linux文件描述符分配实现详解(基于ARM处理器)
1、linux内核文件相关结构体
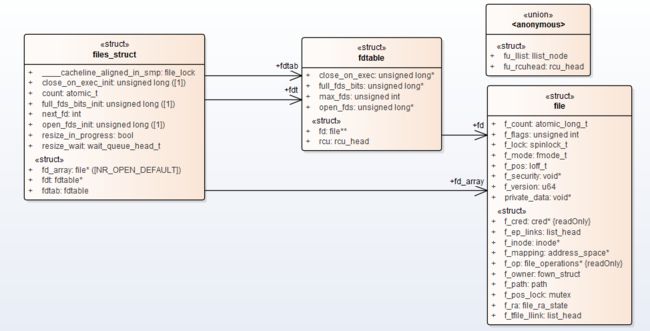
1.1、files_struct
files_struct: 进程打开文件的表结构,next_fd表示下一个可用进程描述符,并不一定真正可用,假如0-10描述符都被使用了,中间师傅3文件描述符,再打开文件,此时将使用3作为新的文件描述符,内核认为next_fd为4,next_fd只是表示可能可用的下一个文件描述符,下次查找可用描述符时从next_fd开始查找,而不需要从头开始找。
1.2、fdtable
fdtable: 真正记录哪些文件描述符被使用了,哪些是空闲的,实际是一个文件描述符位图,每1bit表示了一个文件描述符,例如bit 0为1表示描述符1被使用了,bit 3为0表示描述符3可以使用。fd数组记录了file信息,数组下标就是文件描述符的值。细节后面再介绍。
1.3、file
2、linux内核open系统调用
2.1、SyS_open函数调用栈
#0 __alloc_fd (files=0x87822000, start=32, end=1024, flags=2) at fs/file.c:512
#1 0x8010b0d8 in get_unused_fd_flags (flags=
#2 0x800eeaf0 in do_sys_open (dfd=-100, filename=
#3 0x800eebcc in SYSC_open (mode=
#4 SyS_open (filename=
2.2、fdtable介绍
如下简要示意了下文件描述符位图结构

full_fds_bits每1bit代表的是一个32位的数组,也就是说代表了32位描述符;上面只画了32位,内核中的位图是一片连续的内存空间,最低bit表示数值0,下一比特表示1,依次类推;full_fds_bits每1bit只有0和1两个值,0表示有该组有可用的文件描述符,1表示没有可用的文件描述符,例如位图bit 0代表的是0-31共32个文件描述符,bit1代表的是32-63共32个文件描述符,假如0-31文件描述符都被使用了,那么位图bit0则应该标记为1,如果32-63中有一个未使用的文件描述符,则bit1被标记为0,当32-63中的所有文件描述符都被使用的时候,才标记为1。
open_fds是真正的文件描述符位图,也是一片连续的内存空间,每bit代表一个文件描述符(注意full_fds_bits每bit代表的是一组文件描述符),标记为0的bit表示该文件描述符没用被使用,标记为1的比特表示该文件描述符已经被使用,例如从内存其实地址开始计算,第35比特为1,则表示文件描述符35已经被使用了。
2.3、next zero bit查找函数解释
以下是ARM汇编语言实现,只介绍一部分,其他部分原理是一样的(介绍时是以文件描述符为例的,对文件描述符组查找也是一样的,都是查找0bit的偏移地址)。
ENTRY(_find_next_zero_bit_le)
teq r1, #0 // r1 = maxbit,如果maxbit为0,是不需要比较的
beq 3b
ands ip, r2, #7 // 判断offset低3位是否为0,查找0bit位的时候是以8位对齐查找的,3位二进制,如果offset是8的整数倍,那么低3位应该是0,跳转到1b处查找(从byte的第0位开始查找)
beq 1b @ If new byte, goto old routine
ARM( ldrb r3, [r0, r2, lsr #3] ) // offset不是8的整数倍,那么先从offset % 8开始查找,假如offset = 18 = 15 + 3,0-15 bit正好是2个字节,我们只需要从第3个字节的第3位开始查找即可,因为计算机读的时候是以最小单位字节读取的,所以我们不能直接读取第18bit,而是要读取16-23bit,相当与多读了3bit的值而已;"lsr, #3"实际是offset/8,获取的是bit对应的byte,例如18/8 = 2,表示18bit在内存的第2个字节里面(字节起始索引为0)
THUMB( lsr r3, r2, #3 )
THUMB( ldrb r3, [r0, r3] )
eor r3, r3, #0xff @ now looking for a 1 bit // 8bit文件描述符进行异或操作,实际效果是各位取反,就是将0变1、1变0,对0的查找变为对1的查找,便于代码的编写
movs r3, r3, lsr ip @ shift off unused bits // ip是offset % 8,右移文件描述符,就是将不需要比较的位移除(该函数是从指定位置开始找0bit位,但是并不是说指定位置之前都是1)
bne .L_found // 结果不为0,即有bit的值为1(前面已经将0取反为1了),找到了为1的bit则跳转到.L_found
orr r2, r2, #7 @ if zero, then no bits here
add r2, r2, #1 @ align bit pointer
b 2b @ loop for next bit // 没有找到,继续查找,后续都是8个bit的查找
ENDPROC(_find_next_zero_bit_le)
......
/*
* One or more bits in the LSB of r3 are assumed to be set.
*/
.L_found:
#if __LINUX_ARM_ARCH__ >= 5
rsb r0, r3, #0
and r3, r3, r0
clz r3, r3
rsb r3, r3, #31
add r0, r2, r3
#else
tst r3, #0x0f // r3是前面取的8bit文件描述符,r3 & 0x0f用来判断低4位是否有1,即可用描述符是否在r3的低4位里面
addeq r2, r2, #4 // 上一条指令结果为0,表示r3低4位没有可用的文件描述符,offset = offset + 4,在第4位之后继续查找
movne r3, r3, lsl #4 // tst指令执行结果不为0,表示r3低4位有1(即有可用文件描述符),将r3左移4位,移位后低4位就都为0了,注意这里offset没有变化,执行者条指令之后,可用描述符都集中的r3的高4位了,只要从第4位开始查找为1的bit就可以了。
// 从第4位开始查找
tst r3, #0x30 // 判断第4或者5位是否为1
addeq r2, r2, #2 // 第4、5位都不为1,则为1的bit位必定在第6或7位,偏移先加2,offset = offset + 2
movne r3, r3, lsl #2 // 第4或者第5位有1,则先左移2两位,这步的offset没有修改
// 从第6位开始查找
tst r3, #0x40 // 判断第6位是否为0
addeq r2, r2, #1 // 第6位为0,则为1的bit位一定在第7位,offset = offset + 1
mov r0, r2 // 为1(之前为0的bit取反得到的)的bit偏移位置,即可用的文件描述符,r0是函数的返回值
#endif
cmp r1, r0 @ Clamp to maxbit
movlo r0, r1
ret lr
注释:
前面的说明有些绕口,这里举个简单的例子再解释下;例如r3的第0-3bit都为0,第7bit为1,offset起始值为0,需要查找到低7bit,先让offset = offset + 4,然后从第4位找为1的第7bit位,此时第4到第7位的偏移是3,我们只需要让offset再加3即可offset = offset + 3 = 4 + 3 = 7,也就是我们每次查找的起始位置变了;再假如r3的第3bit为1,offset起始值为0,将r3左移4位,此时第3bit将变为第7bit,但是offset还是为0,接着我们从第4bit开始查找为1的bit,第4到第7bit的偏移为3,offset = offset + 3 = 0 + 3 = 3,得到的结果是正确的。
总结一句话就是,移位操作是为了使后面代码查找时的起点都是一样的。
2.4、__alloc_fd
文件描述符分配,该函数仅分配了一个可用的文件描述符,文件描述符与文件操作函数的关联不在这里处理。
/*
* allocate a file descriptor, mark it busy.
*/
int __alloc_fd(struct files_struct *files,
unsigned start, unsigned end, unsigned flags)
{
unsigned int fd;
int error;
struct fdtable *fdt;
spin_lock(&files->file_lock);
repeat:
fdt = files_fdtable(files); // 获取文件描述符表
fd = start;
if (fd < files->next_fd)
fd = files->next_fd; // 默认传递的起始查找文件描述不一定有效,不在有效范围时使用next_fd作为起始查找值
if (fd < fdt->max_fds)
fd = find_next_fd(fdt, fd); // 起始查找文件描述符小于最大文件描述符,从当前文件描述符表中查找可用的文件描述符(max_fds表示已分配的文件描述符的数量,也就是位图总的bit数,后面会看到文件描述符表扩展的代码,在此先介绍下)
/*
* N.B. For clone tasks sharing a files structure, this test
* will limit the total number of files that can be opened.
*/
error = -EMFILE;
if (fd >= end) // 可用文件描述符超出函数参数传递的最大值,返回-EMFILE,这是个标准错误码errno
goto out;
error = expand_files(files, fd); // 扩展文件描述符,当fd<=max_fds时,fd在文件描述符位图可表示的范围,例如我们申请的文件描述符大小为1byte,那么文件描述符最大只能表示7,当fd大于7的时候,我们就没有对应的bit位可以标记了,因此需要重新扩展,申请更大的内存,申请的新的文件描述符表,让后将旧的值拷贝到新的文件描述符表中。只有fd>max_fds才会真正扩展。
if (error < 0)
goto out;
/*
* If we needed to expand the fs array we
* might have blocked - try again.
*/
if (error)
goto repeat;
if (start <= files->next_fd)
files->next_fd = fd + 1;
__set_open_fd(fd, fdt); // 在文件描述符表中标记fd已经被打开,对应bit位设置为1,同时更新fd所在文件描述符组的值,因为fd改变后,可能导致该组的文件描述符都被使用了,需要将该组标记为1,下次查找可用文件描述符时就会跳过该组,避免不必要的查找。
if (flags & O_CLOEXEC)
__set_close_on_exec(fd, fdt); // 打开时带有O_CLOEXEC标志,设置close_on_exec文件描述符位打开状态,大致意思是exec创建进程时会覆盖父进程,但是子进程继承了父进程的文件描述符,对于exec创建的新进程,继承的文件描述符已经没有任何意义了,创建之后需要关闭这些无意义的文件描述符,而这些文件描述符就记录在close_on_exec里面。
else
__clear_close_on_exec(fd, fdt);
error = fd;
#if 1
/* Sanity check */
if (rcu_access_pointer(fdt->fd[fd]) != NULL) {
printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);
rcu_assign_pointer(fdt->fd[fd], NULL); // 文件操作函数设置为NULL,此时只分配了文件描述符,还没有真正关联到具体的文件操作函数
}
#endif
out:
spin_unlock(&files->file_lock);
return error;
}
2.5、find_next_fd
查找下一个可用的文件描述符
static unsigned long find_next_fd(struct fdtable *fdt, unsigned long start)
{
unsigned long maxfd = fdt->max_fds; // 文件描述符表最大文件描述符
unsigned long maxbit = maxfd / BITS_PER_LONG; // 最大文件描述符组(一组文件描述符包含32个文件描述符,例如0-31为一组)
unsigned long bitbit = start / BITS_PER_LONG; // 起始查找文件描述符所在组(32个文件描述符为一组,我们要从文件描述符33开始查找,可知,33文件描述符在33/32 = 1组,因此我们从第1组开始查找即可)
bitbit = find_next_zero_bit(fdt->full_fds_bits, maxbit, bitbit) * BITS_PER_LONG; // 查找下一个可用文件描述符组,结果乘以BITS_PER_LONG,即得到该组起始文件描述符。
if (bitbit > maxfd)
return maxfd; // 可用文件描述符起始值大于最大文件描述符,直接返回最大文件描述符,表示文件描述符需要扩展。
if (bitbit > start)
start = bitbit; // 可用起始文件描述符大于参数传递的起始查找文件描述符,将开始查找的值从真正有效的值开始,避免做无效的查找。
return find_next_zero_bit(fdt->open_fds, maxfd, start); // 从文件描述符表中查找可用的文件描述符(之前是查找可用组,以32位为大小查找,提高效率,这次的查找范围缩小的组内了,即最多只需要查找32次了,这有点像找房间一样,先找楼层,再找房间,而不需要每层楼每间房间都找一遍;查找函数在前面章节已经介绍了)。
}
2.6、expand_files
文件描述表大小是根据需要动态增加的,不会一开始就申请很大空间,这样会浪费内存,当文件描述符表不够大时才重新分配内存空间。
/*
* Expand files.
* This function will expand the file structures, if the requested size exceeds
* the current capacity and there is room for expansion.
* Return <0 error code on error; 0 when nothing done; 1 when files were
* expanded and execution may have blocked.
* The files->file_lock should be held on entry, and will be held on exit.
*/
static int expand_files(struct files_struct *files, int nr)
__releases(files->file_lock)
__acquires(files->file_lock)
{
struct fdtable *fdt;
int expanded = 0;
repeat:
fdt = files_fdtable(files); // 获取文件描述符表
/* Do we need to expand? */
if (nr < fdt->max_fds) // 新的文件描述符
return expanded;
/* Can we expand? */
if (nr >= sysctl_nr_open) // 大于限制的最大文件描述符,返回错误,不运行操作系统设置的最大文件描述符
return -EMFILE;
if (unlikely(files->resize_in_progress)) { // 同一进程下的多个线程是共用一个文件描述符的,需要互斥访问
spin_unlock(&files->file_lock);
expanded = 1;
wait_event(files->resize_wait, !files->resize_in_progress);
spin_lock(&files->file_lock);
goto repeat;
}
/* All good, so we try */
files->resize_in_progress = true;
expanded = expand_fdtable(files, nr); // 扩展文件描述符表
files->resize_in_progress = false;
wake_up_all(&files->resize_wait);
return expanded;
}
2.7、expand_fdtable
/*
* Expand the file descriptor table.
* This function will allocate a new fdtable and both fd array and fdset, of
* the given size.
* Return <0 error code on error; 1 on successful completion.
* The files->file_lock should be held on entry, and will be held on exit.
*/
static int expand_fdtable(struct files_struct *files, int nr)
__releases(files->file_lock)
__acquires(files->file_lock)
{
struct fdtable *new_fdt, *cur_fdt;
spin_unlock(&files->file_lock);
new_fdt = alloc_fdtable(nr); // 申请足以表示nr文件描述符的内存空间
/* make sure all __fd_install() have seen resize_in_progress
* or have finished their rcu_read_lock_sched() section.
*/
if (atomic_read(&files->count) > 1)
synchronize_sched();
spin_lock(&files->file_lock);
if (!new_fdt)
return -ENOMEM;
/*
* extremely unlikely race - sysctl_nr_open decreased between the check in
* caller and alloc_fdtable(). Cheaper to catch it here...
*/
if (unlikely(new_fdt->max_fds <= nr)) {
__free_fdtable(new_fdt);
return -EMFILE;
}
cur_fdt = files_fdtable(files);
BUG_ON(nr < cur_fdt->max_fds);
copy_fdtable(new_fdt, cur_fdt); // 文件描述符信息拷贝
rcu_assign_pointer(files->fdt, new_fdt); // 文件描述符表指针更新
if (cur_fdt != &files->fdtab)
call_rcu(&cur_fdt->rcu, free_fdtable_rcu);
/* coupled with smp_rmb() in __fd_install() */
smp_wmb();
return 1;
}
2.8、alloc_fdtable
static struct fdtable * alloc_fdtable(unsigned int nr)
{
struct fdtable *fdt;
void *data;
/*
* Figure out how many fds we actually want to support in this fdtable.
* Allocation steps are keyed to the size of the fdarray, since it
* grows far faster than any of the other dynamic data. We try to fit
* the fdarray into comfortable page-tuned chunks: starting at 1024B
* and growing in powers of two from there on.
*/
nr /= (1024 / sizeof(struct file *));
nr = roundup_pow_of_two(nr + 1);
nr *= (1024 / sizeof(struct file *)); // nr大小不确定,这之前的步骤就是为了调整nr大小,具体含义看英文说明
/*
* Note that this can drive nr *below* what we had passed if sysctl_nr_open
* had been set lower between the check in expand_files() and here. Deal
* with that in caller, it's cheaper that way.
*
* We make sure that nr remains a multiple of BITS_PER_LONG - otherwise
* bitmaps handling below becomes unpleasant, to put it mildly...
*/
if (unlikely(nr > sysctl_nr_open)) // nr大于系统设置的文件描述符上限,需要调整不超过系统设置的上限
nr = ((sysctl_nr_open - 1) | (BITS_PER_LONG - 1)) + 1;
fdt = kmalloc(sizeof(struct fdtable), GFP_KERNEL_ACCOUNT); // 申请内存空间
if (!fdt)
goto out;
fdt->max_fds = nr; // 最大文件描述符
data = alloc_fdmem(nr * sizeof(struct file *));
if (!data)
goto out_fdt;
fdt->fd = data;
data = alloc_fdmem(max_t(size_t,
2 * nr / BITS_PER_BYTE + BITBIT_SIZE(nr), L1_CACHE_BYTES));
if (!data)
goto out_arr;
fdt->open_fds = data; // 文件描述符位图(每一位代表一个文件描述符)
data += nr / BITS_PER_BYTE;
fdt->close_on_exec = data; // close_on_exec文件描述符位图(用于在exec创建替换父进程时,确定哪些文件描述符需要关闭)
data += nr / BITS_PER_BYTE;
fdt->full_fds_bits = data; // 文件描述符组位图(每一位代表一个文件描述符组,一组文件描述符有32个文件描述符,当该组文件描述符都被使用了的时候,将该组对应的bit位设置为1,表示该组已经没有可用文件描述符了)
return fdt;
out_arr:
kvfree(fdt->fd);
out_fdt:
kfree(fdt);
out:
return NULL;
}
2.9、__put_unused_fd
为了加速文件描述符查找,文件描述符分配/释放的时候都会更新next_fd,用来标志下一个可能可用的文件描述符,例如:我们刚申请到了文件描述符3,那么就代表3之前的文件描述符都被使用了(分配文件描述符是从小到大分配的),下一个可能可用的文件描述符应该大于等于4,当然文件描述符4有可能已经被使用了,但是我们不必查找文件描述符4之前的文件描述符,这样就提高了效率。另外,例如:0-9文件描述符都被使用了,next_fd=10,现在close文件描述符3,3<10,因此我们更新next_fd为3,这样我们就能保证next_fd始终是最小可能可用的文件描述符,不会造成查找时跳过可用文件描述符的情况。
static void __put_unused_fd(struct files_struct *files, unsigned int fd)
{
struct fdtable *fdt = files_fdtable(files);
__clear_open_fd(fd, fdt); // 清除文件描述符使用标记,同时清除该文件描述符所在组的标记,释放了一个文件描述符,该组至少有一个文件描述符可使用
if (fd < files->next_fd)
files->next_fd = fd; // 更新下一个可用的文件描述符(打开文件时的更新请查看前面章节)
}
3、文件描述符关联
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int fd = build_open_flags(flags, mode, &op);
struct filename *tmp;
if (fd)
return fd;
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
fd = get_unused_fd_flags(flags); // 获取未使用的文件描述符
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op); // 打开文件,获取file结构体,文件操作的函数指针等,在此暂不做解释,可以参考之前pipe管道的文章,自己分析下pipe操作函数是怎么获取到的,pipe操作比物理文件系统操作简单了很多,分析起来更容易。
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f); // 文件描述符与文件结构体(真正的文件操作函数等)关联,实际就是设置fd对应的数组的值为f,在此不做详细解释。
}
}
putname(tmp);
return fd;
}