Python爬虫入门(urllib+Beautifulsoup)
本文包括:
1、爬虫简单介绍
2、爬虫架构三大模块
3、urllib
4、BeautifulSoup
5、实战演练:爬取百度百科1000个页面
1、爬虫简单介绍
爬虫:一段自动抓取互联网信息的程序
从一个url出发,然后访问和这个url相关的各种url,并提取相关的价值数据。
URL:Uniform Resource Location的缩写,译为“统一资源定位符”
-
URL的格式由下列三部分组成:
- 第一部分是协议(或称为服务方式);
- 第二部分是存有该资源的主机IP地址(有时也包括端口号);
- 第三部分是主机资源的具体地址,如目录和文件名等。
2、爬虫架构三大模块
-
URL 管理器
管理待抓取URL集合和已抓取URL集合
防止重复抓取、防止循环抓取
-
逻辑:
1.判断待添加URL是否在容器中
2.添加新URL到待爬取集合
3.判断是否有待爬取URL
4.获取待爬取URL
5.将URL从待爬取移动至已爬取
-
URL管理器的实现方式有三种:
1、适合个人的:内存
2、小型企业或个人:关系数据库(永久存储或内存不够用,如 MySQL)
3、大型互联网公司:缓存数据库(高性能,如支持 set 的 redis)
-
网络下载器
将给定的URL网页内容下载到本地,以便后续操作
-
常见网络下载器:
urllib2:Python 官方基础模块
-
requests:第三方
注意:python 3.x中 urllib 库和 urilib2 库合并成了urllib 库。其中 urllib2.urlopen() 变成了urllib.request.urlopen()。urllib2.Request() 变成了 urllib.request.Request()
-
特殊情境处理(4种 handler):
1.需要用户登录才能访问(HTTPCookieProcessor)
2.需要代理才能访问(ProxyHandler)
3.协议使用HTTPS加密访问(HTTPSHandler)
4.URL自动跳转(HTTPRedirectHandler)
-
4种方法下载网页的实例(基于 Python3.6)
见下一节:urllib库
-
网络解析器
- 通过解析得到想要的内容,解析出新的 url 交给 URL 管理器,形成循环
- 正则表达式:模糊匹配
- beautifulsoup:第三方,可使用 html.parser 和 lxml 作为解析器,结构化解析(DOM 树)
- html.parser
- lxml
3、urllib
-
4种方法下载网页的实例(基于 Python3.6)
import urllib.request import http.cookiejar url = 'https://baidu.com' print('urllib下载网页方法1:最简洁方法') # 直接请求 res = urllib.request.urlopen(url) # 获取状态码,如果是200则获取成功 print(res.getcode()) # 读取内容 #cont是很长的字符串就不输出了 cont = res.read().decode('utf-8') print('urllib下载网页方法2:添加data、http header') # 创建Request对象 request = urllib.request.Request(url) # 添加数据 request.data = 'a' # 添加http的header #将爬虫伪装成Mozilla浏览器 request.add_header('User-Agent', 'Mozilla/5.0') # 添加http的header #指定源网页,防止反爬 request.add_header('Origin', 'https://xxxx.com') # 发送请求获取结果 response = urllib.request.urlopen(request) print('urllib下载网页方法3:添加特殊情景的处理器') # 创建cookie容器 cj = http.cookiejar.CookieJar() # 创建一个opener opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) # 给urllib安装opener urllib.request.install_opener(opener) # 使用带有cookie的urllib访问网页 response = urllib.request.urlopen(url) # 使用 post 提交数据 from urllib import parse from urllib.request import Request from urllib.request import urlopen req = Request(url) postData = parse.urlencode([ (key1, value1), (key2, value2), ... ]) urlopen(req, data=postData.encode('utf-8'))
4、BeautifulSoup
文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
-
BeautifulSoup语法:
根据一个HTML网页字符串创建BeautifulSoup对象,创建的同时就将整个文档字符串下载成一个DOM树,后根据这个DOM树搜索节点。find_all方法搜索出所有满足的节点,find方法只会搜索出第一个满足的节点,两方法参数一致。搜索出节点后就可以访问节点的名称、属性、文字。因此在搜索时也可以按照以上三项搜索。
-
实例:
from bs4 import BeautifulSoup # 第一步:根据HTML网页字符串创建BeautifulSoup对象 soup = BeautifulSoup( 'XX.html', # HTML文档字符串 'html.parser' # HTML解析器 from_encoding='utf8' # HTML文档的编码 ) # 第二步:搜索节点(find_all,find) # 方法:find_all(name,attrs,string) # 名称,属性,文字 # 查找所有标签为a的标签 soup.find_all(‘a’) # 查找第一个标签为a的标签 soup.find(‘a’) # 查找所有标签为a,链接符合'/view/123.html'形式的节点 soup.find_all('a',href='/view/123.html') # 查找所有标签为div,class为abc,文字为python的节点 soup.find_all('div',class_='abc',string='python') # class 是 Python 保留关建字,所以为了区别加了下划线 # 以下三种方式等价 # soup.h1 = soup.html.body.h1 = soup.html.h1 # 最强大的是利用正则表达式 import re soup.find('a', href=re.compile(r"view")) soup.find_all("img", {"src":re.compile("xxx")}) # 第三步:访问节点信息 # 得到节点:Python node = soup.find(‘a’) # 获取查找到的节点的标签名称 print(node.name) # 获取查找的a节点的href属性 print(node['href']) # 获取查找到的a节点的文本字符串 print(node.get_text())findAll() 、find()函数详解:
findAll(tag, attributes, recursive, text, limit, keywords)。
find(tag, attributes, recursive, text, keywords)tag 可以传入一个标签的名称或多个标签名组成的Python列表做标签参数
attributes是用一个Python字典封装一个标签的若干属性和对应的属性值
recursive是布尔变量,默认为True,如果为False,findAll就只查找文档的一级标签
text用标签的文本内容去匹配,而不是标签的属性
limit 只能用于findAll,find其实就是findAll的limit=1的特殊情况
keyword 有点冗余,不管了
95%的时间都只用到了tag、attributes。
-
导航树
-
子标签children与后代标签descendants:
# 匹配标签的的下一级标签 bsobj.find("table", {"id":"giftlist"}).children # 匹配标签的所有后代标签,包括一大堆乱七八糟的img,span等等 bsobj.find("table", {"id":"giftlist"}).descendants -
兄弟标签next_siblings/previous_siblings:
# 匹配标签的后一个标签 bsobj.find("table", {"id":"giftlist"}).tr.next_siblings # 匹配标签的前一个标签(如果同级标签的最后一个标签容易定位,那么就用这个) bsobj.find("table", {"id":"giftlist"}).tr.previous_siblings -
父标签parent、parents:
# 选取table标签本身(这个操作多此一举,只是为了举例层级关系) bsobj.find("table", {"id":"giftlist"}).tr.parent
-
-
获取属性
-
如果我们得到了一个标签对象,可以用下面的代码获得它的全部标签属性:
mytag.attrs -
注意:这行代码返回的是一个字典对象,所以可以获取任意一个属性值,例如获取src属性值就这样写代码:
mytag.attrs["src"]
-
-
编写可靠的代码(捕捉异常)
-
让我们看看爬虫import语句后面的第一行代码,如何处理那里可能出现的异常:
html = urlopen("http://www.pythonscraping.com/pages/page1.html")这有可能会报404错误,所以应该捕捉异常:
try: html = urlopen("http://www.pythonscraping.com/pages/page1.html") except HTTPError as e: print(e) # 返回空值,中断程序,或者执行另一个方案 else: # 程序继续。注意:如果你已经在上面异常捕捉那一段代码里返回或中断(break), # 那么就不需要使用else语句了,这段代码也不会执行 -
下面这行代码(nonExistentTag是虚拟的标签,BeautifulSoup对象里实际没有)
print(bsObj.nonExistentTag)会返回一个None对象。处理和检查这个对象是十分必要的。如果你不检查,直接调用这个None对象的子标签,麻烦就来了。如下所示。
print(bsObj.nonExistentTag.someTag)这时就会返回一个异常:
AttributeError: 'NoneType' object has no attribute 'someTag'那么我们怎么才能避免这两种情形的异常呢?最简单的方式就是对两种情形进行检查:
try: badContent = bsObj.nonExistingTag.anotherTag exceptAttributeError as e: print("Tag was not found") else: if badContent == None: print ("Tag was not found") else: print(badContent)
-
5、实战演练:爬取百度百科1000个页面
-
步骤
- 确定目标:确定抓取哪个网站的哪些网页的哪部分数据。本实例确定抓取百度百科python词条页面以及它相关的词条页面的标题和简介。
- 分析目标:确定抓取数据的策略。一是分析要抓取的目标页面的URL格式,用来限定要抓取的页面的范围;二是分析要抓取的数据的格式,在本实例中就是要分析每一个词条页面中标题和简介所在的标签的格式;三是分析页面的编码,在网页解析器中指定网页编码,才能正确解析。
- 编写代码:在解析器中会使用到分析目标步骤所得到的抓取策略的结果。
- 执行爬虫。
-
确定框架
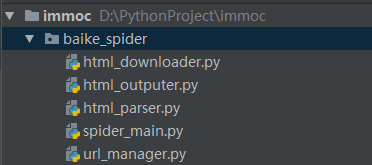 20171031-baike
20171031-baike- spider_main.py 是爬虫主体
- url_manager.py 维护了两个集合,用来记录要爬取的 url 和已爬取的 url
- html_downloader.py 调用了 urllib 库来下载 html 文档
- html_parser.py 调用了 BeautifulSoup 来解析 html 文档
- html_outputer.py 把解析后的数据存储起来,写入 output.html 文档中
-
url_manager
class UrlManager(object): def __init__(self): # 初始化两个集合 self.new_urls = set() self.old_urls = set() def add_new_url(self, url): if url is None: return if url not in self.new_urls or self.old_urls: # 防止重复爬取 self.new_urls.add(url) def add_new_urls(self, urls): if urls is None or len(urls) == 0: return for url in urls: # 调用子程序 self.add_new_url(url) def has_new_url(self): return len(self.new_urls) != 0 def get_new_url(self): new_url = self.new_urls.pop() self.old_urls.add(new_url) return new_url解释:管理器维护了两个集合(new_urls、old_urls),分别记录要爬和已爬 url,注意到前两个 add 方法,一个是针对单个 url,一个是针对 url 集合,不要忘记去重操作。
-
html_downloader
# coding:utf-8 import urllib.request class HtmlDownloader(object): def download(self, url): if url is None: return None response = urllib.request.urlopen(url) if response.getcode() != 200: # 判断是否请求成功 return None return response.read()解释:很直观的下载,这是最简单的做法
-
html_parser
from bs4 import BeautifulSoup import urllib.parse import re class HtmlParser(object): def _get_new_urls(self, page_url, soup): new_urls = set() links = soup.find_all('a', href = re.compile(r"/item/")) for link in links: new_url = link['href'] new_full_url = urllib.parse.urljoin(page_url, new_url) new_urls.add(new_full_url) return new_urls def _get_new_data(self, page_url, soup): res_data = {} res_data['url'] = page_url title_node = soup.find('dd', class_="lemmaWgt-lemmaTitle-title").find("h1") res_data['title'] = title_node.get_text() summary_node = soup.find('div', class_="lemma-summary") res_data['summary'] = summary_node.get_text() return res_data def parse(self, page_url, html_cont): if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont, 'html.parser', from_encoding='utf-8') new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) return new_urls, new_data解释:在解析器中,注意到 parse 方法,它从 html 文档中找到所有词条链接,并将它们包装到 new_urls 集合中,最后返回,同时,它还会解析出 new_data 集合,这个集合存放了词条的名字(title)以及摘要(summary)。
-
spider_main
# coding:utf-8 from baike_spider import url_manager, html_downloader, html_parser, html_outputer import logging class SpiderMain(object): def __init__(self): self.urls = url_manager.UrlManager() self.downloader = html_downloader.HtmlDownloader() self.parser = html_parser.HtmlParser() self.outputer = html_outputer.HtmlOutputer() def crawl(self, root_url): count = 1 # record the current number url self.urls.add_new_url(root_url) while self.urls.has_new_url(): try: new_url = self.urls.get_new_url() print('crawl No.%d: %s'%(count, new_url)) html_cont = self.downloader.download(new_url) new_urls, new_data = self.parser.parse(new_url, html_cont) self.urls.add_new_urls(new_urls) self.outputer.collect_data(new_data) if count == 1000: break count += 1 except: logging.warning('crawl failed') self.outputer.output_html() if __name__ == "__main__": root_url = "https://baike.baidu.com/item/Python/407313" obj_spider = SpiderMain() obj_spider.crawl(root_url)解释:主程序将会从 “Python” 的词条页面进入,然后开始爬取数据。注意到,每爬取一个页面,都有可能有新的 url 被解析出来,所以要交给 url_manager 管理,然后将 new_data 收集起来,当跳出 while 循环时,将数据输出(因数据量不大,直接存放在内存中)。
-
html_outputer
class HtmlOutputer(object): def __init__(self): self.datas = [] # 列表 def collect_data(self, data): if data is None: return self.datas.append(data) def output_html(self): with open('output.html', 'w', encoding='utf-8') as fout: fout.write("") fout.write("") fout.write("") fout.write("") for data in self.datas: fout.write("
") fout.write("") fout.write("")") fout.write(" ") fout.write("%s " % data["url"]) fout.write("%s " % data["title"]) fout.write("%s " % data["summary"]) fout.write("解释:注意编码问题就好
-
输出:
"C:\Program Files\Python36\python.exe" D:/PythonProject/immoc/baike_spider/spider_main.py crawl No.1: https://baike.baidu.com/item/Python/407313 crawl No.2: https://baike.baidu.com/item/Zope crawl No.3: https://baike.baidu.com/item/OpenCV crawl No.4: https://baike.baidu.com/item/%E5%BA%94%E7%94%A8%E7%A8%8B%E5%BA%8F crawl No.5: https://baike.baidu.com/item/JIT crawl No.6: https://baike.baidu.com/item/%E9%9C%80%E6%B1%82%E9%87%8F crawl No.7: https://baike.baidu.com/item/Linux crawl No.8: https://baike.baidu.com/item/%E7%BD%91%E7%BB%9C%E7%BC%96%E7%A8%8B crawl No.9: https://baike.baidu.com/item/Pylons crawl No.10: https://baike.baidu.com/item/%E4%BA%A7%E5%93%81%E8%AE%BE%E8%AE%A1 Process finished with exit code 0 -
output.html
 20171031-baikeout
20171031-baikeout
本篇内容来自慕课网视频教程:http://www.imooc.com/learn/563
爬取百度百科的源码地址:https://github.com/edisonleolhl/imooc