impala的介绍以及与hbase的区别
一、impala的基本概念与原理
二、impala的常用命令
三、impala分页
四、impala与hive的比较
五、使用java连接impala进行基本的操作
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的 Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。
我们可以看看cloudera manager上impala相关的服务,如下图:

Impala架构:

Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为 Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应 数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给 客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
我们可以看看cloudera manager上impala相关的服务,如下图:
Impala架构:
Impalad: 与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的Impalad为 Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应 数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由Coordinator返回给 客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。在Impalad中启动三个ThriftServer: beeswax_server(连接客户端),hs2_server(借用Hive元数据), be_server(Impalad内部使用)和一个ImpalaServer服务。
Impala State Store: 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各 Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
CLI: 提供给用户查询使用的命令行工具(Impala Shell使用python实现),同时Impala还提供了Hue,JDBC, ODBC使用接口。
Impala的查询处理流程:

二、impala的常用命令
首先,我们在装有impalad服务的节点上执行impala-shell,便可进入命令行。
执行show databases;可以看到:
这个qyk_test数据库是我们在上一篇博文中通过hive创建的。我们只需执行INVALIDATE METADATA;便可将hive的元数据同步到impala,这个在后面的博文中还会进行介绍。
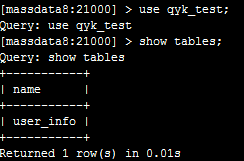
执行show tables;可以看到:

下面,我们执行select * from user_info;可以看到:
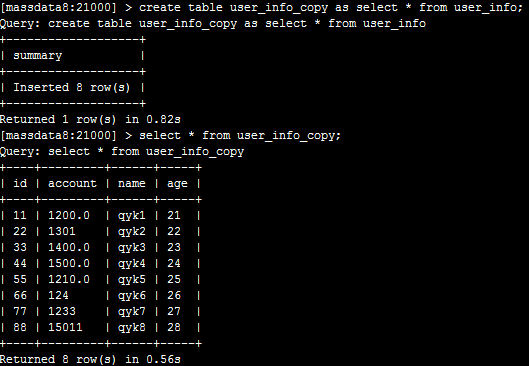
还可以执行create table user_info_copy as select * from user_info;直接将查询出来的数据入到一张新表中去,如下:

然后,我们执行drop table user_info_copy;便可删除临时表,如下:

好了,基本的命令就说到这儿了。
执行show databases;可以看到:
这个qyk_test数据库是我们在上一篇博文中通过hive创建的。我们只需执行INVALIDATE METADATA;便可将hive的元数据同步到impala,这个在后面的博文中还会进行介绍。
执行show tables;可以看到:
下面,我们执行select * from user_info;可以看到:
还可以执行create table user_info_copy as select * from user_info;直接将查询出来的数据入到一张新表中去,如下:
然后,我们执行drop table user_info_copy;便可删除临时表,如下:
好了,基本的命令就说到这儿了。
三、impala分页
impala中的分页是通过limit和offset实现,例如页大小为4,按id升序,我们要取user_info中第三页的数据,分页语句为select * from user_info order by id asc limit 2 offset 4;

也就是limit后面为pageSize,offset后面为(currentPage-1)*pageSize。
也就是limit后面为pageSize,offset后面为(currentPage-1)*pageSize。
四、impala与hive的比较
与Hive的关系,如下图:

Impala与Hive的异同:
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:两者使用相同的元数据。
Impala与Hive的异同:
数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
元数据:两者使用相同的元数据。
SQL解释处理:比较相似都是通过词法分析生成执行计划。
执行计划:
Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)
Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)
五、使用java连接impala进行基本的操作
pom依赖:由于impala使用的就是hive的元数据,因此直接可以通过连接thrift server进行相关操作。故使用hive的依赖即可。
首先,直接贴出代码如下:
[Java]
纯文本查看
复制代码
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
package
org.impala.demo;
import
java.sql.Connection;
import
java.sql.DriverManager;
import
java.sql.ResultSet;
import
java.sql.SQLException;
import
java.sql.Statement;
import
org.apache.log4j.Logger;
public
class
ImpalaJdbcClient {
private
static
String driverName =
"org.apache.hive.jdbc.HiveDriver"
;
private
static
String url =
"jdbc:hive2://172.31.25.8:21050/qyk_test;auth=noSasl"
;
private
static
String user =
"impala"
;
private
static
String password =
""
;
private
static
final
Logger log = Logger.getLogger(ImpalaJdbcClient.
class
);
public
static
void
main(String[] args) {
try
{
Class.forName(driverName);
Connection conn = DriverManager.getConnection(url, user, password);
Statement stmt = conn.createStatement();
// 创建的表名
String tableName =
"user"
;
stmt.execute(
"drop table if exists "
+ tableName);
stmt.execute(
"create table "
+ tableName
+
" (key int, value string) row format delimited fields terminated by '\t'"
);
// show tables
String sql =
"show tables '"
+ tableName +
"'"
;
System.out.println(
"Running: "
+ sql);
ResultSet res = stmt.executeQuery(sql);
if
(res.next()) {
System.out.println(res.getString(
1
));
}
// describe table
sql =
"describe "
+ tableName;
System.out.println(
"Running: "
+ sql);
res = stmt.executeQuery(sql);
while
(res.next()) {
System.out.println(res.getString(
1
) +
"\t"
+ res.getString(
2
));
}
// load data into table
// NOTE: filepath has to be local to the hive server
// NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per
// line
String filepath =
"/tmp/userinfo.txt"
;
sql =
"load data inpath '"
+ filepath +
"' into table "
+ tableName;
System.out.println(
"Running: "
+ sql);
stmt.execute(sql);
// select * query
sql =
"select * from "
+ tableName;
System.out.println(
"Running: "
+ sql);
res = stmt.executeQuery(sql);
while
(res.next()) {
System.out.println(String.valueOf(res.getInt(
1
)) +
"\t"
+ res.getString(
2
));
}
// regular hive query
sql =
"select count(1) from "
+ tableName;
System.out.println(
"Running: "
+ sql);
res = stmt.executeQuery(sql);
while
(res.next()) {
System.out.println(res.getString(
1
));
}
}
catch
(ClassNotFoundException e) {
e.printStackTrace();
log.error(driverName +
" not found!"
, e);
System.exit(
1
);
}
catch
(SQLException e) {
e.printStackTrace();
log.error(
"Connection error!"
, e);
System.exit(
1
);
}
}
}
|
然后,准备一个userinfo.txt如下,放在hdfs上的/tmp目录下:
[AppleScript]
纯文本查看
复制代码
|
1
2
3
4
|
1
zhangshan
2
lisi
3
wangwu
5
baidu
|
然后,执行可以看到控制台输出如下:

然后,我们在impala命令行执行select * from user,可以看到:

然后,我们在impala命令行执行select * from user,可以看到: