spring-data-jpa使用,方便却又不方便的ORM框架
-
- 前言
- 配置
- pom.xml配置
- applicatioin.yml配置数据库及jpa(文件格式使用yml)
- 扫描包配置
- 核心概念
- 流程
- 默认实现
- 继承CrudRepository接口
- 可以直接使用CrudRepository接口的默认方法
- 自定义SQL查询
- 1.声明一个继承与Repository或者它的子接口的接口,并且设定类型参数,如下:
- 2.声明查询的方法在接口上
- 默认实现
- 分页查询
- 自定义方法中的分页实现
- 默认分页实现
- @Query定义查询sql
- @Query定义更新sql
- 生成查询方法选择策略
- 总结
前言
JPA(Java Persistence API)缩写,JPA是一套规范,不是一套产品。可以把hiberate理解为JPA的规范实现。
我想它和你们心里想的不一样。JPA是从java bean创建数据库表和对象的规范,而不是你想的从数据库表到java bean的框架,如mybatis。我们可以使用JPA实现根据java里的bean对象创建表以及列。
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展。
我觉得JPA好是好,但sql语句不受我们控制,而这个缺点正好是它的优点。
个人认为使用面不是很广,因为中国国情在那里,mybatis是最受欢迎的ORM框架。而且大部分公司都自己的实现从数据库导出xml和pojo类的工具,其实也不会费多少事。
当然大部分程序员是无法选择使用什么框架的,所以你自己决定学不学,哈哈。
配置
pom.xml配置
//引入spring boot启动模块
<dependency
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
dependency>
//引入驱动
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>applicatioin.yml配置数据库及jpa(文件格式使用yml)
spring:
# 数据库配置
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: root
url: jdbc:mysql://localhost:3306/kelaien?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&useSSL=true
# 使用druid数据源
type: com.alibaba.druid.pool.DruidDataSource
# 配置初始化大小、最小、最大
maxActive: 20
initialSize: 5
minIdle: 5
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
validationQuery: select 'x'
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# JPA配置
jpa:
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
database: MYSQL
hibernate:
ddl-auto: update
naming:
strategy: org.hibernate.cfg.ImprovedNamingStrategy
show-sql: true
properties:
hibernate.format_sql: true配置解读
datasource配置就不做解释,很容易看懂,着重介绍jpa配置。
spring.jpa.show-sql:是否在日志里打印出sql语句,默认为false
spring.jpa.database-platform:hibernate方言。mysql数据库使用org.hibernate.dialect.MySQL5InnoDBDialect。
spring.jpa.hibernate.hbm2ddl.auto:指定ddl语句的形式,自动根据实体创建表。有如下4个属性可配置
create—-每次运行该程序,没有表格会新建表格,表内有数据会清空create-drop—-每次程序结束的时候会清空表update—-每次运行程序,没有表格会新建表格,表内有数据不会清空,只会更新validate—-运行程序会校验数据与数据库的字段类型是否相同,不同会报错
jpa.hibernate.naming.strategy:建表的命名规则,生成的数据库字段名带有下划线分隔
spring.properties.hibernate.format_sql:是否格式化生成的sql语句,默认为false。
扫描包配置
引入jpa命令空间http://www.springframework.org/schema/data/jpa,设置扫描路径。全部如下
<beans:beans xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jpa="http://www.springframework.org/schema/data/jpa"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/jpa
http://www.springframework.org/schema/data/jpa/spring-jpa.xsd">
<jpa:repositories base-package="com.acme.repositories" />
beans>配置完成之后,spring会扫描指定包下的所有继承自Repository接口和Repository子接口的类,自动创建Repository实体bean,每个注册的Bean的名称都是源于接口名称,例如:UserRepository将会被注册为userRepository。base-package允许使用通配符作为扫描格式。
但是,如果和spring boot结合使用,这个扫描包配置就不需要了,因为它使用“实体扫描”,默认情况下主配置 @EnableAutoConfiguration 或 @SpringBootApplication 下面的所有包都将会被扫描。任何使用注解 @Entity, @Embeddable 或 @MappedSuperclass 的类都将被管理。
核心概念
先了解一下spring data-jpa的核心概念
主要来看看Spring Data JPA提供的接口类,也是Spring Data JPA的核心概念:
Repository:最顶层的接口,是一个空的接口,目的是为了统一所有Repository的类型,且能让组件扫描的时候自动识别。RepositoryCrudRepository:是Repository的子接口,提供CRUD的功能,有哪些接口看API,默认是很简单的CRUD操作。PagingAndSortingRepository:是CrudRepository的子接口,添加分页和排序的功能,很少使用。JpaRepository:是PagingAndSortingRepository的子接口,增加了一些实用的功能,比如:批量操作等。如果有分页操作,一般继承这个类。JpaSpecificationExecutor:用来做负责查询的接口Specification:是Spring Data JPA提供的一个查询规范,要做复杂的查询,只需围绕这个规范来设置查询条件即可
流程
查询也分为两种,一种是spring data默认已经实现,一种是根据查询的方法来自动解析成SQL。
默认实现
继承CrudRepository接口
public interface PersonRepository extends CrudRepository<User, Long> { … }可以直接使用CrudRepository接口的默认方法
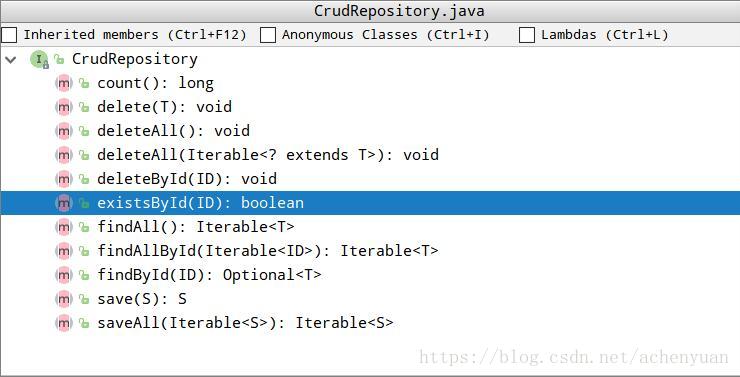
自定义SQL查询
1.声明一个继承与Repository或者它的子接口的接口,并且设定类型参数,如下:
public interface PersonRepository extends Repository<User, Long> { … }2.声明查询的方法在接口上
List findByLastname(String lastname); 不需要实现该接口。就可以直接使用。
自定义的简单查询就是根据方法名来自动生成SQL,主要的语法是findXXBy,readAXXBy,queryXXBy,countXXBy, getXXBy后面跟属性名称。
支持的关键字表如下
| 关键字 | 例子 | JPQL 片段 |
|---|---|---|
| And | findByLastnameAndFirstname | … where x.lastname = ?1 and x.firstname = ?2 |
| Or | findByLastnameOrFirstname | … where x.lastname = ?1 or x.firstname = ?2 |
| Between | findByStartDateBetween | … where x.startDate between 1? and ?2 |
| LessThan | findByAgeLessThan | … where x.age < ?1 |
| GreaterThan | findByAgeGreaterThan | … where x.age > ?1 |
| After | findByStartDateAfter … where x.startDate > ?1 | |
| Before | findByStartDateBefore | … where x.startDate < ?1 |
| IsNull | findByAgeIsNull | … where x.age is null |
| IsNotNull,NotNull | findByAge(Is)NotNull | … where x.age not null |
| Like | findByFirstnameLike | … where x.firstname like ?1 |
| NotLike | findByFirstnameNotLike | … where x.firstname not like ?1 |
| StartingWith | findByFirstnameStartingWith | … where x.firstname like ?1(parameter bound with appended %) |
| EndingWith | findByFirstnameEndingWith | … where x.firstname like ?1(parameter bound with prepended %) |
| Containing | findByFirstnameContaining | … where x.firstname like ?1(parameter bound wrapped in %) |
| OrderBy | findByAgeOrderByLastnameDesc | … where x.age = ?1 order by x.lastname desc |
| Not | findByLastnameNot | … where x.lastname <> ?1 |
| In | findByAgeIn(Collection ages) | … where x.age in ?1 |
| NotIn | findByAgeNotIn(Collection age) | … where x.age not in ?1 |
| True | findByActiveTrue() | … where x.active = true |
| False | findByActiveFalse() | … where x.active = false |
上面2种是常见的使用方式,理解上面的内容看别人写代码基本没问题。再结合spring-boot使用的话,配置也能少一些。基本上大部分程序员都会止步于吃透别人写的框架,只有少部分人是架构师级别。
分页查询
建议继承JpaRepository接口。在查询的方法中,需要传入参数Pageable
,它是分页参数,指定起始页和页长。当查询中有多个参数的时候Pageable建议做为最后一个参数传入
自定义方法中的分页实现
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value = "SELECT * FROM USERS WHERE LASTNAME = ?1")
Page findByLastname(String lastname, Pageable pageable);
} 继承JpaRepository接口。使用@Query定义sqj语句。pageable是我们需要传入的分页参数。返回的数据放在Page里。
调用方式
Sort sort = new Sort(Direction.DESC, "id");
Pageable pageable = new PageRequest(page, size, sort);
userRepository.findByLastname("cy", pageable);sort是排序对象,指定了排序规则和排序字段是id,当然sort也可以不传。
不使用@Query的情况下也可以。sql语句由spring-data-jpa按方法名命令规则生成。如下
public interface UserRepository extends JpaRepository<User, Long> {
Page findByLastname(String lastname, Pageable pageable);
} 默认分页实现
jpa已经实现的分页接口,适用于简单的分页查询。api如下
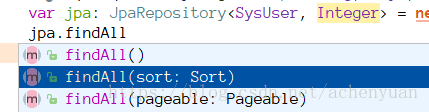
使用findAll(Pageable pageable)和findAll(Sort sort)实现分页和排序。缺点是没有查询条件。
调用方式
Sort sort = new Sort(Direction.DESC, "id");
Pageable pageable = new PageRequest(page, size, sort);
userRepository.findAll(pageable);@Query定义查询sql
例如
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.emailAddress = :emailAddress")
User findByEmailAddress(String emailAddress);
}LIKE查询
public interface UserRepository extends JpaRepository<User, Long> {
@Query("select u from User u where u.firstname like %?1")
List findByFirstnameEndsWith(String firstname);
} JPA提供两种方式设置查询参数:一种是使用名称标识参数(以:开头,后面紧跟参数名,参数名不区分大小写);另一种是使用位置标识参数(以?开头,随后紧跟整数,表示参数的位置)
如果需要修改参数名,可以使用@Param来注释到指定的参数上。
例如
public interface UserRepository extends JpaRepository<User, Long> {
@Query(value="select u from User u where u.firstname = :firstname or u.lastname = :lastname")
User findByLastnameOrFirstname(@Param("lastname") String lastname,
@Param("firstname") String firstname);
}如果Param注解命名的参数名与参数一样,可以省略@Param注解。
@Query定义更新sql
一般删除和增加数据库的动作使用默认的或简单按方法名创建即可,但更新是稍微复杂一点,因为更新可以更新不同的字段,根据条件选择更新的条目等。
update语句的实现,我们只需要在加多一个注解@Modify。
@Modifying
@Query(value="update User u set u.firstname = ?1 where u.lastname = ?2")
int setFixedFirstnameFor(String firstname, String lastname);我们就可以有update来代替select操作。
当我们发起update操作后,可能会有一些过期的数据产生,我们不需要自动去清除它们,因为EntityManager会有效的丢掉那些未提交的变更,如果你想EntityManager自动清除,那么你可以在@Modify上添加clearAutomatically属性(true)。即@Modifying(clearAutomatically=true)
生成查询方法选择策略
SpringData通过方法名有两种方式去解析出用户的查询意图
- 是直接通过方法的命名规则去解析
- 通过Query去解析
那么当同时存在几种方式时,SpringData怎么去选择这两种方式呢?
你可以通过配置的query-lookup-strategy属性来决定
- CREATE:通过解析方法名字来创建查询。这个策略是删除方法中固定的前缀,然后再来解析其余的部分。
- USE_DECLARED_QUERY:它会根据已经定义好的语句去查询,如果找不到,则会抛出异常信息。这个语句可以在某个注解或者方法上定义。根据给定的规范来查找可用选项,如果在方法被调用时没有找到定义的查
询,那么会抛出异常。
-CREATE_IF_NOT_FOUND:默认策略,会优先查询是否有定义好的查询语句,如果没有,就根据方法的名字去构建查询。
总结
综上所述,spring-data-jpa更多的关注业务,dao层默认创建了CRUD操作,不够的可以按指定规则命自定义操作。当然优点是不用写实现类,缺点也很明显,sql语句灵活度不多。