简介
HBase是高可靠性,高性能,面向列,可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能处理成千上万的行和列所组成的大型数据。
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBASE利用HadoopHDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBASE同样利用Hadoop MapReduce来处理HBASE中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
行存储
优点:写入一次性,保持数据完整性
缺点:数据读取过程中产生冗余数据
列存储
优点:读取过程不产生冗余数据,特别适合对数据完整性不高的大数据领域
缺点:写入效率差,保证数据完整性方面差
与传统数据库对比
1.传统数据库遇到的问题
数据量很大时无法存储
没有良好的备份机制
数据达到一定数量开始缓慢,很大的话基本无法支撑
2.HBase的优势
线性扩展,随着数据量增加可以通过节点扩展进行支撑
数据存储在HDFS上,备份机制健全
通过zookeeper协调找数据,访问速度块
HBase 集群中的角色
Hbase一张表又一个或多个Hregion组成,记录之间按照行键的字典排序(每条数据也是按照顺序有序的进行排序,为了检索更快,更高效)
1,一个或多个主节点 Hmaster
监控RegionServer
处理RegionServer故障转移
处理元数据的变更
在空闲时间进行数据负载均衡
通过Zookeeper发布自己的位置给客户端
2.多个节点,HregionServer
负责存储HBase的实际数据
处理分配给它的Region
刷新缓存到HDFS
维护HLog
执行压缩
负责处理Region分片
基本原理
HBase 一种作为存储分布式文件系统,另一种作为数据处理模型的MR框架
HBase 内置有Zookeeper,但一般我们会有其他的Zookeeper集群来监管master和regionserver,Zookeeper通过选举,保证任何时候,集群中只有一个活跃的HMaster,HMaster与HRegionServer启动会向Zookeeper注册,存储所有HRegion 的寻址入口,实时监控HRegionserver的上线和下线信息,并实时通知给HMaster,存储HBase的schema和table元数据。默认情况下,HBase管理Zookeeper实例,Zookeeper的引入使得HMaster不再是单点故障,一般情况下会启动两个HMaster,非Active的HMaster会定期和Active HMaster通信以获取最新状态,从而保证它实时更新,如果启动多个HMaster反而会增加Active HMaster的负担。
一个RegionServer可以包含多个HRegion,每个RegionServer维护一个HLog,和多个HFile以及对应的MemStore.RegionServer运行在与DataNode上。数量可以与DateNode数量一致
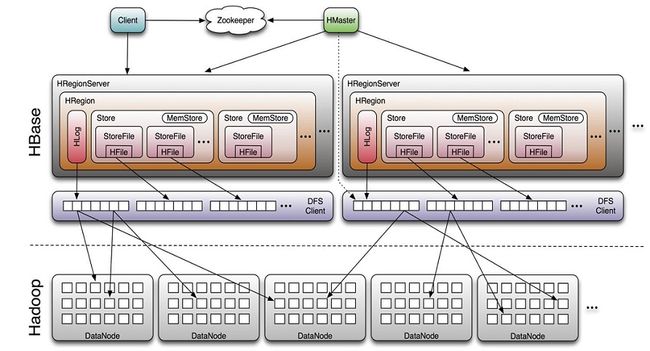
组件说明
Write-Ahead logs
HBase 的修改记录,当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做Write-Ahead logfile 的文件中,再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
StoreHFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族。
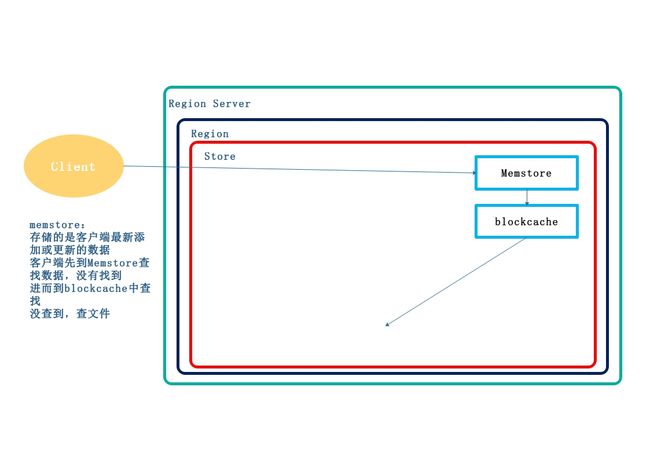
MemStore顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在 WAL 中之后,RegsionServer
会在内存中存储键值对。
RegionHbase 表的分片,HBase 表会根据 RowKey 值被切分成不同的region 存储在 RegionServer 中,在一个 RegionServer 中可以有多个不同的 region。
Hbase是按照行锁定,管理着不同的地区,RegionServer主要是管理着用户的读和写,这些数据是在HDFS存的
HRegion 相当于是对着地区一个封装
按照RoWky范围分的:region“Hregion”RegionServer
按照列簇(Columc Family)“多个HStore
HStor“memStore(写缓存)+ HFiles(均为有序的键值)
Hbase系统架构:
客户端:访问Hbase接口,维护缓存加速区域服务器访问
主负载均衡,分配Region到RegionServer
RegionServer维护区域负责区域的IO
Zookeeper 保证集群只有一个Master 存储所有Region(Root)入口地址,实时监控Region Server的上下线
HMaster功能(主):
负载均衡,管理和分配HRegion
DDL 增删改
类似NameNode管理一些元数据(table的结构元数据)
ACL权限控制
HRegionServer(从):
管理和存放本地的HRegion
读写HDFS,提供IO操作
本地化:HRegion的数据尽量和数据所属的DataNode在一块,但是这个本地化不能够总是满足和实现
HBase 安装部署
下载
http://hbase.apache.org/downloads.html
上传解压
[root@master HBase]# tar -zxvf hbase-1.4.6-bin.tar.gz
配置环境
#hbase-site.xml
# vim hbase-site.xml
##添加以下内容
hbase.rootdir
hdfs://master:9000/hbase
hbase.master.port
16000
hbase.cluster.distributed
true
hbase.zookeeper.quorum
master:2181,slave1:2181,slave2:2181
hbase.zookeeper.property.dataDir
/opt/apps/Zookeeper/data
[root@master conf]# vim hbase-env.sh
##添加以下内容
export JAVA_HOME=/opt/apps/Java/jdk1.8.0_172
export HBASE_HOME=/opt/apps/HBase/hbase-1.4.6
Extra Java CLASSPATH elements. Optional.
export HBASE_CLASSPATH=$CLASSPATH:$HBASE_HOME/lib
[root@master conf]# vim regionservers
##添加以下内容
slave1
slave2
master
解决Jar包问题
[root@master lib]# rm -rf hadoop-*
[root@master lib]# rm -rf zookeeper-3.4.10.jar
[root@master lib]# cp ./* /opt/apps/HBase/hbase-1.4.6/lib/
hadoop-annotations-2.7.6.jar
hadoop-auth-2.7.6.jar
hadoop-client-2.7.6.jar
hadoop-common-2.7.6.jar
hadoop-hdfs-2.7.6.jar
hadoop-mapreduce-client-app-2.7.6.jar
hadoop-mapreduce-client-common-2.7.6.jar
hadoop-mapreduce-client-core-2.7.6.jar
hadoop-mapreduce-client-jobclient-2.7.6.jar
hadoop-mapreduce-client-shuffle-2.7.6.jar
hadoop-yarn-api-2.7.6.jar
hadoop-yarn-client-2.7.6.jar
hadoop-yarn-common-2.7.6.jar
hadoop-yarn-server-common-2.7.6.jar
zookeeper-3.4.12.jar
在HBase中添加Hadoop的配置文件
## 通过软连接的方式创建
[root@master conf]# ln -s /opt/apps/Hadoop/hadoop-2.7.6/etc/hadoop/core-site.xml /opt/apps/H
Base/hbase-1.4.6/conf/core-site.xml
[root@master conf]# ln -s /opt/apps/Hadoop/hadoop-2.7.6/etc/hadoop/hdfs-site.xml /opt/apps/H
Base/hbase-1.4.6/conf/hdfs-site.xml
分发至各个节点
启动
start-hbase.sh
查看进程
[root@master apps]# jps
115106 Jps
99509 QuorumPeerMain
113333 HRegionServer
103769 ResourceManager
103419 NameNode
113196 HMaster
103615 SecondaryNameNode
通过http://master:16010 访问检查是否成功
命令炒作
#list 查看所有表
hbase(main):001:0> list
=> ["student", "teacher"]
#create 表名 列族 (可以多个 ,) 创建表
hbase(main):002:0> create 'test' ,'info','name'
#put 表名 key键 列族(名) 值 添加(修改)数据
hbase(main):006:0> put 'test','01','info:name' ,'zhangsan'
#scan 表名 查看表数据
hbase(main):006:0> put 'test','01','info:name' ,'zhangsan'
#describe 表名 查看表结构
hbase(main):008:0> describe 'test'
Table test is ENABLED
test
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COM
PRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'name', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COM
PRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.1810 seconds
#get 表名 列key值 获取一行数据内容
hbase(main):010:0> get 'test','01'
#查看 一定范围的行数据(按字节以字典顺序)
hbase(main):013:0> scan 'test',{STARTROW=>'01',STOPROW=>'03'}
ROW COLUMN+CELL
01 column=info:name, timestamp=1534852652080, value=zhangsan
02 column=info:name, timestamp=1534853260806, value=zhangsan
#统计表中多少条数据
hbase(main):014:0> count 'test'
#删除表中某个字段
hbase(main):016:0> delete 'test' ,'03','info:name'
# deleteall 删除表中一条数据
hbase(main):019:0> deleteall 'test','02'
# truncate 清除表中数据
hbase(main):021:0> truncate 'test'
#删除表
hbase(main):023:0> disable 'test'
hbase(main):026:0> drop 'test'
API操作
package com.zhiyou.HBase;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.Before;
import org.junit.Test;
public class HBaseOperate {
private Configuration conf = null;
//lianjie
@Before
public void connect() {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "master,slave1,slave2");
conf.set("hbase.zookeeper.property.clientPort", "2181");
}
/**
* 创建表
* @throws Exception
* @throws IOException
*/
@Test
public void createTable() throws Exception{
HBaseAdmin admin = new HBaseAdmin(conf);
HTableDescriptor desc = new HTableDescriptor(TableName.valueOf("teacher"));
desc.addFamily(new HColumnDescriptor("info"));
desc.addFamily(new HColumnDescriptor("zhicheng"));
admin.createTable(desc);
admin.close();
}
@Test
public void putToTable() throws IOException {
//创建表对象
HTable table = new HTable(conf, "teacher");
//创建put对象
Put put = new Put("l00002".getBytes());
put.add("info".getBytes(),"name".getBytes(),"san".getBytes());
table.put(put);
table.close();
}
/**
* 判断表是否存在
* @throws MasterNotRunningException
* @throws ZooKeeperConnectionException
* @throws IOException
*/
@Test
public void isExist() throws MasterNotRunningException, ZooKeeperConnectionException, IOException {
HBaseAdmin admin = new HBaseAdmin(conf);
boolean re = admin.tableExists("student");
System.out.println(re);
admin.close();
}
//删除行
@Test
public void deleteRow() throws IOException {
HTable table = new HTable(conf,"teacher");
Delete delete = new Delete("100002".getBytes());
table.delete(delete);
table.close();
}
@Test
public void scanTable() throws IOException {
HTable table = new HTable(conf, "teacher");
Scan scan = new Scan();
ResultScanner rs = table.getScanner(scan);
for (Result r : rs) {
Cell[] cs = r.rawCells();
for (Cell c : cs) {
System.out.print("行键"+ Bytes.toString(CellUtil.cloneRow(c))+"\t");
System.out.print("列族"+Bytes.toString(CellUtil.cloneFamily(c)));
System.out.print("列"+Bytes.toString(CellUtil.cloneRow(c))+"\t");
System.out.println("值"+Bytes.toString(CellUtil.cloneValue(c)));
}
}
}
@Test
public void getRow() throws IOException {
HTable table = new HTable(conf, "teacher");
Get get = new Get("100001".getBytes());
Result rs = table.get(get);
Cell[] cs = rs.rawCells();
for (Cell c : cs) {
System.out.print("行键"+ Bytes.toString(CellUtil.cloneRow(c))+"\t");
System.out.print("列族"+Bytes.toString(CellUtil.cloneFamily(c)));
System.out.print("列"+Bytes.toString(CellUtil.cloneRow(c))+"\t");
System.out.println("值"+Bytes.toString(CellUtil.cloneValue(c)));
}
}
}
HBase的读写流程
读数据流程
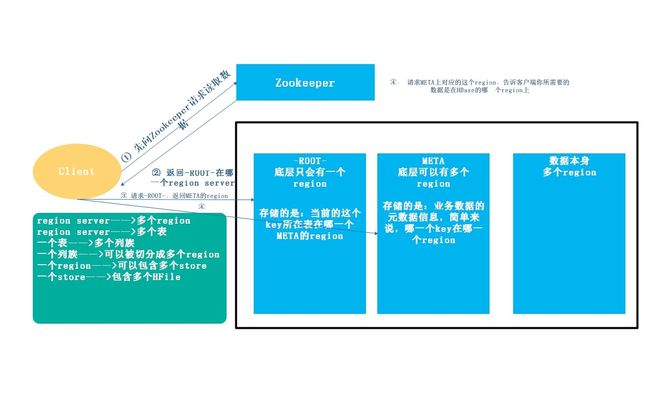
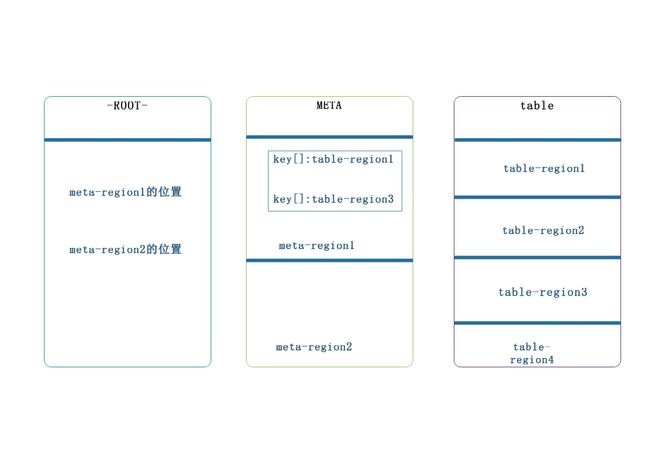
Hbase 两张特殊的表,这两张表存在于Zookeeper上-Root表记录了》Meta表的region信息
-Meta表,该表不会做分裂,记录了用户表的Region信息,.Meta表可以有多个region
寻址流程:
从0.96之后去掉了-Root表,所以流程是:从Zookeeper(/hbase/meta-region-server)中获取hbase.meta的位置(HRegionServer的位置),缓存该位置信息,然后从HRegionServer中查询用户Table对应请求的Rowkey所在的HregionServer,缓存该位置信息,最后从查询到HRegionServer中读取Row
扫描的依次顺序;BlockCache,MemStore,StoreFile(HFile) 块缓存
region server保存着meta表以及数据,要想访问数据。客户端必须通过Zookeeper获取—ROOT—的位置信息
通过—Root—来获取meta中的region的位置
客户端通过meta获取数据的region位置
通过region的位置获取数据
写入数据流程

客户端先访问Zookeeper,找到元数据信息
确定要写入的数据在哪个region上
然后客户端向该region server发送写数据的请求
客户端先把数据写到HLog中,以及所需要的操作,防止数据丢失
然后写入Memstore
如果HLog和Memstore 均写入成功,则表示该数据写入成功。如果在这个过程中,Memstore的数据达到了阀值,就会将Memsstore中的数据刷新到storefile
storefile过多时,region就会越来越大,如果达到阈值,那么region会被master一分为二
storefile最后会不断的溢出成Hfile
在region server空闲的时候,会将HFile这些小文件进行合并
HBase的MR
通过HBase的相关JavaAPI,我们可以实现HBase操作的MapReduce过程,如使用MapReduce将数据从本地文件系统导入数据到HBase的表中。
统计HBase表中行
[root@master jar]# yarn jar hbase-server-1.4.6.jar rowcounter student
## 报错
## Exception in thread "main" java.lang.NoClas
sDefFoundError: org/apache/hadoop/hase/filter/
Filter
## 解决方案
## 在环境变量中添加HADOOP_CLASSPATH变量,将HBase的
jar包添加进去
导入HDFS上的文件到HBase
[root@master jar]# vim input_hbase.tsv
## 添加数据
11111 zhangsan 18
11112 lisi 17
11113 wangwu 99
11114 zhaoliu 100
## 上传至Hadoop
[root@master jar]# hadoop fs -mkdir /hbase/mr/
[root@master jar]# hadoop fs -put input_hbase.tsv /hbase/mr/
## 在HBase上创建相应的表,否则会出现表不存在的异常
hbase(main):001:0> create 'people','info'
## 执行
[root@master jar]# yarn jar hbase-server-1.4.6.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age people
hdfs://master:9000/hbase/mr/
自定义HBase MR
package com.zhiyou.HBase.diymr;
import java.io.IOException;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Mapper;
/**
* 使用HBase作为输入
* @author Administrator
*
*/
public class HTableToOtherTable extends TableMapper{
@Override
protected void map(ImmutableBytesWritable key, Result value,
Mapper.Context context)
throws IOException, InterruptedException {
//将People中的数据提取出,放入另一个HBase中
Put put = new Put(key.get());
Cell[] cells = value.rawCells();
//解析这行数据
for (Cell c : cells) {
if("info".equals(Bytes.toString(CellUtil.cloneFamily(c)))) {
//是这个列族的数据取出
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(c)))) {
//将这个数据加入到put
put.add(c);
}else if("age".equals(Bytes.toString(CellUtil.cloneQualifier(c)))) {
put.add(c);
}
}
}
//将数据一个个传递到reduce
context.write(key, put);
}
}
Reduce:
package com.zhiyou.HBase.diymr;
import java.io.IOException;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class HTableToOtherTableReduce extends TableReducer{
@Override
protected void reduce(ImmutableBytesWritable key, Iterable values,
Reducer.Context context)
throws IOException, InterruptedException {
for (Put put : values) {
context.write(NullWritable.get(),put);
}
}
}
Driver:
package com.zhiyou.HBase.diymr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class HTableToOtherTableDriver extends Configured implements Tool{
private Scan scan = new Scan();
@Override
public int run(String[] arg0) throws Exception {
//创建conf
Configuration conf = this.getConf();
//配置conf
//创建job
Job job = Job.getInstance(conf, "hhah");
job.setJarByClass(HTableToOtherTableDriver.class);
//配置job
TableMapReduceUtil.initTableMapperJob(
"people", //表名
scan, //扫描器
HTableToOtherTable.class, //输入Mapper类
ImmutableBytesWritable.class,//输入Mapper类型
Put.class, //输出Mapper类型
job);
TableMapReduceUtil.initTableReducerJob(
"people_mr",
HTableToOtherTableReduce.class,
job );
//执行
boolean re = job.waitForCompletion(true);
if(re) {
System.out.println("执行成功");
}else {
System.out.println("失败");
}
return re?0:1;
}
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
ToolRunner.run(conf,new HTableToOtherTableDriver(), args);
}
}
Hbase过滤器FilterListFilterList
代表一个过滤器列表,可以添加多个过滤器进行查询,多个过滤器之间的关系有:与关系(符合所有):FilterList.Operator.MUST_PASS_ALL或关系(符合任一):FilterList.Operator.MUST_PASS_ONE
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ONE);
Scan s1 = new Scan();
filterList.addFilter(new SingleColumnValueFilter(
Bytes.toBytes(“f1”),
Bytes.toBytes(“c1”),
CompareOp.EQUAL,Bytes.toBytes(“v1”)));
filterList.addFilter(new SingleColumnValueFilter(
Bytes.toBytes(“f1”),
Bytes.toBytes(“c2”),
CompareOp.EQUAL,Bytes.toBytes(“v2”)));
// 添加下面这一行后,则只返回指定的cell,同一行中的
其他cell不返回
s1.addColumn(Bytes.toBytes(“f1”), Bytes.toBytes(“c1”));
s1.setFilter(filterList); //设置filter
ResultScanner ResultScannerFilterList = table
.getScanner(s1);//返回结果列表
过滤器的种类
列植过滤器—SingleColumnValueFilter过滤列植的相等、不等、范围等列名
前缀过滤器—ColumnPrefixFilter过滤指定前缀的列名多个列名前缀过滤器—MultipleColumnPrefixFilter过滤多个指定前缀的列名
rowKey过滤器—RowFilter通过正则,过滤rowKey值。
列植过滤器—SingleColumnValueFilterSingleColumnValueFilter
列值判断相等 (CompareOp.EQUAL ),
不等(CompareOp.NOT_EQUAL),
范围 (e.g., CompareOp.GREATER)…………下面示例检查列值和字符串'values' 相等...
SingleColumnValueFilter f = new SingleColumnValueFilter(
Bytes.toBytes("cFamily"),
Bytes.toBytes("column"),
CompareFilter.CompareOp.EQUAL,
Bytes.toBytes("values"));
s1.setFilter(f);
注意:如果过滤器过滤的列在数据表中有的行中不存在,那么这个过滤器对此行无法过滤。
#hbase表数据
hbase(main):002:0> scan 'teacher'
ROW COLUMN+CELL
8000 column=info:sex, timestamp=1534993262771, value=hhaha
9990 column=info:sex, timestamp=1534993287438, value=hehe
l00001 column=info:name, timestamp=1534844312072, value=zhangsan
l00002 column=info:name, timestamp=1534944349197, value=san
l00002 column=zhicheng:zhang, timestamp=1534944349197, value=11
@Test
public void scanTable() throws IOException {
HTable table = new HTable(conf, "teacher");
Scan scan = new Scan();
ResultScanner rs = table.getScanner(scan);
for (Result r : rs) {
Cell[] cs = r.rawCells();
System.out.println(r);
for (Cell c : cs) {
System.out.print("行键"+ Bytes.toString(CellUtil.cloneRow(c))+"\t");
System.out.print("列族"+Bytes.toString(CellUtil.cloneFamily(c)));
System.out.print("列"+Bytes.toString(CellUtil.cloneRow(c))+"\t");
System.out.println("值"+Bytes.toString(CellUtil.cloneValue(c)));
}
}
}
结果:
keyvalues={8000/info:sex/1534993262771/Put/vlen=5/seqid=0}
行键8000 列族info列sex 值hhaha
keyvalues={9990/info:sex/1534993287438/Put/vlen=4/seqid=0}
行键9990 列族info列sex 值hehe
keyvalues={l00001/info:name/1534844312072/Put/vlen=8/seqid=0}
行键l00001 列族info列name 值zhangsan
列名前缀过滤器—ColumnPrefixFilter
过滤器—ColumnPrefixFilterColumnPrefixFilter 用于指定列名前缀值相等
ColumnPrefixFilter f = new ColumnPrefixFilter(
Bytes.toBytes("values"));
2. s1.setFilter(f);
多个列值前缀过滤器—MultipleColumnPrefixFilterMultipleColumnPrefixFilter 和 ColumnPrefixFilter 行为差不多,但可以指定多个前缀
byte[][] prefixes = new byte[][] {Bytes.toBytes("value1"),Bytes.toBytes("value2")};
Filter f = new MultipleColumnPrefixFilter(prefixes);
s1.setFilter(f);
rowKey过滤器—RowFilterRowFilter
是rowkey过滤器通常根据rowkey来指定范围时,使用scan扫描器的StartRow和StopRow方法比较好。
Filter f = new RowFilter(
CompareFilter.CompareOp.EQUAL,
new RegexStringComparator("^1234")); /
/匹配以1234开头的rowkey
s1.setFilter(f);
HBase 数据库架构组成部分。
HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等。
HBase与Hive的区别
Hive
数据仓库
Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个映射关系,以方便使用 HQL 去管理查询。
用于数据分析、清洗
Hive 适用于离线的数据分析和清洗,延迟较高。基于 HDFS 、MapReduceHive 存储的数据依旧在 DataNode 上,编写的 HQL 语句终将是转换为 MapReduce 代码执行。HBase数据库
HBase
数据库
是一种面向列存储的分布式的非关系型数据库。
用于存储结构化和非结构化的数据适用于单表非关系型数据的存储,不适合做关联查询,类似 JOIN等操作。
基于 HDFS
数据持久化存储的体现形式是 Hfile,存放于 DataNode 中,被ResionServer 以 region 的形式进行管理。
延迟较低,适合接入在线业务使用面对大量的企业数据,HBase 可以实现单表大量数据的存储,同时提供了高效的数据访问速度。
Hive与HBase集成操作
配置
替换hive中lib中jar包(HBase zookeeper)
修改配置文件
[root@master jar]# vim /opt/apps/Hive/hive-2.3.3/conf/hive-site.xml
hive.zookeeper.quorum
master,slave1,slave2
hive (default)> create table hive_hbase_people(id int,name string,age int)
> stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
> with serdeproperties("hbase.columns.mapping"=":key,info:name,info:age")
> tblproperties("hbase.table.name"="hbase_hive_people");
## 创建完成之后,HBASE中的表会自动创建
## 关联表要想插入数据,不能使用load方式加载
简单操作
假设HBase的某一个表中,已经存储了一些数据,现在需使用Hive的外部表来关联的HBase的这个表,可以,可以借助Hive进行离线分析
## 在HBase 创建相应的表
hbase(main):003:0> create 'zhiyou:student','haha'
## hive中创建关联的外部表
hive (default)> create external table hive_external_hbase_student(id int,name string)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties ("hbase.columns.mapping"=":key,haha:name")
tblproperties("hbase.table.name"="zhiyou:student");
hive (default)> select * from hive_external_hbase_student;
sqoop与HBase的集成操作
配置
[root@master ~]# vim /opt/apps/Sqoop/sqoop-1.4/conf/sqoop-env.sh
#set the path to where bin/hbase is available
export HBASE_HOME=/opt/apps/HBase/hbase-1.4.6
#Set the path for where zookeper config dir is
export ZOOKEEPER_HOME=/opt/apps/Zookeeper/zookeeper-3.4.12
export ZOOCFGDIR=$ZOOKEEPER_HOME/conf
[root@master Zookeeper]# sqoop import
--connect jdbc:mysql://master:3306/mysql_bigdata
--username root
--password 123456
--table product
--columns "id,name,price"
--hbase-create-table
--hbase-row-key "id"
--hbase-table "hbase_sqoop_product"
--column-family "info"
--split-by id
相关参数
参数 描述
columnfamilySets the target column family for the import设置导入
的目标列族。
--hbasecreatetableIf specified, create missing HBase tables 是否自动创建
不存在的 HBase 表(这就意味着,不需要手动提前在
HBase 中先建立表)
--hbaserow-keySpecifies which input column to use as the row
key.In case, if input table contains composite key,
then must be in the form of a comma-separated list
of composite key attributes. mysql 中哪一列的值作为
HBase 的 rowkey,如果rowkey是个组合键,则以逗号分
隔。 (注:避免 rowkey 的重复)
--hbasetableSpecifies an HBase table to use as the target instead
of HDFS.指定数据将要导入到 HBase 中的哪张表中。
--hbasebulkloadEnables bulk loading.是否允许 bulk 形式的导入。
简单使用
[root@master ~]# sqoop import \
--connect jdbc:mysql://master:3306/mysql_bigdata \
--username root \
--password 123456 \
--table product \
--columns "id,name,price" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_sqoop_product_1" \
--column-family "info"
Hbase shell的其他命令
数据的备份与恢复
备份
停止 HBase 服务后,使用 distcp 命令运行 MapReduce 任务进行备份,将数据备份到另一个地方,可以是同一个集群,也可以是专用的备份集群。即,把数据转移到当前集群的其他目录下(也可以不在同一个集群中)
恢复
非常简单,与备份方法一样,将数据整个移动回来即可。
节点的管理服役(commissioning )
当启动 regionserver 时,regionserver 会向 HMaster 注册并开始接收本地数据,开始的时候,新加入的节点不会有任何数据,平衡器开启的情况下,将会有新的 region 移动到开启的RegionServer 上。如果启动和停止进程是使用 ssh 和 HBase 脚本,那么会将新添加的节点的主机名加入到 conf/regionservers 文件中。
退役
顾名思义,就是从当前 HBase 集群中删除某个 RegionServer
停止负载均衡
balance_switch=flase
停止region server
hbase-daemon.sh stop regret
高可用
在 HBase 中 Hmaster 负责监控 RegionServer 的生命周期,均衡RegionServer 的负载,如果 Hmaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase 支持对 Hmaster 的高可用配置。
[root@master conf]# vim backup-masters
master
slave1
slave2
##远程拷贝
hbase 的预分区。
首先就是要想明白数据的key是如何分布的,然后规划一下要分成多少region,每个region的startkey和endkey是多少,然后将规划的key写到一个文件中。比如,key的前几位字符串都是从0001~0010的数字,这样可以分成10个region。
hbase shell中建分区表,指定分区文件:
create 'split_table_test', 'cf', {SPLITS_FILE => 'region_split_info.txt'}
Hbase 设计表的时候 rowkey 和分区考虑哪个?还是都考虑?
Hbase默认建表时有一个region,这个region的rowkey是没有边界的,即没有startkey和endkey,在数据写入时,所有数据都会写入这个默认的region,随着数据量的不断 增加,此region已经不能承受不断增长的数据量,会进行split,分成2个region。在此过程中,会产生两个问题:1.数据往一个region上写,会有写热点问题。2.region split会消耗宝贵的集群I/O资源。基于此我们可以控制在建表的时候,创建多个空region,并确定每个region的起始和终止rowky,这样只要我们的rowkey设计能均匀的命中各个region,就不会存在写热点问题。自然split的几率也会大大降低。当然随着数据量的不断增长,该split的还是要进行split。
Linux优化
## 1. 开启文件预读缓存:ra:readahead
blockdev --setra 1024 /dev/sda
## 2. 关闭进程睡眠池:不允许后台进程进入睡眠状态,如果
这个进程是空闲的,那么直接kill掉
sysctl -w vm.swappiness=0
## 调整允许打开最大的文件数和线程数
ulimit -u ## 允许打开最大文件数
ulimit -n ## 查看允许最大的进程数
##可以在下面的文件中修改
/etc/security/limits.conf
## 3. 补丁更新