【超详细】最新VirtualBox+CentOS7+Hadoop2.8.5手把手搭建完全分布式Hadoop集群(从小白逐步进阶)
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/adamlinsfz/article/details/84333389
在前一篇文章中我们已经了解了如何在Virtual Box中安装CentOS的Linux系统,并且实现各虚拟机的互通及与宿主机和外网的互通。如果没有配置完成,请先完成这个步骤。详见:Windows下安装Virtual Box后安装CentOS7并设置双网卡实现宿主机与虚拟机互相访问
所需软件:
Virtual Box 5.2.22
CentOS-7-x86_64-Everything-1804
Hadoop2.8.5
JDK1.8.1_191
安装Virtual Box及Centos7的环境并且调通网络环境
参考前一篇文章:Windows下安装Virtual Box后安装CentOS7并设置双网卡实现宿主机与虚拟机互相访问
Hadoop集群设计思路
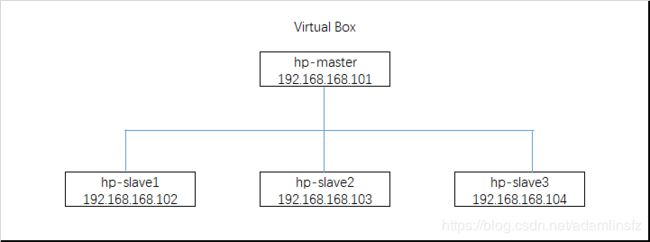
注意:以下操作分为在Master环境上(hp-master)操作及在Slave环境上(hp-slave1, hp-slave2, hp-slave3)操作。请注意区别。
首先,先在Master环境上操作。
启动Master,可以用"无界面启动”
通过Xshell连接并登陆Master环境。
第一步:配置JDK环境
A. 下载JDK JDK1.8.1_191
B. 通过Xftp传输到hp-master下的 /opt/目录里
C. 解压jdk文件
tar -zxvf jdk-8u191-linux-x64.tar.gz
解压完成后多出一个jdk1.8.0_191的文件夹
![]()
在/usr/里创建文件夹/java/。(注:关于为什么要将JDK安装在/usr/java/文件中,请参考我的文章: Linux CentOS环境下软件到底安装在哪里?/opt or /usr or /usr/local)
mkdir /usr/java
将解压的文件夹移动到该文件夹中
mv /opt/jdk1.8.0_191 /usr/java
D. 配置Java环境
进入系统 环境参数配置文件
vi /etc/profile
在合适的地方写入下面的环境配置参数后,按Esc,:wq保存退出。*对vi操作不熟悉的可以去看一下Linux Vi使用方法。
JAVA_HOME=/usr/java/jdk1.8.0_191
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
之后重新应用系统环境变量
source /etc/profile
成功后检查是否环境配置成功
java -version
出现下面截图内容时,说明配置成功。

第二步:在另外的三台Slave机器上(hp-slave1,hp-slave2,hp-slave3)重复第一步的操作,都配置好Java环境
*此处是因为已经把三台机器的连通性及IP都配置好了,所以需要在三台机器上做三次。如果熟练的话,仅需要做好Master,之后直接用Virtual Box的复制功能复制三份虚拟机后,修改一下每个机器的ip地址,也是一样的。
第三步:修改机器名称
如果不希望每次都是使用ip地址来进行操作,更好的方式是给每个机器命名。
A. 首先我们查看一下当前虚拟机的名称
hostname
B. 查看后,按照我们在集群设计思路中的要求,对机器名称进行变更。
首先,我们在Master上进行变更,更新为hp-master
hostnamectl set-hostname hp-master
之后,分别在每台Slave机器上进行修改
hostnamectl set-hostname hp-slave1
hostnamectl set-hostname hp-slave2
hostnamectl set-hostname hp-slave3
第四步:修改机器Hosts
在hp-master上修改/etc/hosts文件
vi /etc/hosts
在文件中加入下面的配置
192.168.168.101 hp-master
192.168.168.102 hp-slave1
192.168.168.103 hp-slave2
192.168.168.104 hp-slave3
修改后如下图

之后在每台Slave机器上进行修改hosts信息。
测试一下是否从hp-master上可以ping通过机器名连通每个机器,Ping成功后即可进入下一步
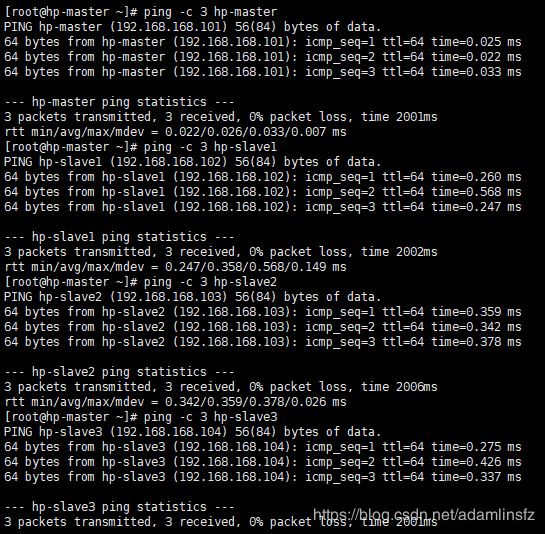
第五步:配置SSH免密码登录
首先,在hp-master上进行如下操作。
A. 防火墙的设置
关闭防火墙
systemctl disable firewalld.service
检查防火墙状态
systemctl status firewalld.service
B. 生成加密密钥
用rsa算法产生公钥和私钥,并生成.ssh目录,过程中会提是确认信息,一路回车完成。
ssh-keygen -t rsa
通过命令进入/root/.ssh/目录查看已经有两个文件生成了(id_rsa 和id_rsa.pub)。
cd /root/.ssh/
其次,在hp-slave1,hp-slave2,hp-slave3上重复A和B的操作,使得每台机器都生成ssh的密钥。
之后,我们从hp-master上创建一个通用的公钥authorized_keys,并将这个公钥发送给每个Slave机器,且hp-master向各机器之间互信公钥,免密访问。
C. 在hp-master上创建公钥authorized_keys
cat id_rsa.pub >> authorized_keys
回车后使用ls命令查看/root/.ssh/目录,发现多了一个文件。通过vi查看该文件,发现其内容与id_rsa.pub一样。
D. 修改authorized_keys的权限
chmod 644 authorized_keys
重启sshd的服务
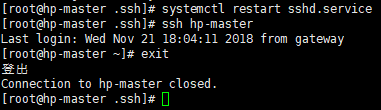
systemctl restart sshd.service
试一下通过ssh链接hp-master当前主机,已经不需要登陆密码了。
ssh hp-master
E. 同步密钥到各Slave机器中
scp /root/.ssh/authorized_keys hp-slave1:/root/.ssh
scp /root/.ssh/authorized_keys hp-slave2:/root/.ssh
scp /root/.ssh/authorized_keys hp-slave3:/root/.ssh
每一个步骤在第一次的时候可能需要各Slave机器的root登陆密码,输入即可。只有即可实现从hp-master向各Slave机器的ssh免密连通,如下图。
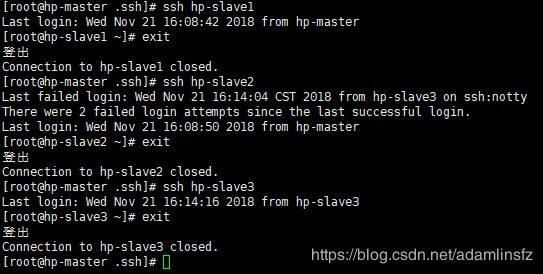
F. 实现各机器的互通(此步骤可以不做)
心血来潮,既然使用hp-master对各Slave进行ssh的免密连通,这个是单向的。那么各Slave之间和他们与Master是不是也可以呢?当然,有两个方式。方式一是通过命令完成,方式二需要工具完成。
方式一:
当我们从hp-master上把authorized_keys传给hp-slave1之后,在hp-slave1上也输入
cat id_rsa.pub >> authorized_keys
chmod 644 authorized_keys
之后,在hp-slave1上打开authorized_keys,会发现里面多了一份hp-slave1的id_rsa.pub的公钥。
同理,将这个文件继续发送给hp-slave2,也执行上述命令。同理,发给hp-slave3,也执行上述命令。
最后,再将hp-slave3做完后的authorized_keys再回传给hp-master,hp-slave1,hp-slave2.
scp /root/.ssh/authorized_keys hp-slave1:/root/.ssh
scp /root/.ssh/authorized_keys hp-slave2:/root/.ssh
scp /root/.ssh/authorized_keys hp-master:/root/.ssh
至此,各机器之前的互通就完成了。
第六步:Hadoop环境配置
A. 下载并传输文件到hp-master的opt目录下
B. 解压文件
在opt目录下生成一个hadoop的文件夹
tar -xvf hadoop-2.8.5.tar.gz
C. 为hadoop创建一个目录
我这里创建在/usr/local/下,并将刚才解压的文件夹移动到这里
mkdir /usr/local/hadoop
mv /opt/hadoop-2.8.5 /usr/local/hadoop
D. 为hadoop进行系统的环境参数配置
在hp-master上先进行环境变量的配置
vi /etc/profile
进入系统环境变量配置后,在之前JDK配置的后面,新增下面的配置。
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.8.5
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
保存退出后,重新应用环境变量
source /etc/profile
E. 为hadoop进行应用的环境参数配置
首先进入hadoop的配置文件夹
cd /usr/local/hadoop/hadoop-2.8.5/etc/hadoop/
编辑 hadoop-env.sh
vi hadoop-env.sh
在配置文件最后加上
export JAVA_HOME=/usr/java/jdk1.8.0_191
编辑 yarn-env.sh
vi yarn-env.sh
在配置文件最后加上
export JAVA_HOME=/usr/java/jdk1.8.0_191
F. 对Hadoop里的配置文件进行修改。
修改core-site.xml
fs.default.name
hdfs://hp-master:9000
hadoop.tmp.dir
/usr/local/hadoop/tmp
fs.checkpoint.period
3600
修改hdfs-site.xml
dfs.replication
2
dfs.namenode.name.dir
file:/usr/local/hadoop/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/dfs/data
修改mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hp-master:10020
mapreduce.jobhistory.webapp.address
hp-master:19888
mapred.job.tracker
hp-master:9001
修改yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hp-master
yarn.log-aggregation-enable
true
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.address
hp-master:8032
yarn.resourcemanager.scheduler.address
hp-master:8030
yarn.resourcemanager.resource-tracker.address
hp-master:8031
yarn.resourcemanager.admin.address
hp-master:8033
yarn.resourcemanager.webapp.address
hp-master:8088
修改slaves文件
vi slaves
清空里面的内容,并填入下面的配置
hp-slave1
hp-slave2
hp-slave3
G. 从hp-master上将hadoop分发到各个Slave节点
scp -r /usr/local/hadoop hp-slave1:/usr/local/hadoop
scp -r /usr/local/hadoop hp-slave2:/usr/local/hadoop
scp -r /usr/local/hadoop hp-slave3:/usr/local/hadoop
H. 验证hadoop配置
在hp-master上进行查看
hadoop version
出现下面的内容,说明配置成功了。 
第七步:启动hadoop
hadoop分布式里有namenood和datanood的区分,在之前的参数配置中有配置namenood就是我们的hp-master虚拟机。所以我们在hp-master进行操作即可启动集群。
A. 对hp-master的hadoop进行初始化
首先进入hadoop的bin目录下
cd /usr/local/hadoop/hadoop-2.8.5/bin
执行namenood的初始化命令
./hadoop namenode -format
命令需要执行几秒钟,之后看到有提示“Exiting with status 0”就是成功初始化了。
B. 在namenode上执行启动命令
首先进入hadoop的sbin目录下
cd /usr/local/hadoop/hadoop-2.8.5/sbin
执行namenood的启动命令
./start-all.sh
第一次操作时,会提示需要确认,输入yes确认即可。
如果需要停止namenood,则输入
./stop-all.sh
C. 访问Hadoop
因为我们安装的hadoop里的namenode是hp-master,对应的ip是192.168.168.101,所以我们在宿主机的浏览器里访问下面的地址
http://192.168.168.101:50070/
当你看到下面的页面时,说明已经进入hadoop的管理
在datanode里可以看到4个node(1个namenode,3个datanode已经启动了)
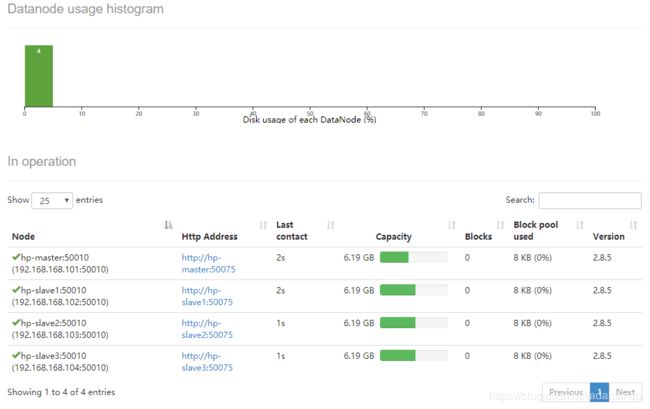
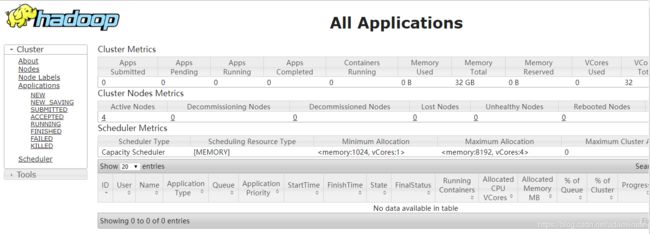
查看ResourceManager状况
http://192.168.168.101:8088/
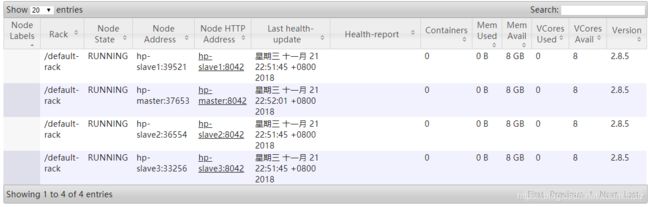
到这里hadoop的集群环境就已经搭建好了!