json的中文显示以及转码问题
利用服务器返回结果的一些程序中,返回的汉字是UTF-8格式,如百度语音识别处理的返回结果,直接打印如下:
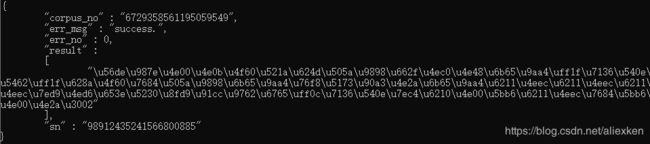
返回的结果是正确的,但是由于是UTF格式,所以不能正确显示为汉字,原因是系统对汉字的显示方式,默认不是UTF-8。
为了能够正确的显示汉字返回结果,这里需要做一个转码过程,代码如下:(忘记是从哪里找的了。。。)
std::string UTF8_To_string(const std::string & str)
{
int nwLen = MultiByteToWideChar(CP_UTF8, 0, str.c_str(), -1, NULL, 0);
wchar_t * pwBuf = new wchar_t[nwLen + 1];//一定要加1,不然会出现尾巴
memset(pwBuf, 0, nwLen * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, str.c_str(), str.length(), pwBuf, nwLen);
int nLen = WideCharToMultiByte(CP_ACP, 0, pwBuf, -1, NULL, NULL, NULL, NULL);
char * pBuf = new char[nLen + 1];
memset(pBuf, 0, nLen + 1);
WideCharToMultiByte(CP_ACP, 0, pwBuf, nwLen, pBuf, nLen, NULL, NULL);
std::string retStr = pBuf;
delete[]pBuf;
delete[]pwBuf;
pBuf = NULL;
pwBuf = NULL;
return retStr;
}
当然,反转也是可以的:
std::string string_To_UTF8(const std::string & str)
{
int nwLen = ::MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, NULL, 0);
wchar_t * pwBuf = new wchar_t[nwLen + 1];//一定要加1,不然会出现尾巴
ZeroMemory(pwBuf, nwLen * 2 + 2);
::MultiByteToWideChar(CP_ACP, 0, str.c_str(), str.length(), pwBuf, nwLen);
int nLen = ::WideCharToMultiByte(CP_UTF8, 0, pwBuf, -1, NULL, NULL, NULL, NULL);
char * pBuf = new char[nLen + 1];
ZeroMemory(pBuf, nLen + 1);
::WideCharToMultiByte(CP_UTF8, 0, pwBuf, nwLen, pBuf, nLen, NULL, NULL);
std::string retStr(pBuf);
delete[]pwBuf;
delete[]pBuf;
pwBuf = NULL;
pBuf = NULL;
return retStr;
}
这样在输出结果,就是正确的汉字了。