验也证明了GoogLeNet的有效性,但为什么也没有具体介绍。深度学习也是一个实践先行的学科,实践领先于理论,实践证明了它的有效性。后来看到一个博客,解开了我的谜团。在此贴出他的回答就是:
- Inception的作用:代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为的决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数。
1.4、googLeNet-Inception V1结构
googlenet的主要思想就是围绕这两个思路去做的:
- ① 深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题。
- ② 宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。

对上图做如下说明::
- ① 显然GoogLeNet采用了Inception模块化(9个)的结构,共22层,方便增添和修改;
- ② 网络最后采用了average pooling来代替全连接层,想法来自NIN,参数量仅为AlexNet的1/12,性能优于AlexNet,
事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便finetune; - ③ 虽然移除了全连接,但是网络中依然使用了Dropout ;
- ④ 为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。此外,实际测试的时候,这两个额外的softmax会被去掉。
- ⑤ 上述的GoogLeNet的版本成它使用的Inception V1结构。
googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
二、GoogleNet-Iception V2介绍
这篇论文主要思想在于提出了Batch Normalization,其次就是稍微改进了一下Inception。
2.1、Batch Normalization
这个算法太牛了,使得训练深度神经网络成为了可能。从一下几个方面来介绍。
- ① 为了解决什么问题提出的BN
- ② BN的来源
- ③ BN的本质
2.1.1、为了解决什么问题提出的BN
训练深度神经网络时,作者提出一个问题,叫做“Internal Covariate Shift”。
这个问题是由于在训练过程中,网络参数变化所引起的。具体来说,对于一个神经网络,第n层的输入就是第n-1层的输出,在训练过程中,每训练一轮参数就会发生变化,对于一个网络相同的输入,但n-1层的输出却不一样,这就导致第n层的输入也不一样,这个问题就叫做“Internal Covariate Shift”。
2.1.2、BN的来源
白化操作–在传统机器学习中,对图像提取特征之前,都会对图像做白化操作,即对输入数据变换成0均值、单位方差的正态分布。 卷积神经网络的输入就是图像,白化操作可以加快收敛,对于深度网络,每个隐层的输出都是下一个隐层的输入,即每个隐层的输入都可以做 白化操作。
在训练中的每个mini-batch上做正则化:


2.1.3、BN的本质
我的理解BN的主要作用就是:
- ① 加速网络训练
- ② 防止梯度消失
如果激活函数是sigmoid,对于每个神经元,可以把逐渐向非线性映射的两端饱和区靠拢的输入分布,强行拉回到0均值单位方差的标准正态分布,即激活函数的兴奋区,在sigmoid兴奋区梯度大,即加速网络训练,还防止了梯度消失。基于此,BN对于sigmoid函数作用大。sigmoid函数在区间[-1, 1]中,近似于线性函数。如果没有这个公式:
y i ← γ x ^ i + β ≡ B N γ , β ( x i ) y_{i} \leftarrow \gamma \widehat{x}_{i}+\beta \equiv \mathrm{B} \mathrm{N}_{\gamma, \beta}\left(x_{i}\right) yi←γx i+β≡BNγ,β(xi)
就会降低了模型的表达能力,使得网络近似于一个线性映射,因此加入了scale 和shift。 它们的主要作用就是找到一个线性和非线性的平衡点,既能享受非线性较强的表达能力,有可以避免非线性饱和导致网络收敛变慢问题。
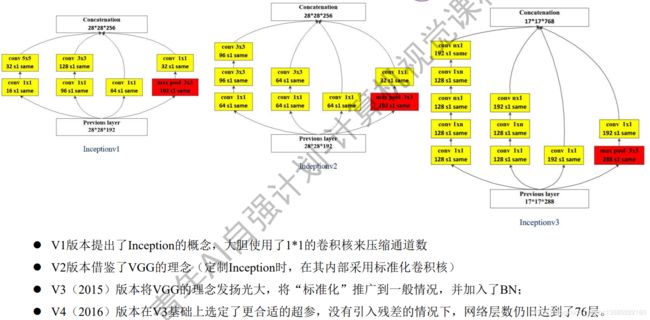
2.2、Inception V2结构
大尺寸的卷积核可以带来更大的感受野,也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,这便是Inception V2结构。这也是VGG那篇论文所提到的思想。这样做法有两个优点:可以参考我开篇推荐的博客。
- ① 保持相同感受野的同时减少参数
- ② 加强非线性的表达能力
如下图:
三、GoogleNet-Iception V3介绍
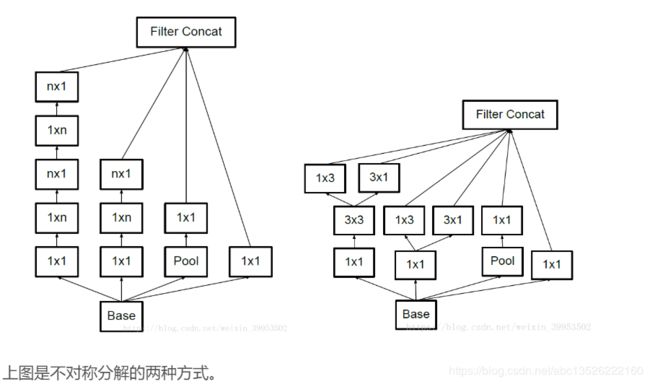
大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。Inception V2中:将55的卷积核替换成2个33的卷积核;上图左边是原来的Inception,右图是改进的Inception

另一种方法就是将nxn的卷积都可以通过1xn卷积后接nx1卷积来替代,计算量又会降低。但是第二种分解方法在大维度的特征图上表现不好,在特征图12-20维度上表现好。不对称分解方法有几个优点:
- ① 节约了大量的参数
- ② 增加一层非线性,提高模型的表达能力
- ③ 可以处理更丰富的空间特征,增加特征的多样性

四、GoogleNet-Iception V4介绍
这篇论文,没有公式,全篇都是画图,就是网络结构。主要思想很简单:Inception表现很好,很火的ResNet表现也很好,那就想办法把他们结合起来呗。
还有几个作者通过实验总结的几个知识点:。
- ① Residual Connection: 作者认为残差连接并不是深度网络所必须的(PS:ResNet的作者说残差连接时深度网络的标配),没有残差连接的网络训练起来并不困难,因为有好的初始化以及Batch Normalization,但是它确实可以大大的提升网路训练的速度。
- ② Residual Inception Block:
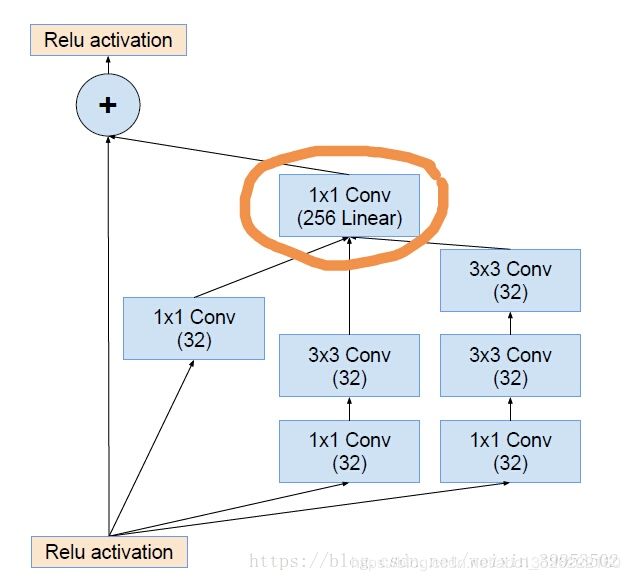
画圈的部分,那个1×1的卷积层并没有激活函数,这个作用主要是维度对齐。
- ③ Scaling of the Residual:当过滤器的数目超过1000个的时候,会出现问题,网络会“坏死”,即在average pooling层前都变成0。即使降低学习率,增加BN层都没有用。这时候就在激活前缩小残差可以保持稳定。即下图:
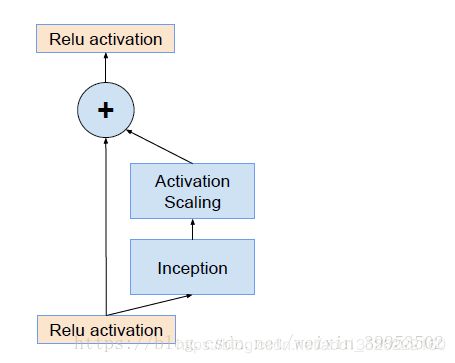
- ④ 网络精度提高原因:残差连接只能加速网络收敛,真正提高网络精度的还是“更大的网络规模”。
五、Tensorflow2.0实战Fashion_mnist数据集
5.0、补充知识点keras.layers.add()和keras.layer.conatenate()
- add对张量执行求和运算(通道数不变,值相加)
- concatenate对张量进行串联运算(通道数相加)
Resnet是做值的叠加,通道数是不变的,DenseNet是做通道的合并。你可以这么理解,add是描述图像的特征下的信息量增多了,但是描述图像的维度本身并没有增加,只是每一维下的信息量在增加,这显然是对最终的图像的分类是有益的。而concatenate是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。在代码层面就是ResNet使用的都是add操作,而DenseNet使用的是concatenate。
在深度神经网络中,经常会遇到需要把张量结合在一起的情况,比如Inception网络。add()和conetenate()经常出现,用来将两个张量结合在一起。具体了解可以参考博客:https://blog.csdn.net/u012193416/article/details/79479935
5.1、构建CNN基本单元Conv+BN+Relu类模块
- 基本的卷积神经网络单元由:卷积层+批量归一化+激活层!
class ConvBNRelu(keras.Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = keras.models.Sequential([
keras.layers.Conv2D(ch, kernelsz, strides=strides, padding=padding), # 卷积
keras.layers.BatchNormalization(), #批量归一化
keras.layers.ReLU() #激活函数
])
def call(self, x, training=None):
x = self.model(x, training=training)
return x
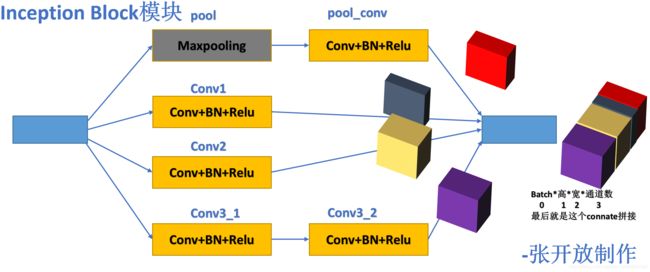
5.2、构建Inception Block模块
- 这里需要用到拼接操作:详细介绍参考我的博客tensorFlow2.0的高阶操作!
- 为了便于理解我用ppt把这部分画图来表示出来,如下:
class InceptionBlk(keras.Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__() # 父类方法
self.ch = ch # 赋值
self.strides = strides # 赋值
self.conv1 = ConvBNRelu(ch, strides=strides) # 构造第1个CNN基本单元
self.conv2 = ConvBNRelu(ch, kernelsz=3, strides=strides) # 构造第2个CNN基本单元,卷积核大小初始为3*3
self.conv3_1 = ConvBNRelu(ch, kernelsz=3, strides=strides)# 构造第3_1个CNN基本单元,卷积核大小初始为3*3
self.conv3_2 = ConvBNRelu(ch, kernelsz=3, strides=1) # 构造第3_2个CNN基本单元,卷积核大小初始为3*3
self.pool = keras.layers.MaxPooling2D(3, strides=1, padding='same') # 最大池化层,same
self.pool_conv = ConvBNRelu(ch, strides=strides) #构造CNN基本单元,卷积核大小初始为3*3
def call(self, x, training=None):
x1 = self.conv1(x, training=training)
x2 = self.conv2(x, training=training)
x3_1 = self.conv3_1(x, training=training)
x3_2 = self.conv3_2(x3_1, training=training)
x4 = self.pool(x)
x4 = self.pool_conv(x4, training=training)
# concat along axis=channel
x = tf.concat([x1, x2, x3_2, x4], axis=3) # 通道数扩充,上图理解。
return x
5.3、构建Res Block 模块
- Res Block 模块继承keras.Model或者keras.Layer都可以

# Res Block 模块。继承keras.Model或者keras.Layer都可以
class Inception(keras.Model):
def __init__(self, num_layers, num_classes, init_ch=16, **kwargs):
super(Inception, self).__init__(**kwargs)
self.in_channels = init_ch # 初始输入通道
self.out_channels = init_ch # 初始输出通道数
self.num_layers = num_layers # 初始层数,就是多少个res block
self.init_ch = init_ch # 初始通道
self.conv1 = ConvBNRelu(init_ch) # 构造1个CNN基本单元
self.blocks = keras.models.Sequential(name='dynamic-blocks') # 创建一个Sequential容器对象
for block_id in range(num_layers): # for循环,循环次数为num_layers传输的参数;
for layer_id in range(2): # 2个Inception Block模块构建一个参考块,循环2次;
if layer_id == 0: # 如果为第1次循环的话
block = InceptionBlk(self.out_channels, strides=2) # 创建1个Inception Block模块,并且步长为2;
else: # 如果为第2次循环的话
block = InceptionBlk(self.out_channels, strides=1)# 创建1个Inception Block模块,并且步长为1;
self.blocks.add(block) # 把block放进容器对象blocks中
# enlarger out_channels per block # 通道数扩大为2倍。
self.out_channels *= 2
self.avg_pool = keras.layers.GlobalAveragePooling2D()
self.fc = keras.layers.Dense(num_classes)
5.4、最终代码如下
- inception.py文件
import tensorflow as tf
import numpy as np
from tensorflow import keras
class ConvBNRelu(keras.Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = keras.models.Sequential([
keras.layers.Conv2D(ch, kernelsz, strides=strides, padding=padding),
keras.layers.BatchNormalization(),
keras.layers.ReLU()
])
def call(self, x, training=None):
x = self.model(x, training=training)
return x
# Inception Block 模块。
class InceptionBlk(keras.Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.conv1 = ConvBNRelu(ch, strides=strides)
self.conv2 = ConvBNRelu(ch, kernelsz=3, strides=strides)
self.conv3_1 = ConvBNRelu(ch, kernelsz=3, strides=strides)
self.conv3_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.pool = keras.layers.MaxPooling2D(3, strides=1, padding='same')
self.pool_conv = ConvBNRelu(ch, strides=strides)
def call(self, x, training=None):
x1 = self.conv1(x, training=training)
x2 = self.conv2(x, training=training)
x3_1 = self.conv3_1(x, training=training)
x3_2 = self.conv3_2(x3_1, training=training)
x4 = self.pool(x)
x4 = self.pool_conv(x4, training=training)
# concat along axis=channel 通道数
x = tf.concat([x1, x2, x3_2, x4], axis=3)
return x
# Res Block 模块。继承keras.Model或者keras.Layer都可以
class Inception(keras.Model):
def __init__(self, num_layers, num_classes, init_ch=16, **kwargs):
super(Inception, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_layers = num_layers
self.init_ch = init_ch
self.conv1 = ConvBNRelu(init_ch)
self.blocks = keras.models.Sequential(name='dynamic-blocks')
for block_id in range(num_layers):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2
self.avg_pool = keras.layers.GlobalAveragePooling2D()
self.fc = keras.layers.Dense(num_classes)
def call(self, x, training=None):
out = self.conv1(x, training=training)
out = self.blocks(out, training=training)
out = self.avg_pool(out)
out = self.fc(out)
return out
- inception_fashion.py
import tensorflow as tf
from tensorflow.python.keras.api._v2.keras import layers, optimizers, datasets, Sequential
import tensorflow.keras as keras
import numpy as np
import inception
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
tf.random.set_seed(22)
batchsize = 512
def preprocess(x, y): #数据预处理
x = tf.cast(x, dtype=tf.float32)/ 255. - 0.5
y = tf.cast(y, dtype=tf.int32)
return x,y
(x_train, y_train),(x_test, y_test) = datasets.fashion_mnist.load_data()
print(x_train.shape, y_train.shape)
# [b, 28, 28] => [b, 28, 28, 1]
x_train, x_test = np.expand_dims(x_train, axis=3), np.expand_dims(x_test, axis=3)
#训练集预处理
db_train = tf.data.Dataset.from_tensor_slices((x_train,y_train)) #构造数据集,这里可以自动的转换为tensor类型了
db_train = db_train.map(preprocess).shuffle(10000).batch(batchsize)
#测试集预处理
db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test)) #构造数据集
db_test = db_test.map(preprocess).shuffle(10000).batch(batchsize)
db_iter = iter(db_train)
sample = next(db_iter)
print("batch: ", sample[0].shape, sample[1].shape)
# 调用Inception
model = inception.Inception(2, 10) # 第一参数为残差块数,第二个参数为类别数;
# derive input shape for every layers.
model.build(input_shape=(None, 28, 28, 1))
model.summary()
optimizer =optimizers.Adam(learning_rate=1e-3)
criteon = keras.losses.CategoricalCrossentropy(from_logits=True) # 分类器
acc_meter = keras.metrics.Accuracy()
for epoch in range(100):
for step, (x, y) in enumerate(db_train):
with tf.GradientTape() as tape:
# print(x.shape, y.shape)
# [b, 10]
logits = model(x)
# [b] vs [b, 10]
loss = criteon(tf.one_hot(y, depth=10), logits)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
if step % 20 == 0:
print(epoch, step, 'loss:', loss.numpy())
# 测试集测试
acc_meter.reset_states()
for x, y in db_test:
# [b, 10]
logits = model(x, training=False)
# [b, 10] => [b]
pred = tf.argmax(logits, axis=1)
# [b] vs [b, 10]
acc_meter.update_state(y, pred)
print(epoch, 'evaluation acc:', acc_meter.result().numpy())
5.5、演示结果
(60000, 28, 28) (60000,)
WARNING: Logging before flag parsing goes to stderr.
W0711 23:47:42.432590 140036048033536 deprecation.py:323] From /home/zhangkf/anaconda3/envs/tf2b/lib/python3.7/site-packages/tensorflow/python/data/util/random_seed.py:58: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
batch: (512, 28, 28, 1) (512,)
Model: "inception"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv_bn_relu (ConvBNRelu) multiple 224
_________________________________________________________________
dynamic-blocks (Sequential) multiple 292704
_________________________________________________________________
global_average_pooling2d (Gl multiple 0
_________________________________________________________________
dense (Dense) multiple 1290
=================================================================
Total params: 294,218
Trainable params: 293,226
Non-trainable params: 992
_________________________________________________________________
0 0 loss: 2.3062627
0 20 loss: 1.3878608
0 40 loss: 0.96548414
0 60 loss: 0.7939171
0 80 loss: 0.7293613
0 100 loss: 0.71290135
0 evaluation acc: 0.7019
1 0 loss: 0.71384096
1 20 loss: 0.6413231
1 40 loss: 0.5444199
1 60 loss: 0.57482886
1 80 loss: 0.5870902
1 100 loss: 0.62352675
1 evaluation acc: 0.785
2 0 loss: 0.5488965
2 20 loss: 0.51819783
2 40 loss: 0.43092453
2 60 loss: 0.48387557
2 80 loss: 0.47278112
2 100 loss: 0.54693735
2 evaluation acc: 0.8282
3 0 loss: 0.4545316
3 20 loss: 0.460625
3 40 loss: 0.37797207
3 60 loss: 0.4508713
3 80 loss: 0.42429122
3 100 loss: 0.4656887
3 evaluation acc: 0.8492
4 0 loss: 0.40070826
4 20 loss: 0.4085883
4 40 loss: 0.3293009
4 60 loss: 0.38098085
4 80 loss: 0.37324986
4 100 loss: 0.40731508
4 evaluation acc: 0.86
5 0 loss: 0.3638321
5 20 loss: 0.3789175
5 40 loss: 0.31341997
5 60 loss: 0.3372639
5 80 loss: 0.3431973
5 100 loss: 0.37353534
5 evaluation acc: 0.8658
6 0 loss: 0.3457242
6 20 loss: 0.37189817
6 40 loss: 0.29434854
6 60 loss: 0.32680446
6 80 loss: 0.31602854
6 100 loss: 0.3417113
6 evaluation acc: 0.872
7 0 loss: 0.3242044
7 20 loss: 0.35162193
7 40 loss: 0.28091648
7 60 loss: 0.29810786
7 80 loss: 0.31118444
7 100 loss: 0.34074044
7 evaluation acc: 0.8781
8 0 loss: 0.30457297
8 20 loss: 0.36898908
8 40 loss: 0.28175527
8 60 loss: 0.27074653
8 80 loss: 0.28818542
8 100 loss: 0.33216953
8 evaluation acc: 0.8806
9 0 loss: 0.29505867
9 20 loss: 0.3343888
9 40 loss: 0.28042865
9 60 loss: 0.24938875
9 80 loss: 0.26679343
9 100 loss: 0.32224196
9 evaluation acc: 0.877
10 0 loss: 0.29603648
10 20 loss: 0.31685665
10 40 loss: 0.25049022
10 60 loss: 0.2399058
10 80 loss: 0.25686044
10 100 loss: 0.29550925
10 evaluation acc: 0.8761
11 0 loss: 0.29622185
11 20 loss: 0.3230267
11 40 loss: 0.25293443
11 60 loss: 0.23401883
11 80 loss: 0.26247272
11 100 loss: 0.28616416
11 evaluation acc: 0.8962
12 0 loss: 0.24420242
12 20 loss: 0.34175372
12 40 loss: 0.24301699
12 60 loss: 0.22341698
12 80 loss: 0.2514168
12 100 loss: 0.2776959
12 evaluation acc: 0.9001
13 0 loss: 0.22918819
13 20 loss: 0.33287078
13 40 loss: 0.23378477
13 60 loss: 0.2111378
13 80 loss: 0.24327326
13 100 loss: 0.27276847
13 evaluation acc: 0.9028
14 0 loss: 0.21880059
14 20 loss: 0.3249494
14 40 loss: 0.22745952
14 60 loss: 0.20314743
14 80 loss: 0.23886529
14 100 loss: 0.27457932
14 evaluation acc: 0.9037
15 0 loss: 0.2080937
15 20 loss: 0.3148314
15 40 loss: 0.21847999
15 60 loss: 0.19718158
15 80 loss: 0.23375335
15 100 loss: 0.27651834
15 evaluation acc: 0.9048
16 0 loss: 0.20193794
16 20 loss: 0.29960066
16 40 loss: 0.20830427
16 60 loss: 0.18935196
16 80 loss: 0.22773671
16 100 loss: 0.2750058
16 evaluation acc: 0.9018
17 0 loss: 0.20367572
17 20 loss: 0.27100685
17 40 loss: 0.19907223
17 60 loss: 0.18021488
17 80 loss: 0.22271718
17 100 loss: 0.26856798
17 evaluation acc: 0.9017
18 0 loss: 0.20412329
18 20 loss: 0.27335256
18 40 loss: 0.18957056
18 60 loss: 0.17282292
18 80 loss: 0.21573594
18 100 loss: 0.26304978
18 evaluation acc: 0.9015
19 0 loss: 0.20294647
19 20 loss: 0.26247466
19 40 loss: 0.18275103
19 60 loss: 0.16331443
19 80 loss: 0.21146846
19 100 loss: 0.25919038
19 evaluation acc: 0.9026
六、Batch Normalization讲解
6.1、直观介绍
- 首先下面来一个直观的解释。
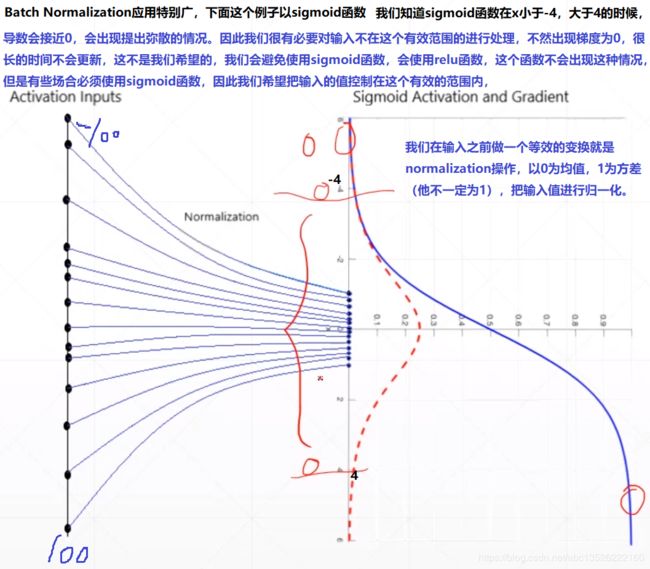
- 下面这个图摘选自李宏毅老师的课件,理解起来更直观。
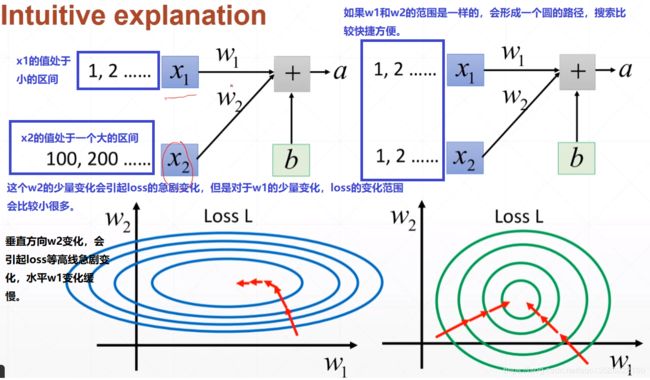

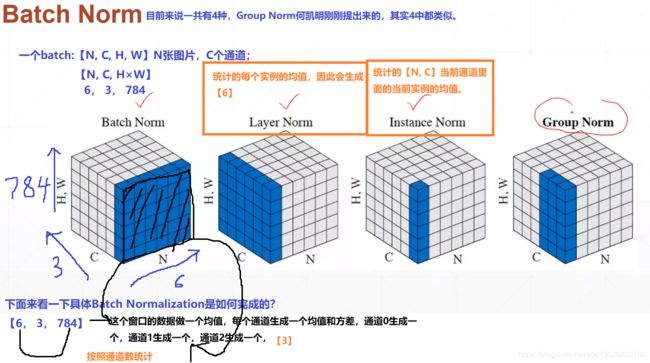
6.2、简单例子
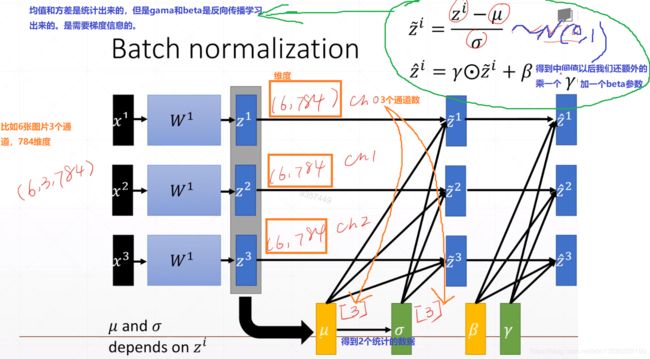
这里gama和beta相当于进行了一个缩放,缩放到正态的beta和gama的分布。

6.3、tensorflow中如何实现BN层

- 默认是在测试中
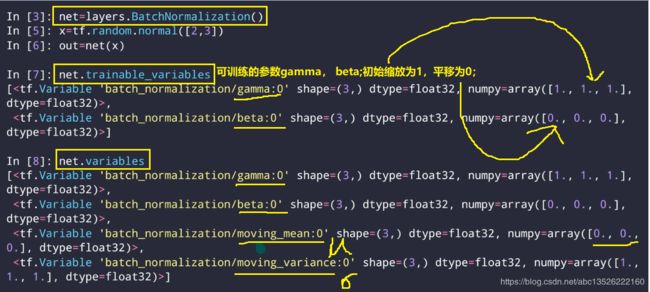

- 训练模式中、前向传播
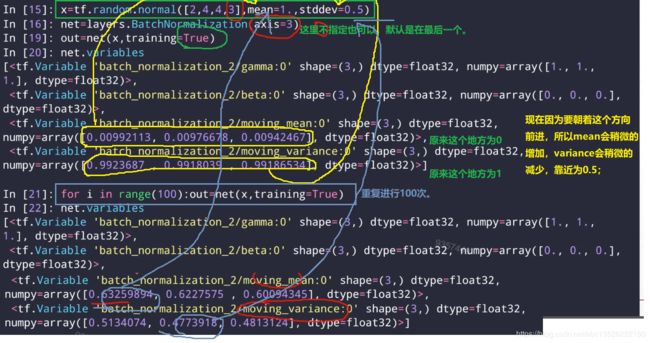
- 随便构建一个loss函数,简单体验一下。

这里有一个注意的问题为什么可视化的结果假如BN,分布不是N(0,1),这是因为有一个gamma和beta参数调整。
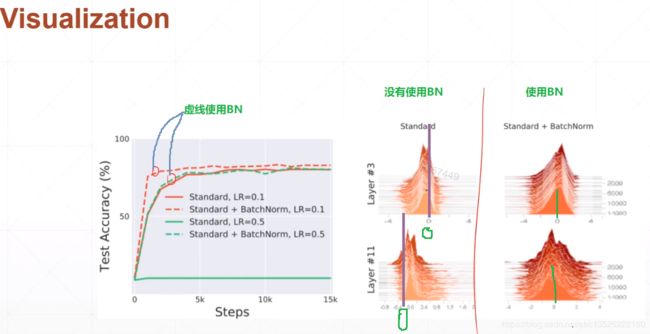
6.4、使用BN层好处
- 收敛速度更快了:因为不再处于sigmoid函数的饱和区,梯度信息更大了。
- 更加搜索到一个最优解;
- 最重要的变得更加稳定了,更强的鲁棒性。比如之前没有使用BN,learning rate随意一变就会不收敛,梯度消失之类的。
七、需要全套课程视频+PPT+代码资源可以私聊我!
- 方式1:CSDN私信我!
- 方式2:QQ邮箱:[email protected]或者直接加我QQ!
参考文章
这里主要参考了以下博客,表示衷心的感谢!
- 深度学习卷积神经网络——经典网络GoogLeNet(Inception V3)网络的搭建与实现
- inception-v1,v2,v3,v4----论文笔记
- 第6章视觉分类任务LeNet5,AlexNet,ZFNet,VGG,GoogleNet,ResNet,ResNeXt,SENet,DeepCompression,MobileNet!