hadoop简单实例-WordCount
开发环境:window7
如果不知道怎么在window环境下安装hadoop,请参考教你Windows平台安装配置Hadoop2.5.2(不借助cygwin)
本实例先贴源代码,再讲解步骤。
代码如下:
package test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* Hadoop - 统计文件单词出现频次
* @author antgan
*
*/
public class WordCount {
public static class WordCountMap extends
Mapper {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer {
public void reduce(Text key, Iterable values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
运行测试:
一、 打包WordCount.java成jar包
两种方法:
1. 采用javac 指令打包,因为程序依赖两个jar包hadoop-core.1.2.1.jar,和commons-cli.1.2.jar。所以要指定依赖包的路径。
#编译WordCount.java 转成.class
javac -classpath D:/lib/hadoop-core-1.2.1.jar:D:/lib/commons-cli.1.2.jar -d D:/output WordCount.java
#打包成jar包
jar -cvf wordcount.jar *.class 2.采用IDE来打包,这里我使用的是eclipse。
创建项目,maven构建,或者创建普通java项目都可以(自行导入依赖包),这里我使用了maven构建项目。
pom.xml
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>2.5.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>2.5.2version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>2.5.2version>
dependency>点击WordCount.java右键Export。
选择JAR file

选择导入目录
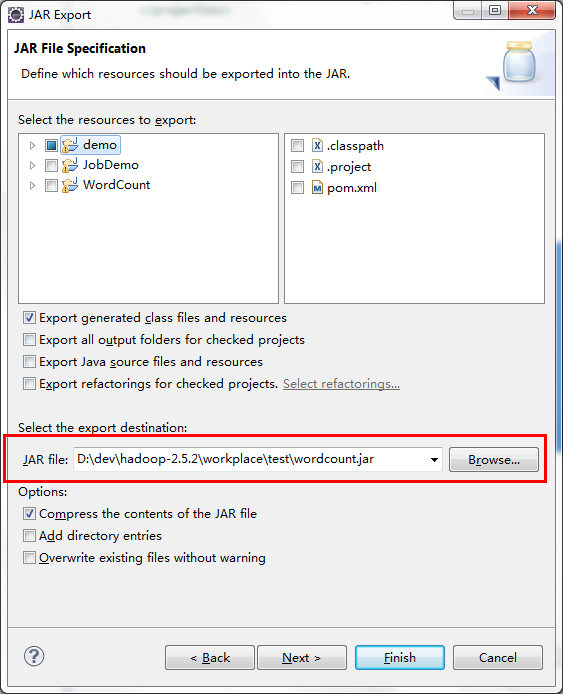
选择程序主入口
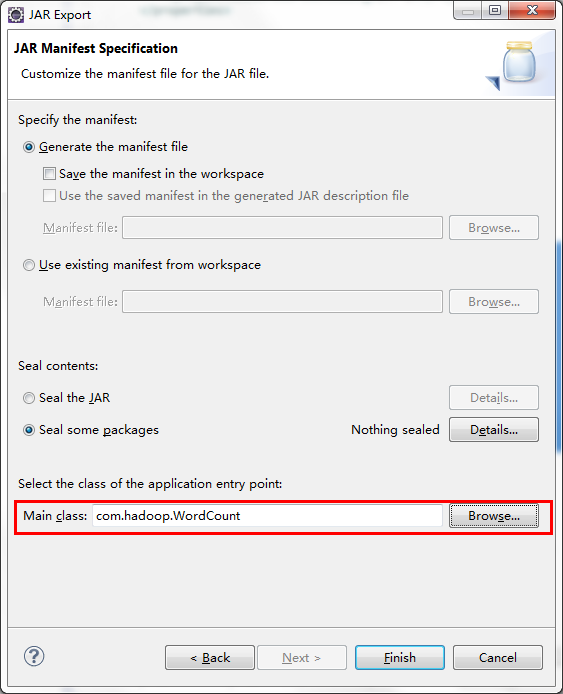
Finish即可。
二、 运行WordCount.jar
上篇文章中,我们已经在hadoop下创建了输入目录/user/wcinput,并上传了2个txt文本文件。
现在只需一个命令即可运行WordCount,cd切换到wordcount.jar包目录,指定输入目录,和输出目录,回车。(output目录,如果不存在,会自动创建,无需先mkdir创建目录)
hadoop jar wordcount.jar hdfs://localhost:9000/user/wcinput hdfs://localhost:9000/user/output 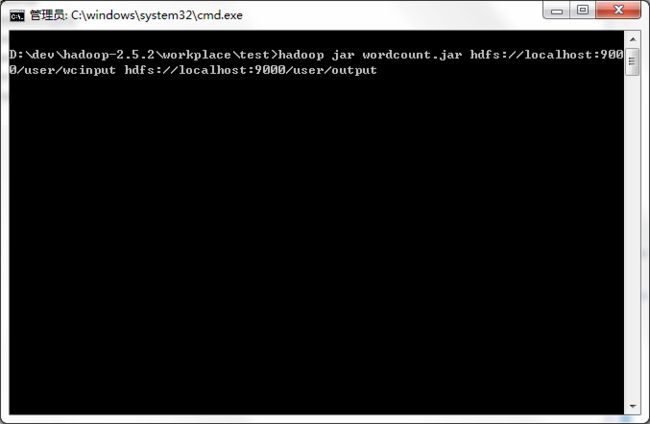
运行完毕后,运行命令:hadoop fs -ls 查看output文件夹里的文件。

其中part-r-0000就是输出结果文件。
运行命令:hadoop fs -cat 打开文件查看,结果如图
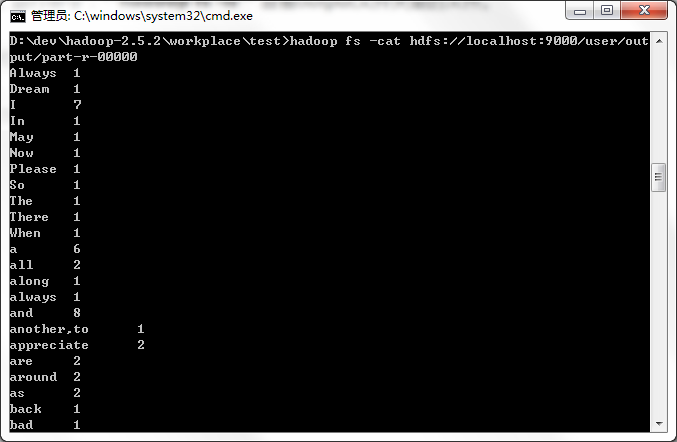
大功告成
第一个hadoop程序跑起来了,赶紧去试试看吧~
下一篇,将会分享如何用eclipse安装hadoop插件来查看Hadoop DFS目录。(这样就不用总是输入命令来查看运行结果啦~提高开发效率。)