Scrapy简单入门整理+小案例
参考官方文档:
http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/commands.html
点击打开链接Scrapy简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便
Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图(绿线是数据流向)
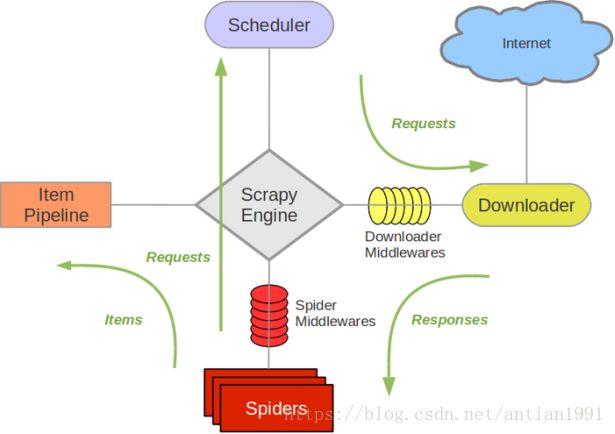
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
开发 Scrapy 爬虫步骤:
- · 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- · 明确目标 (编写items.py):明确你想要抓取的目标
- · 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- · 存储内容 (pipelines.py):设计管道存储爬取内容
创建项目
scrapy startproject recruit
创建爬虫程序
cd recruit
scrapy genspider Position hr.tencent.co自动创建目录及文件

文件说明:
- scrapy.cfg 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
- items.py 设置数据存储模板,用于结构化数据,如:Django的Model
- pipelines 数据处理行为,如:一般结构化的数据持久化
- settings.py 配置文件,如:递归的层数、并发数,延迟下载等
- spiders 爬虫目录,如:创建文件,编写爬虫规则
注意:一般创建爬虫文件时,以网站域名命名
设置数据存储模板

items.py
import scrapy
class PositionItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
position_name = scrapy.Field()
# 职位链接
position_link = scrapy.Field()
# 职位类别
position_type = scrapy.Field()
# 招聘人数
people_num = scrapy.Field()
# 工作地点
work_address = scrapy.Field()
# 发布时间
publish_time = scrapy.Field()
编写爬虫
![]()
# -*- coding: utf-8 -*-
import scrapy
from recruit.items import PositionItem
class PositionSpider(scrapy.Spider):
name = 'Position'
allowed_domains = ['hr.tencent.co']
start_urls = ["https://hr.tencent.com/position.php?&start=0"]
def parse(self, response):
position_lists = response.xpath('//tr[@class="even"] | //tr[@class="odd"]')
for postion in position_lists:
item = PositionItem()
position_name = postion.xpath("./td[1]/a/text()").extract()
position_link = postion.xpath("./td[1]/a/@href").extract()
position_type = postion.xpath("./td[2]/text()").extract()
people_num = postion.xpath("./td[3]/text()").extract()
work_address = postion.xpath("./td[4]/text()").extract()
publish_time = postion.xpath("./td[5]/text()").extract()
item["position_name"] = position_name
item["position_link"] = position_link
item["position_type"] = position_type
item["people_num"] = people_num
item["work_address"] = work_address
item["publish_time"] = publish_time
yield item设置配置文件
settings.py增加如下内容
ITEM_PIPELINES = {
'recruit.pipelines.RecruitPipeline': 300,
}编写数据处理脚本
pipelines.py
import json
class RecruitPipeline(object):
def open_spider(self,spider):
self.file = open("position.json","w",encoding="utf-8")
def process_item(self, item, spider):
dict_item = dict(item)
json_str = json.dumps(dict_item,ensure_ascii=False)+"\n"
self.file.write(json_str)
return item
def close_spider(self,spider):
self.file.close()
编写执行脚本
在和scrapy.cfg同级目录创建文件start.py
start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl Position -o position.xml".split())运行结果:

以上是抓取第一页的方法 抓取全部的方法是一样的 只要分析好每一页的url的区别就好,下面是抓取全部的招聘信息

可以看到一共3720个职位
分析url得出每加10就是下一页
第一页:https://hr.tencent.com/position.php?&start=0
第二页:https://hr.tencent.com/position.php?&start=10
第三页:https://hr.tencent.com/position.php?&start=20
我们在Position.py中定义变量 offset
下面是是Position.py中的代码:
# -*- coding: utf-8 -*-
import scrapy
from recruit.items import PositionItem
class PositionSpider(scrapy.Spider):
name = 'Position'
allowed_domains = ['hr.tencent.com']
# 偏移量
offset = 0
url = "https://hr.tencent.com/position.php?&start="
start_urls = [url + str(offset) + "#a", ]
def parse(self, response):
print("response.url==", response.url)
postion_lists = response.xpath('//tr[@class="even"]|//tr[@class="odd"]')
for postion in postion_lists:
item = PositionItem()
position_name = postion.xpath('./td[1]/a/text()').extract()[0]
position_link = postion.xpath('./td[1]/a/@href').extract()[0]
position_type = postion.xpath('./td[2]/text()').get()
people_num = postion.xpath('./td[3]/text()').extract()[0]
work_address = postion.xpath('./td[4]/text()').extract()[0]
publish_time = postion.xpath('./td[5]/text()').extract()[0]
item["position_name"] = position_name
item["position_link"] = position_link
item["position_type"] = position_type
item["people_num"] = people_num
item["work_address"] = work_address
item["publish_time"] = publish_time
yield item
# 请求下一页
total_page = response.xpath('//div[@class="left"]/span/text()').extract()[0]
print("total_page===", total_page)
if self.offset < int(total_page):
# 每一页,相差10
self.offset += 10
# 每一页的请求链接
new_url = self.url + str(self.offset) + "#a"
# 往scrapy引擎添加请求
yield scrapy.Request(new_url, callback=self.parse)pipelinepipelines.py
import json
class RecruitPipeline(object):
def open_spider(self,spider):
self.file_name = open(spider.name+"_position.xml","w")
def process_item(self, item, spider):
python_dict = dict(item)
json_text = json.dumps(python_dict, ensure_ascii=False) + "\n"
self.file_name.write(json_text)
return item
def close_spider(self,spider):
self.file_name.close()
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for recruit project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'recruit'
SPIDER_MODULES = ['recruit.spiders']
NEWSPIDER_MODULE = 'recruit.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'recruit (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'User-Agent': 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/6.0)',
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'recruit.middlewares.RecruitSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'recruit.middlewares.RecruitDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'recruit.pipelines.RecruitPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'运行得到的结果:
一共3720个文件