学习Python爬虫(二):urllib库之parse模块、request模块
本文基于Python3.x,这里urllib.request模块对应Python2.x的request模块
概述
在Python2.x中,有urllib和urllib2两个模块,但是到了Python3.x,把它们整合到了一个模块中,都称之为urllib
parse的英文意思是『句法分析』,可见它的作用就是用来解析传进来饿的URL地址,并输出相应的信息——它是不需要联网的
request意味着『请求』,请求网络资源——这是要联网后才能办到的
HTTP协议介绍
HTTP,Hypertext Transfer Protocol,超文本传输协议
HTTP协议时一个基于『请求与相应』模式的(Request and Responce模式)、无状态(两次请求之间没有任何关联)的应用层协议
HTTP协议采用URL作为定位网络资源的标识
URL格式:http://host[:port][path]
host:合法的Internet主机域名或IP地址;port:端口号,缺省端口为0;path:请求资源的路径
举个栗子
http://www.baidu.com
http://220.181.111.188/somethingHTTP协议对资源的操作
GET:请求获取URL位置的资源(最常用)
HEAD:请求获取URL位置资源的相应消息报告,即获得该资源的头部信息
POST:请求向URL位置资源后附加的新资源
PUT:请求向URL位置存储一个资源,覆盖原URL位置的资源
PATCH:请求局部更新URL位置的资源,即改变该处资源的部分内容
DELETE:请求删除URL位置存储的的资源以上就是HTTP协议对网络资源的操作,一共五种,分别对应Requests库提供的五种方法(不急,下一章就讲Requests库的使用,现在知道这么回事就行了)
parse模块
导入模块
from urllib import parse常用方法列举如下
注:1. 所有实例均使用豆瓣首页进行测试,2. 所有实例均假设已经导入urllib.parse模块
1)urlparse:将url拆分为六个部分
urlparse(url, scheme='', allow_fragments=True)
2)urlsplit:功能类似urlparse,将url拆分为五个部分(少了params)
urlsplit(url, scheme='', allow_fragments=True)
3)urlunparse:urlparse的逆过程

4)urlunsplit:unrsplit的逆过程

5)quote:对url编码(也可以用于普通字符串)
quote(string, safe='/', encoding=None, errors=None)第二个参数是不会解析的内容(默认不会解析斜线)
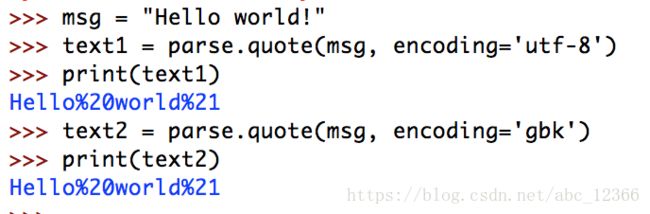
6)unquote:对url解码(也可以用于普通字符串)
为什么要解码?原因就是在url中不允许出现的字符(比如空格、斜线、汉字等)都会用%xxxx的形式代替,所以要用unquote函数进行解码还原

7)urlencode:把传入的参数对转换为url标准格式
urlencode(query, doseq=False, safe='', encoding=None, errors=None)它允许两种形式接受参数
[(key1, value1), (key2, value2),...]{'key1': 'value1', 'key2': 'value2',...}返回格式如下(字符串)
key2=value2&key1=value18)urljoin:用于拼接url
urljoin(base, url, allow_fragments=True)request模块
request就是请求网络资源,所以必须在联网后进行操作
这个模块蛮重要的,涉及方面有urlopen(打开一个网页)、代理、认证、cookie、缓存等……
1)urlopen:打开一个网页
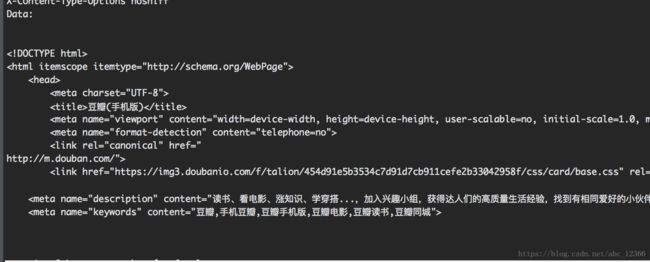
打开一个网页并返回一个类似文件的对象,该对象中包含该打开url的一些信息
对于返回的对象,可以用read()方法读取全部内容,也可以用readline()读取一行,可以用close()方法关闭
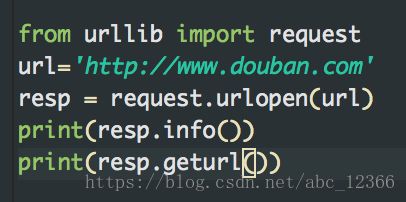
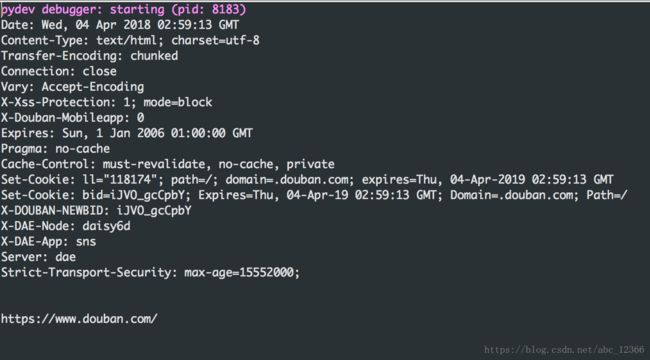
使用geturl()可以获得当前的url(这对于一些重定向网页很重要)
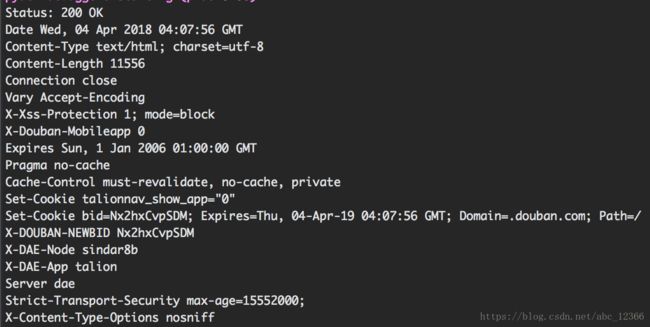
info()方法用来获取相关的头部信息(也可以用headers()获取)
演示一


演示二
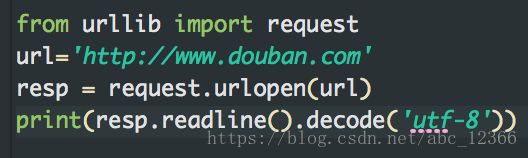

演示三


这样输出的话和直接read()相比没有缩进
演示四
模拟浏览器请求(简单版)
既然是模拟浏览器,基本上就逃不掉要联网,自然想到urllib.request库
1)HTTP请求

其中,『GET』、『POST』请求用的最多
2)urllib.request.Request类
如果基本的操作满足不了需求,比如处理打开一个网页还要在请求中加入headers请求头什么的,这就要借助urllib.request.Request类
requ = urllib.request.Request(url, data, headers, method)
resp = urllib.request.urlopen(requ) #用Request类构造一个完整的请求,增加了headers等一些信息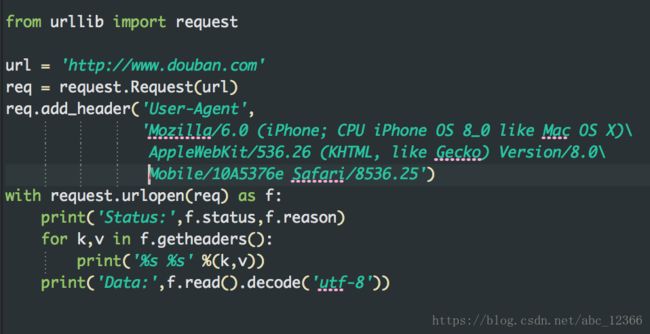
下一章讲解如何实现更高级的浏览器行为模拟(包括UA设置、IP代理、cookie……)