利用Python爬虫爬取网页福利图片
最近几天,学习了爬虫算法,通过参考书籍,写下自己简单爬虫项目:
爬取某福利网站的影片海报图片
环境:anaconda3.5+spyder3.2.6
目录
1.本节目标
2.准备工作
3.抓取分析
4.抓取首页
5.正则提取
6.下载图片
7.分页爬取
8.完整代码
1.本节目标
利用爬虫爬取http://www.xinxin103.top/L/lunlipian.html网站的海报照片,提取的图片最后保存在文件下。
2.准备工作
在本节开始之前,请确保已经正确安装好了 requests 库 。
3.抓取分析
我们需要抓取的网站首页是:http://www.xinxin103.top/L/lunlipian.html,打开后看到首页
将网页滚动到最下方,可以发现有分页的列表,直接点击第 2 页,观察页面的 URL 和内容发生了怎样的变化,如图所示 。
可以发现页面的 URL 变成 http://www.xinxin103.top/L/lunlipian2.html ,和之前的 URL 多了一个参数,那就是 将lunlipian2.html 换成了lunlipian2.html ,而每一页16个影片,初步推断这是一个偏移量的参数。
4.抓取首页
接下来用代码实现这个过程。 首先抓取第一页的内容。 我们实现了 get_one_page ()方法,并给它传入 url 参数。 然后将抓取的页面结果返回,再通过main()方法调用 。 初步代码实现如下 :
import requests
from requests.exceptions import RequestException
def get_one_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
try:
response = requests.get(url,headers=headers)
response.encoding = 'GBK'
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def main():
url = 'http://www.xinxin103.top/L/lunlipian1.html'
html = get_one_page(url)
print(html)
main()这样运行之后,就可以成功获取首页的源代码了 。 获取源代码后,就需要解析页面,提取出我们想要的信息 。
5.正则提取
接下来,回到网页看一下页面的真实源码。 在开发者模式下的 Network 监昕组件中查看源代码 。
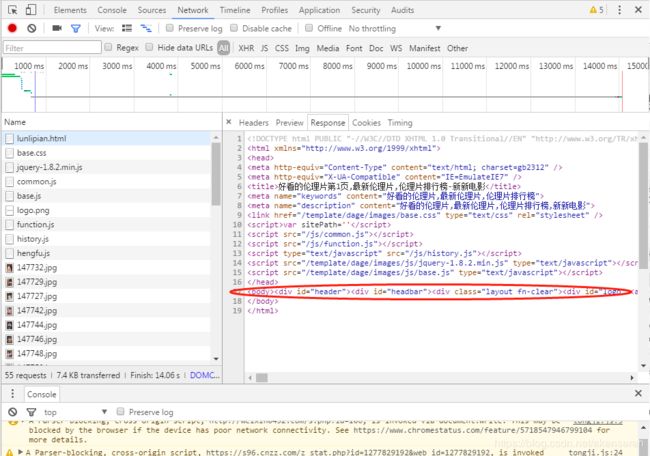
注意,这里不要在 Elements 选项卡中直接查看源码,因为那里的惊码可能经过 JavaScript 操作而与原始请求不同,而是需要从 Network 选项卡部分查看原始请求得到的惊码。其主要内容在
内,复制粘贴在在线HTML解析可以看到网页内部结构。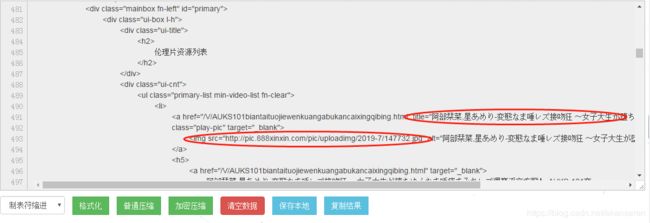
可以看到,一部电影信息对应的源代码是一个
'.*?title="(.*?)" class=.*?) '
' 接下来,通过调用 findall()方法提取出所有的内容。再接下来,我们再定义解析页面的方法 parse_one_page (),主要是通过正则表达式来从结果中提取我们想要的内容,我们再将匹配结果处理一下,遍历提取结果并生成字典,实现代码如下 :
def parse_one_page(html):
pattern = re.compile('.*?title="(.*?)" class=.*?', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'title': item[0],
'image': item[1]
} 
6.下载图片
随后,我们将提取的图片URL存入一个链表,之后通过遍历的方式获取所有图片。
def download(imgurls):
global j
file_path="D:/我的文档/pictures/AV/"
for imgurl in imgurls:
path=file_path+str(j)
#写入文件
with open(path+".jpg","wb") as f:
r=requests.get(imgurl)
f.write(r.content)
print("%s下载成功"%path)
j+=1
def main():
url = 'http://www.xinxin103.top/L/lunlipian.html'
html = get_one_page(url)
urls =[]
for content in parse_one_page(html):
print(content)
#print ("dict['Name']: ", content['image'])
urls.append(content['image'])
download(urls)到此为止,我们就完成了单页影片海报的提取。
7.分页爬取
此外,为了实现连续爬取多张网页的照片,这里还需要将 main ()方法修改一下,接收一个 offset 值作为偏移量,然后构造 URL 进行爬取。实现代码如下:
def main(offset):
url = 'http://www.xinxin103.top/L/lunlipian'+str(offset)+'.html'
html = get_one_page(url)
urls =[]
for content in parse_one_page(html):
print(content)
#print ("dict['Name']: ", content['image'])
urls.append(content['image'])
download(urls)
if __name__ == '__main__':
for i in range(5):
main(offset=i+2)
print("第{}页下载结束!".format(str(i+2)))8.完整代码
到此为止,我们的福利影片的爬虫就全部完成了,再稍微整理一下,完整的代码如下 :
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 28 22:15:20 2019
@author: Administrator
"""
import json
import requests
from requests.exceptions import RequestException
import re
import time
j=1
def get_one_page(url):
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
try:
response = requests.get(url,headers=headers)
response.encoding = 'GBK'
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('.*?title="(.*?)" class=.*?', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'title': item[0],
'image': item[1]
}
def download(imgurls):
global j
file_path="D:/我的文档/pictures/AV/"
for imgurl in imgurls:
path=file_path+str(j)
#写入文件
with open(path+".jpg","wb") as f:
r=requests.get(imgurl)
f.write(r.content)
print("%s下载成功"%path)
j+=1
def main(offset):
url = 'http://www.xinxin103.top/L/lunlipian'+str(offset)+'.html'
html = get_one_page(url)
urls =[]
for content in parse_one_page(html):
print(content)
#print ("dict['Name']: ", content['image'])
urls.append(content['image'])
download(urls)
if __name__ == '__main__':
for i in range(5):
main(offset=i+2)
print("第{}页下载结束!".format(str(i+2)))
接下里就是福利时间了。不要谢我,叫我雷锋。(手动滑稽)
参考:《Python 3网络爬虫开发实战》