自然语言话题分析-从NMF矩阵分解模型说起
1、概述
我们在接触自然语言领域都会涉及到基于监督学习与非监督学习的文本分类,在非监督学习领域会提到lsa、lda主题模型的实现。但之前的讨论都是基于工具层面的。其实这些模型的基础算法都是NMF模型分解。可以我们不会对文本从底层去实现这样的算法。但了解其实现的机制还是非常有帮助的。
2、关于NMF矩阵
NMF的思想:V=WH(W权重矩阵、H特征矩阵、V原矩阵),通过计算从原矩阵提取权重和特征两个不同的矩阵出来。属于一个无监督学习的算法。当然如果从数学角度来解释这个事情,就会变得毫无意义,所以还是结合自然语言主题分析这个具体应用来解释这个问题。
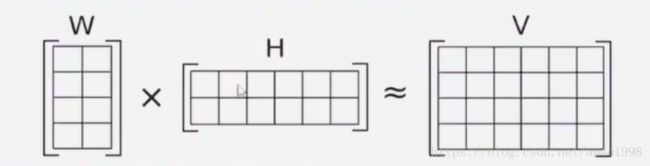
在自然语言处理的任务当中,我们经常用词,词频来表示一个语料。当然为了使用数字来表示单词,我们会使用字典,从而利用字典中的词的索引来表示该词。那么同样如果我们有6篇文章,V矩阵就是对这6篇文章或者整体语料库一个表示,他包含三个信息,词,词频和文档。所以V矩阵被称为:term-document矩阵,矩阵的行数 i 代表了字典中包含单词的数量,矩阵的列数 j 代表了文档的数量,而i,j对应的值是一个词频,代表着第i个单词在第j个文档中出现的次数。
W矩阵代表单词与topic(话题)的密切程度,在上图中W是一个2*4的矩阵,行数代表第 i 个单词, 列数代表第 j 个主题,对应的值代表第 i 个单词与 第 j 个主题的密切程度。所有W矩阵被成为 term-topic矩阵
H被成为 topic -document 矩阵 行数代表第 i 个主题,列数代表第 j 个文档,对应的值代表文档与主题的关联程度。
3、使用sklearn实现NMF矩阵分解
sklearn本身提供了相关的语料与NMF的实现方法,要实现基于NMF的主题分解主要需要一下几步
- 抽取关键词生成字典
- 生成V矩阵
- 执行NMF分解
3.1 导入必须代码库
编写程序之前必须导入相关代码库,主要有以下几个
- tfidf库用于基于tfidf算法提取关键词
- NMF用户非负矩阵分解
- fetch_20newsgroups:提供相关语料
请参考下面代码:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import NMF
from sklearn.datasets import fetch_20newsgroups
import numpy as py
from time import time3.2 读取相关语料
请参照如下代码:
dataset = fetch_20newsgroups(random_state=1,remove=('headers','footers','quotes'))语料库要远程下载,所以可能要花几分钟的时间,可以使用下面代码,检查一下语料的结构
print(len(dataset['data']))
print(dataset['data'][0])输出结果如下图所示:

3.3 提取关键词并分析词频
请参照下面代码
# 使用tfidf抽取单词
tfidf_vector = TfidfVectorizer(max_df=0.95,min_df=2,max_features=2000,stop_words='english')
tfidf = tfidf_vector.fit_transform(dataset['data'])
print(tfidf.shape)3.4 使用NMF算法分解矩阵
这个算法是根据概率分布学的一个拟合的过程,所以和神经网络一样需要设定一些超参数,请参照如下代码
nmf = NMF(n_components=10,random_state=1,alpha=.1,l1_ratio=0.3).fit(tfidf)这里,我们将语料进行了10个topic的分解
3.5 检测分解效果
feature_names = tfidf_vector.get_feature_names()
for topic_idx,topic in enumerate(nmf.components_):
print(str(topic_idx)+':')
print(','.join([feature_names[i] for i in topic.argsort()[:-11:-1]]))输出效果如下图所示:

从上面的结果中我们可以看到主题2都是关于 上帝,圣经与宗教的,主题4都是关于 硬盘、磁盘与软盘的,主题6都是关于 程序,操作系统,文件系统的