TiDB 官方设计文档翻译(一)
TiDB是新兴的NEWSQL数据库,由国内的PINGCAP团队研发。
有关于TiDB的架构、部署和运维,官方有中文的文档,链接是:
https://github.com/pingcap/docs-cn
官方还有另外一份文档,讲的是TiDB和TiKV的设计思想和技术细节,个人很喜欢,但是用英文写的。这里提供该文档的翻译。
这个系列共三篇译文:
TiDB 官方设计文档翻译(一)
TiDB 官方设计文档翻译(二)
TiDB 官方设计文档翻译(三)
原文:
https://pingcap.github.io/blog/2016/10/17/how-we-build-tidb/
1 什么是TiDB
TiDB是一个分布式SQL数据库,灵感来自Google的F1和Spanner。TiDB汲取了传统RDBMS(译者注:关系型数据库)和NoSQL的优点。
- 水平伸缩——TiDB 可随着你的业务增长而伸缩,只需要通过增加更多的机器,就可以满足业务增长;
- 异步的 schema 调整——根据需求队TiDB scheme 进行调整,添加列和索引不会影响进行中的操作;
- 一致性的分布式事务——可以把 TiDB 当作一个单机的 RDBMS,事务可以横跨多个服务器之间,无需担心一致性问题。TiDB 让你的应用代码简单可靠;
- 与MySQL协议兼容——你可以像使用 MySQL 一样来使用 TiDB,也就是说,可以在应用中使用 TiDB 来替换 MySQL ,而绝大多情况下无需修改一行代码;
- 使用Go语言——尽情享受Go带来的便利吧。Go语言简单容易上手,而且有极高的运行效率,嵌入代码库也十分方便;
- 建立在TiKV基础之上的NewSQL——有关于TiKV,后面的翻译中会详细介绍
- 多存储引擎支持——你可以在 TiDB 中使用你熟知的存储引擎,单机模式下支持大多数引擎,包括 goleveldb, LevelDB, RocksDB, LMDB, BoltDB ,未来还会支持更多
2 为什么要重新做一个数据库
在开始介绍之前,我们回到原点,问自己一个问题:为什么要重新做一个数据库。我们都知道,已经有很多成熟的数据库了,例如传统的关系型数据库和NoSQL。为什么我们不采用这些方案?
- 关系型数据库,例如MySQL,Oracle,PostgreSQL等,伸缩性很差。尽管我们可以有分片的解决方案,例如Youtube的vitness,MySQL代理,但是他们都不能满足分布式事务和跨节点的连接(join)。
- NoSQL,例如HBase,Mongo DB和Cassandra,伸缩性不错,但是不支持SQL和一致性事务。
- NewSQL,代表是Google Spanner和F1,和NoSQL系统一样具有良好的伸缩性,也保留了ACID事务。这才是我们所需要的。受到Google Spanner和F1的启发,我们决定做一款开源的NewSQL数据库。
3 做怎样的数据库
我们要做的NewSQL数据库,必须有下面的功能:
- 首先,支持SQL。我们用SQL很多年了,而且许多应用都是基于SQL的,弃之可惜,代价也太大;
- 第二,必须有良好的伸缩性。只需要加入更多的机器,就可以增加性能或者实现负载均衡;
- 第三,支持ACID事务,这是传统的关系型数据库最大的优点之一。有了强一致性保证,开发者可以用更少的代码保证逻辑的正确;
- 最后,满足高可用,机器故障,甚至是整个数据中心宕机,都应该可以自动恢复。
总之,我们要做一个分布式、一致性、可伸缩的SQL数据库,取名为TiDB。
4 如何设计?
现在我们弄清了要做一个怎样的数据库,下一步是如何设计、开发和测试。
接下来一节中,首先介绍如何设计TiDB,包括设计原则、架构和决策。
4.1 设计原则
在开始设计之前,必须清楚一些设计原则:
- TiDB必须是面向用户的。不能丢失数据,系统可以从机器甚至整个数据中心的宕机中自动恢复;易于使用;跨平台,可以运行在任何环境中,无论是在本地,云或者容器中;作为开源项目,我们希望有一个活跃的大社区,来一起讨论、参与和协作贡献。
- 必须易于维护,因此我们选择了低耦合。这个数据库应该高度分层,包括SQL层和key-value层。如果SQL层出现了bug,只需要更新SQL层即可。
- 替代方案——虽然我们的项目灵感来自于Google Spanner和F1,但并不完全相同。设计TiDB和TiKV过程中,我们选择不同技术的时候,有自己的实践和决策。
4.1.1 容灾
首要的设计原则是建立一个数据不会丢失的数据库。 为了确保数据的安全,我们发现多个副本是不够的,我们仍然需要在SQL层和key-value层维护Binlog(二进制日志)。 当然,我们必须确保有一个备份,以防整个集群崩溃。
4.1.2 易于使用
第二个设计原则是关于可用性。 经过多年在不同的解决方案之间的权衡,我们完全意识到用户的痛点。 因此,当我们设计一个数据库时,我们将使它易于使用,并且应该没有令人头疼的分片键,没有分区,没有明确的手工本地索引或全局索引,并使让系统伸缩对用户完全透明。
4.1.3 跨平台
这个数据库还需要跨平台。 数据库可以在本地设备上运行。 下图展示了TiDB运行在有20个节点的树莓派集群。

它还可以支持流行的容器,如Docker。 我们正在与Kubernetes合作。 当然,它也可以在任何云平台上运行,无论是公共的,私有的还是融合的。
4.1.4 社区和软件生态
下一个设计原则是关于社区和软件生态。 我们想站在巨人的肩膀上,而不是创造出全新的令人陌生的产品。 TiDB支持MySQL协议,与大多数MySQL驱动程序(ODBC,JDBC)、SQL语法、MySQL客户端、ORM、下列MySQL管理和bench工具兼容。
- etcd——etcd是一个伟大的项目。 在我们的键值存储TiKV中(后面会详细介绍),我们一直与etcd团队密切合作。 我们共享Raft实现,并且互相进行Raft模块代码审查;
- RocksDB——RocksDB也是一个伟大的项目。 成熟,快速,可调谐,并广泛应用于大规模的生产环境,尤其在Facebook。 TiKV使用RocksDB作为本地存储。 当我们在系统中测试时,发现了RocksDB的一些bug。 RocksDB团队后来很快地修复了;
- Namazu——几个月前,我们需要一个工具来模拟速度慢而且不稳定的磁盘,团队成员发现了Namazu。 但是那时候,Namazu不支持hooking fsync。 当团队成员将此请求提交给Namazu的团队时,他们立即回复并在短短几个小时内实现该功能,他们也非常愿意实现其他功能。 我们对他们的反馈速度和效率印象深刻;
- Rust社区——Rust社区是惊人的。 除了使用Rust的良好开发经验之外,我们还在Rust中构建了Prometheus驱动程序以收集指标。我们很高兴成为这个大家庭的一部分。 非常感谢Rust团队,gRPC,Prometheus和Grafana。
- spark连接器。我们在TiDB中使用Spark连接器。 TiDB非常适合小型或中型查询,Spark更适合具有大量数据的复杂查询。 我们相信我们也可以从Spark社区学到很多,当然我们希望尽可能多地贡献。
因此,总体来说,我们希望成为大型开源社区的一员,并愿意参与,贡献和合作,一起构建伟大的开源产品。
4.2 低耦合 - 逻辑架构
下图显示了数据库的逻辑架构。
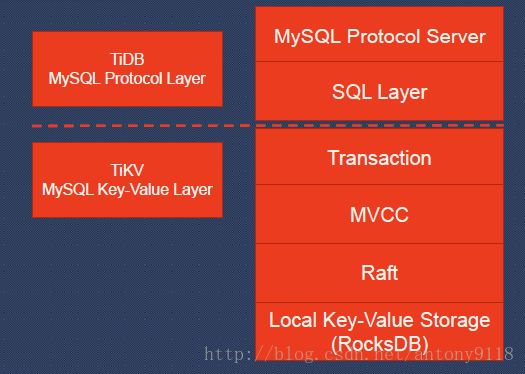
正如我前面提到的设计原则,我们采用松耦合方法。 从图中我们可以看出TiDB是高度分层的。 我们有TiDB作为MySQL服务器,TiKV作为分布式Key-Value层。 TiDB内部,分为MySQL Server层和SQL层。 在TiKV内部,分为事务,MVCC,Raft和本地键值存储(RocksDB)。
对于TiKV,我们使用Raft协议来保证数据一致性和水平伸缩性。 Raft是一个一致性算法,在容错和性能可以媲美Paxos。 我们从etcd移植了广泛使用的实现方法,容易测试并且高度稳定。 稍后将介绍技术细节。
从架构中,你也能看到,并没有分布式文件系统。我们使用RocksDB作为本地存储。
4.3 替代方案
在接下来的几节中,我将讨论与Spanner和F1相比,使用替代技术的设计决策,以及这些替代方案的利弊。
4.3.1 原子钟/ GPS时钟 VS TimeStamp Allocator
如果阅读过Spanner论文,你可能知道Spanner有TrueTime API,它使用原子钟和GPS接收器来保持不同数据中心之间的时间一致。
我们选择的第一种替代技术是用TimeStamp Allocator替换TrueTime API。 毫无疑问,实时性在分布式系统中至关重要。 但是我们能得到实时吗? 时钟漂移怎么办?
可悲的是,即使我们使用GPS或原子钟,因为时钟漂移,也不能得到完全准确的时间,
在TiDB中,我们没有使用原子钟和GPS时钟。 我们使用Percolator(2006年Google发布的一篇文章)中引入的Timestamp Allocator。
使用Timestamp Allocator的优点是易于实现,并且不依赖于任何硬件。 缺点在于,如果存在多个数据中心,特别是如果这些数据中心跨地区分布,延迟会很高。
4.3.2 分布式文件系统 VS RocksDB
Spanner使用Colossus文件系统作为其分布式文件系统,Colossus是Google文件系统(GFS)的继承者。 但是在TiKV中,我们不依赖于任何分布式文件系统。 我们使用RocksDB。 RocksDB是一个可嵌入的快速持久化键值存储。 RocksDB的最大优点是其针对服务器工作负载的卓越性能。 很容易调整读、写和放大空间。 非常简单、快速和容易调整。 但是,与Kubernetes协同工作并不容易。
4.3.3 Paxos VS Raft
下一个选择是使用Raft一致性算法代替的Paxos。Raft的主要特点是:强有力的领导者,领导者选举和成员的变化。 我们从etcd移植了Raft实现方法。 优点是易于理解和实现,广泛使用并且便于测试。 至于缺点,目前还没发现。
4.3.4 C ++ VS Go&Rust
至于编程语言,TiDB使用Go语言,TiKV使用Rust。 我们选择了Go,因为它对快速开发和并发非常有利,而Rust可以实现高质量和性能保障。 至于缺点,没有那么多的第三方库。
上文介绍了设计TiDB的过程中,使用替代技术的原则、架构和设计决策。 下一步是开发TiDB。
说明
如有转载,请注明出处:
http://blog.csdn.net/antony9118/article/details/60467256