Learning Dynamic Siamese Network for Visual Object Tracking 阅读笔记
前言
预读文章:Fully-Convolutional Siamese Networks for Object Tracking (SiameseTracker)。
在深度学习做目标跟踪效果好的算法中,这篇文章算是有点难度的了~~~啃了一上午算是啃明白了点~
本博客将采用一边半翻译一边详细解说并抒发自己看法的方式介绍这篇文章。
摘要
1,第一句话就指出本文算法的特点:学习目标的外观变化,排除背景的干扰,可以实时的跟踪方法。
在后续介绍中会发现,本文的三个贡献恰恰对应本文摘要第一句话中作者所提出的上述三点。
2,咦?要达到上述要求,SiameseTracker是一个不错的基础框架。
作者指出,之所以SiameseTracker在性能上与当前最好的算法有很大差距,主要是因为他不更新啊~~~
因此,本文的出发点,也就是Motivation就来了,所以本文是一个在SiameseTracker上添加更新手段的文章。
3,本文提出了适合于目标跟踪问题的动态Siamese网络,通过fast transformation learning model(后面会介绍这是什么玩意,其实就是一个优化问题而已)技术去学习目标的变化和背景的抑制(划重点!学习背景抑制,很少听到吧~)。
4,本文的算法可以在视频序列上进行训练~(这个特点不错,但是想想就好麻烦的样子)。
5,实验在OTB2013上和VOT2015上进行(呵呵~没在OTB2015上做实验,是个内行都能猜到为啥~)。
介绍
1,先看文章中的一张图,解读一下:
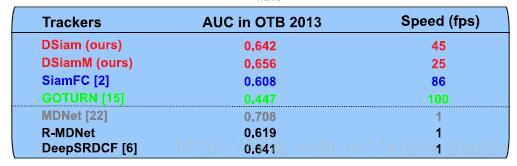
这个图有什么好说的呢?不就是和其他算法对比一下在OTB2013上的性能吗?我认为看点在于R-MDNet,作者真是煞费苦心啊,为了说明MDNet在ILSVRC上训练后效果不好,作者亲自拿MDNet在ILSVRC上训练后在OTB2013上测试,结果相比原文下降了9个点,我还能说什么呢?你这让我这个解说很被动啊!我们知道,在带有玄学色彩的机器学习问题中,调参数很重要啊~作者就简单的给MDNet换个训练集,然后测试,一套完美无障碍的操作,试问:您精心调整MDNet的参数了吗?换了个数据集不需要换超参数吗?从我个人观点来说,我从来都反对那别人的算法代码随便改改就在自己文章中报告别人改动后的效果,这简直是太厉(无)害(耻)了~你自己的算法煞费苦心调参数,别人的你就随便弄弄,然后你说你比别人效果好???Interesting…
2,作者指出现在的深度学习解决目标跟踪有两种思路:
(1)、基于经典更新的思想在线更新网络,但是大多数这类算法的速度都很慢,大概在1~2fps;(这个很讲道理,我感觉其实MDNet的速度可能还不到1fps,四舍五入后1fps还差不多)
(2)、基于匹配的跟踪方法,也就是SiameseTracker和GOTURN系列,这类方法不需要在线更新,所以特点是速度快,但是跟踪问题就目前来看,不更新是不可能获得很高的性能的,因为你不能捕捉到目标和背景的变化嘛~(举个最简单的例子,就算是一个人跟踪我,我一开始穿了一身乞丐装,带个墨镜,配个杀马特发型,然后蒙上他的眼睛,我变成了葛优穿西装的形象,他肯定不认识我,但是他要是观看了我更换造型的过程,那他就能跟踪我了,这说明更新很重要);
3,本文作者,针对基于匹配的跟踪方法提出了有效的在线更新方法(确实6666666666),也就是本文的动态Siamese网络,网络的更新有两个目的:在线学习目标的变化和背景的抑制,更加666的是,为了让更新不过于影响跟踪器的速度,本文所提出的更新方式可以被FFT加速(FFT加速有多厉害,见过KCF的都知道),所以呢?本文就是效果好,速度快喽。
相关工作
1,这里简单复习一下SiameseTracker吧。
SiameseTracker核心公式: Stl=corr(fl(O1),fl(Zt)) S l t = corr ( f l ( O 1 ) , f l ( Z t ) ) ,其中 O1 O 1 是是第一帧的目标, Zt Z t 为第t帧的搜索域, fl(O1) f l ( O 1 ) 和 fl(Zt) f l ( Z t ) 分别代表提取目标和搜索域的特征, corrfl(∗,∗) corr f l ( ∗ , ∗ ) 代表相关操作, Stl S l t 代表进行相关操作后的相关度,其中最大值所在的位置即目标所在的位置。明白了吗?不明白我也没有办法了~
2,SINT也是一个SiameseTracker类的工作,而且性能还不错,但是作者批判这个算法速度太慢(因为其中使用了光流操作),大概1~2fps;
本文方法
1,本文核心公式(注意,对比着SiameseTracker核心公式看): Slt=corr(Vlt−1∗fl(O1),Wlt−1∗fl(Zt)) S t l = corr ( V t − 1 l ∗ f l ( O 1 ) , W t − 1 l ∗ f l ( Z t ) ) ,我凑~ Vlt−1 V t − 1 l 是什么? Wlt−1 W t − 1 l 又是什么?说白了, Vlt−1 V t − 1 l 是一个学习得到的更新因子,作用于 fl(O1) f l ( O 1 ) 后得到经过当前更新后目标模板, Wlt−1 W t − 1 l 也是一个变换因子,作用于 fl(Zt) f l ( Z t ) 后得到更适合当前的搜索模板(这个真的是脑洞大开啊,我感觉一般人想得到前面那个,想不到后面那个啊),通过两个更新因子,达到了在SiameseTracker中进行更新的目的,注意,这里不是更新网络参数,而是更新输入到网络里的模板哦。但是,如何学习得到 Vlt−1 V t − 1 l 和 Wlt−1 W t − 1 l 呢?得到得到 Vlt−1 V t − 1 l 和 Wlt−1 W t − 1 l 又依赖于什么规则呢?总不能随便两个矩阵就可以吧,所以,请往下看……
2,数学知识:正则化线性回归。这是个什么东西?非常简单,假设你有一个X和一个Y,你想使用W和X进行卷积来最小化而成近似Y,顺便给W加一个正则项,那么怎么求W呢?当然是最小化: R=argmin∥T∗X−Y∥2+λ∥T∥2 R = argmin ‖ T ∗ X − Y ‖ 2 + λ ‖ T ‖ 2 ,幸运的是,这个目标优化表达式在频域上是有闭式解的,而且是快速求解哦: R=ifft(fft∗(X)⊙fft(Y)fft∗(X)⊙fft(X)+λ) R = ifft ( fft ∗ ( X ) ⊙ fft ( Y ) fft ∗ ( X ) ⊙ fft ( X ) + λ ) ;
3, Vlt−1 V t − 1 l 的求解:原文公式

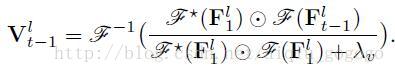 ,本文这里 Vlt−1 V t − 1 l 的求解仅仅依赖于上一帧的跟踪结果和第一帧目标,求解得到 Vlt−1 V t − 1 l 就可以带入到本文核心公式中去了,这里我不禁产生一个疑问:仅仅依靠第一帧和上一帧可靠吗?我们知道,基于更新的目标跟踪算法往往都是利用过去很多跟踪的结果,因为这样更能丰富目标的多样性,但是本文一直用第一帧,这样得到的结果鲁棒性强吗?有没有什么办法引入前面所有帧辅助当前更新呢?
,本文这里 Vlt−1 V t − 1 l 的求解仅仅依赖于上一帧的跟踪结果和第一帧目标,求解得到 Vlt−1 V t − 1 l 就可以带入到本文核心公式中去了,这里我不禁产生一个疑问:仅仅依靠第一帧和上一帧可靠吗?我们知道,基于更新的目标跟踪算法往往都是利用过去很多跟踪的结果,因为这样更能丰富目标的多样性,但是本文一直用第一帧,这样得到的结果鲁棒性强吗?有没有什么办法引入前面所有帧辅助当前更新呢?
4, Wlt−1 W t − 1 l 求解:为什么在本文方法1中我说 Vlt−1 V t − 1 l 是更新因子,而 Wlt−1 W t − 1 l 是变换因子?原因就在这里,因为 Wlt−1 W t − 1 l 的求解仅仅和上一帧有关系,和其他帧一毛钱关系都没有! Wlt−1 W t − 1 l 求解公式:

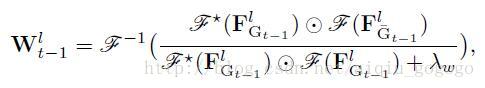 ,其中 Gt−1 G t − 1 是上一帧图片, G¯t−1 G ¯ t − 1 是对 Gt−1 G t − 1 以图片中心为中心增加了一个点乘高斯平滑,为什么这么做呢?因为考虑到中间是前景,两边是背景,背景更加重要呗~
,其中 Gt−1 G t − 1 是上一帧图片, G¯t−1 G ¯ t − 1 是对 Gt−1 G t − 1 以图片中心为中心增加了一个点乘高斯平滑,为什么这么做呢?因为考虑到中间是前景,两边是背景,背景更加重要呗~
4,多层特征融合:非本文关键看点,不介绍;
实验
1,训练集:ILSVC-2015(这个训练集在跟踪领域必火!);
2,实现效果:OTB2013精度:0.891,OTB2013AUC:0.686,速度:25fps,在这个速度下,这个实验效果很好了!
3,不想写了,手好累~
个人看法
本文工作思路清晰,目标明确,理论充分,从实验效果看在一定程度上解决了SiameseTracker中的问题,但是,我感觉与其说本文为SiameseTracker引入了更新方法,不如说引入了模板变换方法,至少通读全文会发现,本文的更新并不是我们所以版理解的更新,所以我认为还没有从根本上解决SiameseTracker的更新问题,这方面一定还会有更加完美的工作。