Logstash吞吐量性能优化
Logstash性能优化:
场景:
部署节点配置极其牛逼(三台 48核 256G内存 万兆网卡的机器),ES性能未达到瓶颈,而filebeat又有源源不断的日志在推送(日志堆积),此时却发现ES吞吐量怎么也上不去,基本卡在单logstash 7000/s 的吞吐。
这时候我们基本确定瓶颈在logstash上。logstash部署在服务端,主要处理接收filebeat(部署在节点机)推送的日志,对其进行正则解析,并将结构化日志传送给ES存储。对于每一行日志进行正则解析,需要耗费极大的计算资源。而节点CPU负载恰巧又不高,这个时候我们就要想办法拓宽logstash的pipeline了,毕竟我们一天要收集18亿条日志。
ELFK部署架构图如下所示:
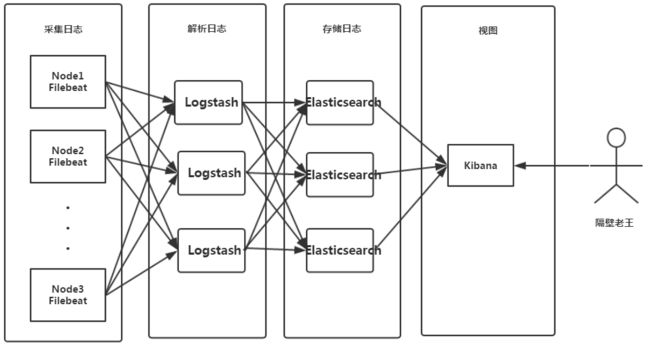
影响logstash性能因素如下:
logstash是一个pipeline,数据流从input进来,在filter进行正则解析,然后通过output传输给ES。
- filebeat->logstash tcp连接
- logstash->es tcp连接
- logstash input
- logstash filter
- logstash output
filebeat-> logstash tcp连接 (目前 非瓶颈)
- TCP连接数 :之前性能测试,3节点logstash可以承受1000节点filebeat的连接。
注:当时性能测试方案 1000节点filebeat推流极低,不确保线上日志大时,filebeat连接数增高成为瓶颈。 - 网络带宽: 万兆网卡支持,无性能瓶颈
logstash-> es tcp连接 (目前 非瓶颈)
- TCP连接数 :logstash后端仅与3个ES节点建立TCP连接,连接数无问题
- 网络带宽: 万兆网卡支持,无性能瓶颈。
logstash input (目前 非瓶颈)
- 接收filebeat推送日志,接收量由filter,output协同决定。
logstash filter & logstash output ( 瓶颈)
-
升级logstash版本 1.7 -> 2.2
2.2版本之后的logstash优化了input,filter,output的线程模型。 -
增大 filter和output worker 数量 通过启动参数配置 -w 48 (等于cpu核数)
logstash正则解析极其消耗计算资源,而我们的业务要求大量的正则解析,因此filter是我们的瓶颈。官方建议线程数设置大于核数,因为存在I/O等待。考虑到我们当前节点同时部署了ES节点,ES对CPU要求性极高,因此设置为等于核数。 -
增大 woker 的 batch_size 150 -> 3000 通过启动参数配置 -b 3000
batch_size 参数决定 logstash 每次调用ES bulk index API时传输的数据量,考虑到我们节点机256G内存,应该增大内存消耗换取更好的性能。 -
增大logstash 堆内存 1G -> 16G
logstash是将输入存储在内存之中,worker数量 * batch_size = n * heap (n 代表正比例系数)worker * batch_size / flush_size = ES bulk index api 调用次数
调优结果:
三节点 logstash 吞吐量 7000 -> 10000 (未达到logstash吞吐瓶颈,目前集群推送日志量冗余) logstash不处理任何解析,采用stdout输出方式,最高吞吐 11w/s
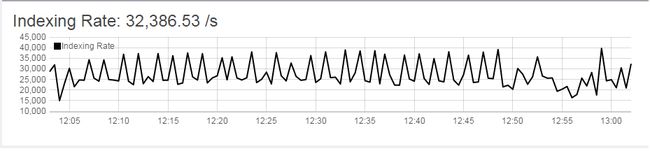
集群吞吐量 24000 -> 32000 (未饱和)
stop两个logstash节点后,单节点logstash吞吐峰值15000 (集群目前应该有 2w+ 的日质量,单节点采集1w5,所以为单节点峰值)
集群调优前: 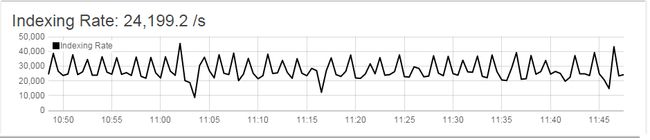
集群调优后:
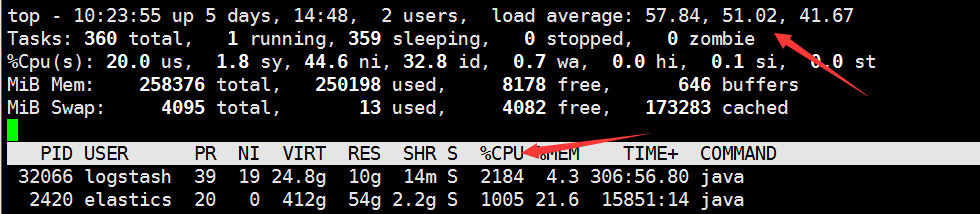
最后观察,系统负载也一下上去了
最后,总结一下调优步骤:
worker * batch_size / flush_size = ES bulk index api 调用次数
- 根据CPU核数调整合适的worker数量,观察系统负载。
- 根据内存堆大小,调整batch_size,调试JVM,观察GC,线程是否稳定。
- 调整flush_size,这个值默认500,我在生产环境使用的1500,这个值需要你逐步增大,观察性能,增大到一定程度时,性能会下降,那么那个峰值就是适合你的环境的。